JavaSE学习笔记
JavaSE基础【2022.7.2】
DAY01
编译型和解释型的概述?
编译型:整体翻译,将源文件编译成字节码文件。
- 优点:阅读效率高;
- 缺点:需要等待;
翻译型:逐行翻译,将字节码文件转换成对应平台的机器语言。
- 优点:无需等待,直接阅读;
- 缺点:阅读效率低;
C++属于“编译型”语言,JavaScript属于“解释型”语言,Java属于“编译型+解释型”语言【一次编译,到处运行】。
跨平台需要满足的条件?
- 各平台只识别机器语言;
- 各平台的机器指令不同;
注意:源文件编译之后,如果得到的“二进制文件”能直接在平台上运行,则我们就称之为“机器码”;
源文件编译之后,如果得到的“二进制文件”不能直接在平台上运行,则我们就称之为“字节码”。
常见的DOS命令?
切换盘符:
- D: 或 d:
切换目录:
- cd 文件夹名 –> 进入某个目录
- cd 路径 –> 进入某个目录
eg: cd D:\course\01_JavaSE\document 或 cd course\01_JavaSE\document
注意:通过”cd”命令来切换目录的时候,切记不要跨盘符切换。
cd .. –> 返回上一级目录
注意:此处”..”指的就是“上一级目录”。
cd / 或 cd \ –> 返回根目录
查看目录中的所有内容
- dir –> 查看当前目录中的所有文件和文件夹
注意:此处的”.” 代表的是当前所在目录,”..”代表的是上一级目录
常见的辅助命令
cls –> 清屏操作
键盘上下键 –> 查看上一条或下一条已经执行过的命令
tab键 –> 文件名或文件夹名自动补全
exit –> 关闭DOS命令窗口(退出)
操作文件夹的命令
- md –> 新建文件夹
- rd –> 删除文件夹
操作文件的命令
- 文件名或程序名
- copy 要复制文件的路径 目的路径
- del 文件名 –> 删除文件
常见的辅助命令
- help –> 帮助命令(显示常见的DOS命令及其作用)
注意:DOS命令不区分大小写,但是文件名或文件夹名需要区分大小写!
- ipconfig –> 查看当前电脑的ip地址
DAY02
PATH环境变量配置
第一个程序的步骤:
- 编辑阶段
- 新建一个Java源文件,然后在源文件中编辑代码。
- 编译阶段
- 把源文件编译为字节码文件,从而解决各平台只识别机器语言的问题。
- 实现:在源文件所在的目录中,我们使用javac.exe来实现编译操作,例如:javac HelloWorld.java
- 执行阶段
- 把字节码文件在虚拟机中解释执行,从而解决了各平台机器指令不一样的问题。
- 实现:在字节码文件所在的目录中,我们使用java.exe来实现解释执行的操作,例如:java HelloWorld
如何取消隐藏已知文件类型的后缀?
- 方式一:在文件所在目录中,我们选中“查看”,然后再勾选“文件扩展名”;
- 方式二:打开控制面板,选中“外观和个性化”,–>“文件资源管理器选项”,–>“查看”,最后取消勾选“隐藏已知文件类型的扩展名”。
处理使用Notepad++出现的乱码问题?
原因:DOS命令采用的是ANSI编吗,而Notepad++采用的是UTF-8编码,则编码和编码采用的《编码表》不一致,那么就会出现乱码问题。
解决:把Notepad++的编码设置为ANSI编码表即可。
需求:新建一个源文件,然后通过Notepad++打开该源文件,要求打开的源文件默认就是ANSI编码,如何实现?
实现:在导航栏位置选中“设置”,然后选中“首选项”,–>“新建”,然后设置编码为“ANSI”并设置默认语言为“java”,最后点击“关闭”按钮。
经典错误:“错误:编码GBK的不可映射字符” –> 编码问题,编码和解码没有使用同一个编码表。
编辑阶段的整体注意点
见名知意、注意缩进、成对编程;
严格区分大小写,英文大写字母与小写字母意义不一样;
都是英文标点符号;
–> 经典错误:”非法字符”:’\uff09’ –> 使用了中文的标点符号;
main方法写法固定,是程序的入口,能被虚拟机识别并执行。
关于定义类的注意点?
使用public修饰的类,该类的名字必须和源文件名字保持一致,否则就会编译错误;
在源文件中,我们可以使用class来定义任意多个类,编译后就会生成任意多个字节码文件。
–> 编译后,没有类都会生成一个字节码文件,并且字节码文件名字就是类名。
在源文件中,我们可以定义多个类,但是最多只能有一个类使用public修饰(0或1)。
DOS下编译解释【了解】
问题:想要在任意目录中,去编译指定目录中的源文件,如何实现?
解决:java D:\course\JavaProjects\01_JavaSE\day02\HelloWorld03.java
问题:想要在任意目录中,去解释执行指定目录中的字节码文件,如何实现??
分析:java D:\course\JavaProjects\01_JavaSE\day02\Helloworld03 –> 错误演示
解决:配置classpath环境变量来实现【了解】–>为理解idea源文件与字节码文件分离做铺垫
问题:配置了classpath环境变量的作用?
答:一旦配置classpath环境变量,则做解释执行操作的时候,就不会在当前所在目录中找字节码文件,而是直接去classpath路径中找字节码文件。
需求:做解释执行操作时,如果当前位置有该字节码文件,则就执行当前目录中的字节码文件,
如果当前目录中没有该字节码文件,则才去执行指定目录中的字节码文件,如何实现?
解决:设置classpath环境变量的值为”.;D:\course\JavaProjects\01_JavaSE\day02”即可。
注释
作用:解释说明代码
分类:
- 单行注释
- 快捷键:ctrl + /
- 语法://
- 多行注释
- 快捷键:ctrl + shift + /
- 语法:/* 注释内容 */
- 文档注释
- 语法:/** 注释内容 */
常见的转义字符
- \t –> 制表符。作用:显示多个空格,并且还有对齐的功能;
- \n –> 换行符。作用:具有换行功能。
理解编译和反编译
编译:把源文件编译为字节码文件,也就是把”*.java”文件编译为”.class”文件
反编译:把字节码文件编译为源文件。
反编译的实现方式:
方式一:提供javap.exe来实现
- 实现:在字节码文件所在目录中,我们通过javap.exe来实现反编译,例如:javap HelloWorld04
- 优点:能看到编译时期默认做的操作,例如能看到编译时期默认提供的无参构造方法。
- 缺点:反编译之后,我们无法看到方法内部的具体实现,也就是看不到方法体。
方法二:通过jd-gui.exe来实现
- 实现:打开jd-gui.exe程序,然后把需要反编译的字节码文件拖拽进入jd-gui.exe程序中即可。
- 优点:反编译之后,我们能够看到方法内部的具体实现,也就是能看到方法体。
- 缺点:不能看到编译时期默认做的操作,例如无法看到编译时期默认提供的无参构造方法。
方法一与方法二可以看作是互补的。
文件存储的的单位
实际开发中,我们把字节称之为文件存储的最小单位。
开发中,字节有两种表示方式,分别为:
- 无符号表示(只能表示正数,不能表示负数)
- 1个字节无符号表示的数值范围在【0,2^8-1】之间,也就是表示范围在【0,255】之间。
- 作用:基本数据类型中,char类型采用的就是无符号来表示。
- 有符号表示(不但能表示正数,还能表示负数)
- 1个字节有符号表示的数值范围在[-2^ 7,2^7-1]之间,也就是表示范围在[-128,127]之间。
- 作用:基本数据类型中,byte、short、int和long类型采用的就是有符号来表示。
- 常见的文件存储单位及其换算公式
- 1KB = 1024Byte
- 1MB = 1024KB
- 1GB = 1024MB
- 问题:长度单位的换算使用的是1000,为什么文件存储单位换算使用的是1024呢?
- 答:二进制早期有电信号开关演变而来,也就是意味着文件存储的换算肯定使用的是2的多少次方,而2的10次方结果就是1024,也就是2^10是最接近于1000的整数,因此就使用了1024来作为文件存储的换算值。
DAY03
标识符的作用
- 标识符就是给类名、方法名、变量名、常量名和包名命名的规则。
标识符的规则
- 必须由数字、字母、下划线和&组成,并且开头不能是数字。
- 标识符不能是关键字或保留字,因为关键字和保留字是给编程语言使用。
- 在java语言中,对于标识符的长度没有任何限制,也就是标识符可以任意长。
- 补充:java语言默认采用Unicode编码表,而Unicode编码表几乎包含了全世界所有的文字。
- 注意:此处的“字母”我们应该广义地去理解,也就是此处“字母”可以是“英文”,也可以是“中文”。
- 建议:给标识符进行命名的时候,我们不建议使用“中文汉字”来进行命名。
命名规范的讲解
明确:命名的时候不建议使用”中文汉字“,并且还必须做到“见名知意”的要求。
类名:必须遵守“大驼峰”的命名规范,大驼峰:每个单词首字母都大写。
- 例如:HelloWorld、VariableDemo
方法名、变量名:必须遵守“小驼峰”的命名规则,小驼峰:第一个单词首字符小写,从第二个单词起首字母都大写。
- 例如:userName、maxValue
常量名:必须遵守“字母全部大写,多个单词之间以下划线连接”的命名规范。
- 例如:USER、NAME
包名:必须遵守“单词全部小写,多个单词之间以 ‘.’ 连接,并且必须做到顶级域名倒着写”的命名规范。
- 例如:com.bjpowernote.demo
DAY04
数据类型的分类
基本数据类型【八大基本数据类型】
- 整数型:byte、short、int、long
- 浮点数:float、double
- 布尔型:boolean
- 字符型:char
引用数据类型
- 数组、字符串、类和接口等等
整数型(有符号表示)
- byte,占用1个字节,则表示范围在[-2^7, 2^7-1]之间,–> [-128, 127]。
- short, 占用2个字节,[-2^15, 2^15-1], –> [-32768,32767]。
- int, 占用4个字节,[-2^31, 2^31-1], –> 大概在正负21亿之间。
- long, 占用8个字节,[-2^63, 2^63]。
注意:
占用的字节数越大,则表示的数值范围也就越大,开发中我们需要根据存储数值的大小来选择合适的数据类型。
–> 存储的数值大小不能超出其数据类型的表示范围,否则就会编译错误。
–> 实际开发中,byte和short几乎不会使用。存储较小的数值使用int,存储较大的数值使用long。
开发中,只能使用八进制、十进制、十六进制来表示整数,不能“直接”使用二进制来表示整数。
- int num1 = 017:八进制;
- int num1 = 23:十进制;
- int num1 = 0x2B:十六进制;
整数固定值常量默认为int类型,在整数固定值常量的末尾添加”L”【推荐】或”l”,则该常量就变为Long类型。
浮点型(小数)
- float,占用4个字节,我们称之为“单精度类型”,理论上能精确到小数点后7位。
- double,占用8个字节,我们称之为“双精度类型”,理论上精确度是float的两倍。
注意:
占用的字节数越大,则表示小数的精确度就越高,开发中我们建议使用double类型。
–> 开发中,float类型很少使用,因为精确度太低,而double类型很常用。
小数的表示方式有:1)生活中的表示小数;2)使用科学计数法来表示小数。
–> 3.14E3,等效于:3140.0 –> “乘以10的3次方”
–> 3.14E-3,等效于:0.00314 –> “除以10的3次方”
注意:使用科学计数法来表示小数的时候,此处的英文字母不区分大小写(E或e)。
因为小数存储的区别,因此不建议使用小数来做特别精确的运算,因为得到结果可能不精确。
–> double sum = 0.001 + 0.0002; 理论结果是:0.0003 实际结果:0.000300000000000000000003
小数固定值常量默认为double类型,在小数固定值常量末尾添加”F”【推荐】或”f”,则该常量就变为:float类型。
浮点型占用的字节数,强调的是存储”小数部分”占用的字节数,并不是强调存储”整数部分”占用的字节数。
–> float类型存储”整数部分占用8个字节”,存储”小数部分占用4个字节”,总计至少占用12个字节。【底层(科学计数法)】
布尔型(boolean)
明确:布尔类型的固定值常量只有true和false,并且true和false都是关键字。
–> true:表示为真或条件成立
–> flase:表示为假或条件不成立
使用场合:常用于条件判断,条件成立则返回true,条件不成立则返回false。
面试题:请问boolean类型占用几个字节?
–> 在java规范中,没有明确boolean类型占用几个字节。我个人觉得boolean类型占用x个字节,并说出理由!
字符型(char,无符号表示)
- 明确:字符型占用2个字节数,表示的数值范围在[0,2^16-1]之间,也就是表示范围在[0,65535]之间。
- 注意:使用单引号包裹的一个字符串,我们就称之为字符固定值常量。
字符串类型?
明确:字符串类型的名字叫做String类型,并且String类型属于”引用数据类型”。
注意:使用双引号包裹的任意多个字符,我们就称为“字符串固定值常量”。
–> 双引号包裹的0个字符,我们就称之为”空字符串”。
关于”+”的作用
- 表示正数。eg:int num = +8;
- 加法运算,要求两个操作数都必须是数值型。eg:int sum = 5 + 8;
- 连接符,要求其中一个操作数必须是字符串类型。eg:”hello” + true;
- 结论:字符串的连接符操作,则运算完毕后返回的结果肯定属于String类型。
字符在内存中的存取(理解)
整数在内存中的存取
- 存储:直接把整数转化为二进制,然后存入到内存中即可。
- 读取:取出内存中的二进制,然后把该二进制转化为十进制。
字符在内存中的存取
明确:制作一个《编码表》,在《编码表》中让每个“字符”都对应一个“正整数”。
存储(编码):把需要存取的“字符”对照《编码表》,则就得到了一个“正整数”,然后将该“正整数”存入到内存中即可。
读取(解码):把内存中的二进制转化为:“正整数”,然后把“正整数”对照《编码表》,则就得到了该“正整数”对应的“字符”。
注意:“编码”类似于发电报时的“加密”操作,“解码”类似于收电报时的“解密”操作,而《编码表》就类似于《密码本》。
–> “加密”和“解密”必须对照同一个《密码本》,则“编码”和“解码”必须对照同一个《编码》。
常见编码表的概述
ASCII:美国信息交换标准代码。
GBK:全称《汉字内码扩展规范》,字库是用来表示中文用的编码。ANSI编码表就是GBK子码表,专门用于表示简码表。
Unicode:又称万国码、同一码,是为了解决传统的编码方案的局限性而产生的,在Unicode编码表中几乎包含了全世界所有的文字。
问题:请问全世界所有的文字有多少个?
–> 答案:肯定不超过65536个文字,因为char类型占用2个字节,能描述65536种可能。
ASCII和Unicode之间的关系?
ASCII编码表的前128位和Unicode编码表一模一样,也就是Unicode编码表中包含了ASCII编码表。
- ‘1’对应的正整数为:49
- ‘A’对应的正整数为:65
- ‘a’对应的正整数为:97
注意:两个大小写英文字母对应正整数之差为32,则我们就可以通过”小写字母”找到对应的”大写字母”。
int 类型和char类型的关系?
相同点:
在内存中存储的都是“整数”,则就有以下重要的结论:
char类型”肯定”都能转化为int类型,int类型”未必”能转化为char类型
不同点:
int类型占用4个字节,而char类型占用2个字节。
int类型采用”有符号”表示,而char类型采用“无符号”表示。
DAY05
常见的转义字符
明确:转义字符就是一个特殊的字符,并且每个转义字符都有自己的特殊含义。
\t,制表符,作用:显示多个空格,并且还有对齐的功能。
\n,换行符,作用:具有换行的功能。
\“,编译时,把它当成一个整体,不作为字符串结束的标记;
运行时,会忽略反斜杠,只会展示出一个双引号。
\‘,编译时会把它当成一个整体,运行时只会展示出一个单引号。
关于字符的使用
方式一:把字符放在字符串内部使用!
- System.out.println(“hello\tworld”);
方式二:把字符串单独使用,然后再使用+来拼接。
- System.out.println(“hello” + ‘\t’ + “world”);
注意:
- int类型和char类型做“+”运算,则做的是“加法操作”。
- String类型和char类型做“+”运算,则做的是“连接符操作”。
关于Unicode值得补充
- 因为java语言默认采用Unicode编码表,因此每个”字符”都对应一个Unicode值,其中一个Unicode值我们必须掌握
- ‘\u0000’代表的是空格字符
数据类型的转换
为什么需要学习数据类型的转换?
- 因为java是强类型的语言,因此参与“赋值运算”和“算数运算”的时候,要求参与运算的数据类型必须保持一致,否则就需要做数据类型转换。
基本数据类型转换的方式有哪些?
- 隐式类型转换(自动)
- 强制类型转换(手动)
哪些基本数据类型可以相互转换?
- 除了boolean类型外,其余的基本数据类型都可以相互转换。
隐式类型转换(自动)
- 原则:低字节向高字节自动提升。
- byte –> short –> int –> long –> float –> double
- char –> int
赋值运算:
原则:低字节向高字节自动提升。
特例:把int类型的常量,赋值给byte、short和char类型的变量或final修饰的常量时,则就是属于隐式类型转换的特例。只需赋值的数据没有超出其数据类型的表示范围即可。
–> 赋值的数据应该是什么?赋值的数据应该是int类型的常量!
–> 赋值数据的大小是什么?赋值数据的大小不能超出其数据类型的表示范围。
算术运算
原则:两个操作数做运算,如果其中一个操作数为double类型,则另外一个操作数也会隐式转化为double类型;否则,如果其中一个操作数为float类型,则另外一个操作数也会隐式转化为float类型,最终计算结果就是float类型;否则,如果其中一个操作数为long类型,则另外一个操作数也会隐式转化为long类型,最终计算结果就是long类型;否则,这两个操作数都会隐式转化为int类型,最终计算的结果就是int类型。
面试题

强制类型转换
当隐式类型转换无法解决问题时,我们要采用强制类型转换。
语法:目标类型 变量 = (目标类型) 数据;
eg: int num = (int) 3.14; –> 可以用来小数取整。【一、想要的精度丢失】
底层:只保留低位字节的二进制,高位字节的二进制就丢弃。
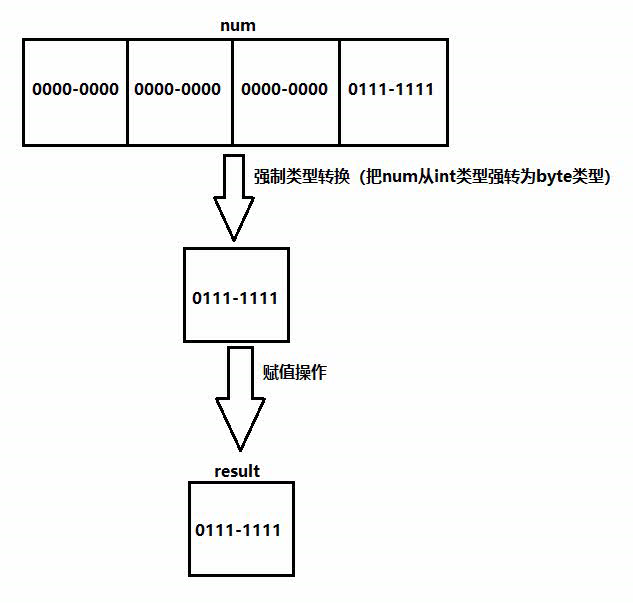
注意:使用强制类型转换的时候,可能就丢失精度,使用的时候切记。【二、不想要的精度丢失】
–> int num = (int) 3.14; 只保留了整数位,丢失了小数位。
强制类型转换后,被强制转换的变量还是原来的数据类型。
eg: int num; byte num1 = (int) num; –> num (int类型)
使用强制类型转换的时候,我们必须明确强制转换数据的范围,否则得到的结果就不准确。
DAY06
赋值运算符
“=”,作用:把等号右边表达式的结果赋值给等号左边的变量或final修饰的常量保存。
面试题【详细代码见day01–>Exercise02_ChangeNumber】
用四种方式交换两个数值:
- 创建临时变量temp;
- 加减法(正整数);
- 乘除法;
- 异或法;
算法运算符的分类
一元运算符(只需要一个操作数参与运算)
包含:++、–
二元运算符(需要两个操作数来参与运算)
包含:+ 、-、*、/、%
+:表示正数,加法运算,连接符操作;
-:表示负数,减法运算;
*:乘法运算
/:除法运算
%:取模运算或取余运算
–> 作用:获得两个整数相除的余数
eg:0 % 3 = 0 –> 注意:0能被任何数整除。
1 % 3 = 1
注意:”除法运算”是获得两个整数相除的”整数位结果”,”取模运算”是获得两个整数相除的”余数”。
使用场合:
- 判断m能否被n整除,如果m%n的结果为0,则意味着m能被n整除;如果m%n的结果不为0,则意味着m不能被n整除。
- “任意数 % m”,则得到的结果肯定在[0,m - 1]之间,例如:”任何数 % 3”,则得到的结果肯定是在[0, 2]之间。
除法运算符的注意事项
- 在java语言中,两个整数做除法运算,则得到的结果肯定为整数。
- 在java语言中,做除法运算的时候,分母不能为0,否则就会抛出算数异常(ArithmeticException)。
算术运算符之一元运算符


比较运算的概述
明确:比较运算符返回的结果肯定是boolean类型。
如果条件成立,则返回true;如果条件不成立,则返回false。
包含:> 、>=、<=、==、!=
==(等于),判断左右两边的结果是否相等。
–> 如果左右两边属于“基本数据类型”,则比较左右两边的“数据值”是否相等(掌握)。
–> 如果左右两边属于“引用数据类型”,则比较左右两边的“地址值”是否相等(了解)。

!=(不等于),判断左右两边的结果是否不相等。
–> 如果左右两边属于“基本数据类型”,则比较左右两边的“数据值”是否不想等(掌握)。
–> 如果左右两边属于“引用数据类型”,则比较左右两边的“地址值”是否不相等(了解)。
注意点:
- 比较运算符是一个整体,中间不允许条件空格!
- 注意区分“=”和“==”的区别,“=”属于赋值运算符,“==”属于比较运算符。
比较运算符的面试题
问题:请问以下代码是否有问题?如果没有语法问题,请说出结果是什么?

逻辑运算符的概述
明确:参与逻辑运算的数据必须是boolean类型,并且逻辑运算符返回的结果肯定是boolean类型。
包含:&、|、^、&&、||、!
&(与运算符),属于二元运算符
–> 结论:只要两边都为true,则结果就是true。
只要有一边为false,则结果就是false。
辅助记忆:小明“与”小红来一趟办公室。
|(或运算符),属于二元运算符
–> 结论:只要两边都为false,则结果就是false。
只要有一边为true,则结果就是true。
辅助记忆:小明“或”小红来一趟办公室。
^:异或运算,相同为false,不同为true。
———————–以上三个开发中不常用,但是结论很重要———————-
———————–以下三个开发中常用,并且结论也很重要———————-
&&(短路与),属于二元运算符
结论1:&和&&的执行结果一样。
结论2:&&当左侧表达式为false时,右边不执行,结果直接原样返回左侧结果为false。
&&当左侧表达式为true时,右边执行,结果直接原样返回右侧结果。
||(短路或),属于二元运算符
结论1:|和||的执行结果一模一样;
结论2:如果左侧表达式的结果为true,则右边表达式肯定不会执行,并且原样返回左侧表达式的结果(true)。
如果左侧表达式的结果为false,则右侧表达式肯定会去执行,并且原样返回右侧表达式的结果(true|false)。
!(非运算),属于一元运算符。
使用场合:
- 如果两个条件必须成立才能满足需求,则这两个条件之间使用“&&”来组织关系;
- 如果两个条件其中一个成立既能满足需求,则这两个条件之间使用”||”来组织关系。
面试题
请问:&和&&的区别和联系
- 共同点:&和&&的执行结果一模一样。
- 不同点:&&的执行效率高于&,因此开发中我们常用&&。
请问:|和||的区别和联系
- 共同点:|和||的执行结果一模一样。
- 不同点:||的执行效率高于|,因此开发中共我们常用||。
问题:在注释中,如何表示区间范围?
答:[]代表包含,()代表不包含。
eg:[3,5) –> 表示3到5之间的整数,包含3,但不包含5
(3.0,5.0] –> 表示3.0到5.0之间的小数,包含5.0,但不包含3.0
位运算(了解,建议掌握)
明确:参与位运算的数据应该是整数型,并且位运算返回的结果也是整数。
包含:&、|、^、~、<<、>>、>>>
&(与位运算),属于二元运算符
结论:位都为1,则结果就是1;位有一个为0,则结果就是0
使用场合:学习HashMap集合的时候,验证为啥底层的数组空间长度必须为2的整数次幂。
|(或为运算),属于二元运算符
结论:位都为0,则结果就是0;位有一个为1,则结果就是1
^(异或位运算),属于二元运算符
结论:位相同,则为0;位不同,则为1
特点:对m连续异或n两次,得到的结果依旧为m
–> m^n ^ n 的结果为m,n^m ^n的结果为m,n ^ n ^ m的结果为m
使用场合:
- 使用异或位运算,我们可以实现对数据的”加密”和”解密”操作。
- 加密:对需要加密的数据异或m,则就得到了加密后的结果。
- 解密:对加密后的数据继续异或m,则就得到了解密后的结果。
- 使用异或位运算,用于交换两个变量的值。
- 优点:效率非常高;
- 缺点:复杂、不好理解。
~(非位运算符),属于一元运算符
结论:二进制位取反的含义。0取反的结果就是1,1取反的结果就是0。
<< (左移位运算)
结论:对m左移n位,则等效于:m * 2n
–> 此处m可以是正数,也可以是负数!
特点:左移运算之后,则低位永远补0即可。
使用场合:对m做乘以2的操作,则最高效的方式为:m << 1
(>>右移位运算)
结论:对m右移n位,则等效于:m/2n
–> 此处m必须是正数,不能为负数!
特点:正数右移,则高位补0;负数右移,则高位补1
使用场合:对m做除以2的操作,则最高效的方式为:m>>1
–> 此处m必须有正好,不能为负数!
(>>>无符号右移)
- 无论对正数还是负数做无符号右移的操作,则高位永远补0即可。
三目运算符
语法:数据类型 变量名 = 条件表达式?表达式1 : 表达式2;
执行:如果”条件表达式”的结果为true,则执行”表达式1“,也就是”把表达式1*的结果赋值给等号左边的变量来保存。
如果”条件表达式“的结果flase,则执行“表达式2”,也就是把“表达式2”的结果赋值给等号左边的变量来保存。
注意:if…else选择结构在某些情况下可以被三目运算符代替,毕竟这两者都是做的“二选一”的操作。
DAY07
idea的使用

如何使用IDEA来编译源文件?
明确:IDEA默认已经集成了javac.exe这个可执行程序,也就是使用IDEA就会默认实现对源文件的编译操作。
问题:IDEA项目中的源文件放在哪里的?
–> 源文件放在IDEA项目中的src目录中
问题:IDEA项目中的字节码文件放在哪儿的?
–> 字节码文件放在IDEA项目中的out目录中。
2、如何使用IDEA来执行程序呢?
明确:IDEA默认已经集成了java.exe这个可执行程序,因此我们直接使用IDEA就可以运行java程序,并且运行程序的方式如下:
方式一:选中类型或main方法左侧行号附件的运行按钮,然后选中该“run.Xxx.main()”即可。
–> 也可以通过点击“工具栏”中的运行按钮和“控制台”左侧的运行按钮来执行程序。
方式二:在代码块编辑区域,我们鼠标右键,然后选中“Run Xxx.main()”即可。
方式三:使用“ctrl + shift + F10”快捷键来运行IDEA程序。
IDEA的常用的快捷键

- Ctrl + Alt + L:代码格式化快捷键
如何查看idea的代码编译错误
- 提示1:如果某行代码有语法错误,则该代码文本底部有红色波浪线。
- 提示2:如果标识符错误,则该标识符的名字就会变为红色字体显示。

代码的执行顺序
顺序执行
选择执行
if选择结构
if单选结构
- 概述:if(条件表达式){ //当“条件表达式”的结果为true,则执行此处的代码。}
- 注意:
- 此处的“条件表达式”返回的结果必须时Boolean型。
- if选择结构依旧包含在顺序执行中,也就是顺序执行中包含了选择执行。
if双选结构
if多选结构
- 在完整的if多选结构中,有且只能执行一个大括号中的代码(多选一)。
- if,最前面,有且只能有一个(1)
- else if,中间位置,可以有任意多个(0,1,2,…,n)
- else,最后面,最多只能有一个(0或1)
if选择结构的总结
如果if选择结构中只有一行代码,则我们还可以省略大括号!
省略大括号之后,则编译时会默认添加一个大括号,用于包裹if结构中的第一行代码。
建议:对于初学者而言,不建议省略if选择结构中的大括号,省略大括号之后可能会带来额外的问题。
请问以下代码是否有语法问题?如果没有语法问题,请说出执行的结果是什么?–>输出:xixi
if(false);{ //等效于:if(false){};{} System.out.println("xixi"); //会执行 }
switch选择结构
关于switch关键字的注意点:
- 此处“表达式”的结果必须是byte、short、int、char、String和枚举(后面学习)类型 ,别的类型都会编译错误!
- “表达式”的结果不能是boolean类型,因此switch选择结构就不能对布尔类型的数据进行匹配!
关于case关键字
case关键字后面必须是“常量”,不能为“变量”,从而保证匹配的安全性!
在switch选择结构中,case后面不允许有多个“相同的”常量值,否则就会编译错误!
在此处“表达式”结果的类型和case后面“常量值”的类型必须保持一致,否则就会编译错误!
–> 此处的数据类型必须“保持一致”,包含了“隐式类型转换”之后能保持一致。
–> 因为“表达式”结果不支持boolean类型,因此case后面就不能为boolean类型的数据,也就是不支持区间判断。
关于break关键字的注意点:
- 一旦执行break关键字,则就会跳出switch选择结构,执行switch选择结构之后代码。
- 在switch选择结构中,我们可以省略break关键字,省略break关键字之后,则就会发生“穿透”,直到遇到下一个break才会结束“穿透”。
关于default关键字的注意点:
- 当switch选择结构中的所有case都无法匹配成功,则那么才会去执行default中的代码,此处的default类似于if选择结构中的else代码块。
- 在switch选择结构中,虽然可以省略default关键字,但是我们不建议省略,除非case都匹配所有的问题。
强调:在某个case中定义的变量,则该变量就只能在当前作用域中使用,不能在别的case中使用!
循环执行
DAY08
什么是代码块?
- 在java语言中,什么是局部变量呢?在代码块或方法体中定义的变量,我们就称为“局部变量”。
- 在java语言中,局部变量的生命周期在哪儿?定义变量的时候“出生”,执行到所在大括号的结束位置就“死亡”。
- 在java语言中,代码块具备什么特点呢?在代码块中定义的变量,则该变量就只能在当前作用域中使用,不能再代码块之外使用。
- if选择结构,我们也称之为“带名字的代码块”或“带条件的代码块”,因此在if选择结构中定义的变量,我们不能在if选择结构之外使用。
当if单选结构和if多选结构都能解决同一个问题的时候,我们建议使用if多选结构来实现,因为此处使用if多选结构效率高。
switch的匹配底层如何实现的呢?
- 如果匹配的是“基本数据类型”,则使用“==”比较运算符实现匹配操作;
- 如果匹配的是“引用数据类型”,则使用equals()方法来实现匹配。
强调:每个功能完成之后,一定要对各种情况进行测试,从而找到代码中隐藏的问题(bug)。
使用场合
- if选择结构的使用场合:
- if选择结构适用于“boolean”类型数据的判断,也就是适用于“区间范围”的判断。
- switch选择结构的使用合成:
- switch选择结构适用于对“固定值”的判断,也就是“固定值”的判断必须使用switch来实现。
- if选择结构和switch选择结构的总结
- 使用switch结构能做的事情,我们使用if选择结构都能实现;
- 使用if选择结构能做的事情,switch不一定都能实现。
循环结构的分类
for循环
请问以下代码有没有语法错误?
int i = 10; for(;i > 0;i--){ //没有语法问题,循环初始化在for循环外,内部可省略 System.out.println(i); }for循环结构,我们也称为“带名字的代码块”或“带条件的代码块”,因此在“循环体”中定义的变量不能再循环之外使用。
在循环体定义的变量,每次执行循环体该变量都“出生”,每次循环体执行完毕该变量都“死亡”。
问题:想要在循环体中,每次操作的都是同一个变量,则该变量应该定义在哪里?–> 必须定义在循环之前!
“循环条件表达式”返回的结果必须是boolean类型,但是“循环初始化表达式”和“循环后的操作表达式”没有特殊要求。
for(System.out.println("A");i<6;System.out.println("C")){ System.out.println("D"); i++; }同时循环两个变量
for(int i = 9; j = 1; i >= 0 && j <= 10; i -= 4, j += 3){ System.out.println("i = " + i + ",j = " + j); }
while循环
do…while循环
对程序有利的死循环
使用:当不确定循环执行的次数时,我们就使用死循环来实现。
问题:如何书写简单的while、for死循环?
while(true){} for(;;){} //等效于:for(;true;){}注意:使用for循环的时候,我们如果省略“循环条件表达式”,则默认值就是true。
break与return

continue

DAY08
嵌套循环

方法的声明
方法的调用

调用方法的内存分析(重点)
- 栈内存的特点?
- 栈内存具备“先进后出,后进先出”的特点,类似于生活中的“子弹夹”。
- 调用方法的内存分析?
- 调用方法的时候,则自动就会在栈内中开辟一个“栈帧”,用于执行该方法体中的代码。–>入栈操作
- 方法调用完毕的内存分析
- 在方法体中一旦执行“return”关键字,则就证明方法调用完毕,那么调用方法时所开辟的“栈帧”就会被摧毁。–> 弹栈操作
- 问题:调用方法的时候,实参num1和num2与形参num1和num2是否有关系?
- 答案:此处的“实参”和”形参”没有任何关系,仅仅是”名字”相同而已。
方法的使用(重点)
方法的使用原则
- 先声明,后调用。
方法声明的难点
- 明确1:完成该功能,是否需要返回值。–> 返回值类型
- 明确2:完成该功能,是否需要外部参数参与方法内部的运算。 –> 形参列表
方法的分类
无参无返回值方法
需求:在方法中输出“hello world”。
分析:完成该功能,无需返回值,因此返回值类型为void。
完成该功能,无需外部参数参与方法内部运算,因此没有形参。
无参有返回值方法
需求:调用方法获得常量3+4的和。
分析:完成该功能,需要返回值,因此返回值类型为int。
完成该功能,无需外部参数参与方法内部的运算,因此没有参数
有参无返回值方法
需求:在方法中输出指定两个int数据之和。
分析:完成该功能,无需返回值,因此返回值类型为void。
完成该功能,需要外部参数参与内部的运算,也就是需要两个int类型的形参。
有参有返回值方法
需求:调用方法获得指定两个double数据之和。
分析:完成该功能,需要返回值,因此返回值类型为double。
完成该功能,需要外部参数参与方法内部的运算,也就是需要两个double类型的形参。
方法的重载(overload)重点
方法重载的定义
同一个类中,具有相同的方法名,但是参数个数不同或参数类型不同,这就构成了方法的重载!
核心:两同,两不同
–> 两同:同一个类中,具有同名的方法。
–>两不同:参数个数不同,参数个数不同 或 参数类型不同。
方法重载的特点
- 修饰符不同,没有构成方法重载;
- 形参名字不同,没有构成方法重载;
- 返回值类型不同,没有构成方法重载。
方法重载的好处
- 官方:方法重载的出现,使其同一个类中允许定义多个同名的方法,从而避免了方法名被污染。
- 通俗:学习方法重载之后,如果同一个类中多个同名的方法发生了编译错误,则首先考虑这些方法是否满足方法重载!
重载方法的调用
- 调用重载方法的时候,会根据实参的“个数”和“类型”来选择调用合适的方法。
目前已经用过的重载方法有哪些?
- print()、println()等等
- 问题:通过IDEA工具,如何查看底层的API源码?
- 实现:按下Ctrl键,然后鼠标左键单击即可。
DAY09
数组(引用数据类型,最常用、最基础的数据结构)
数组的定义
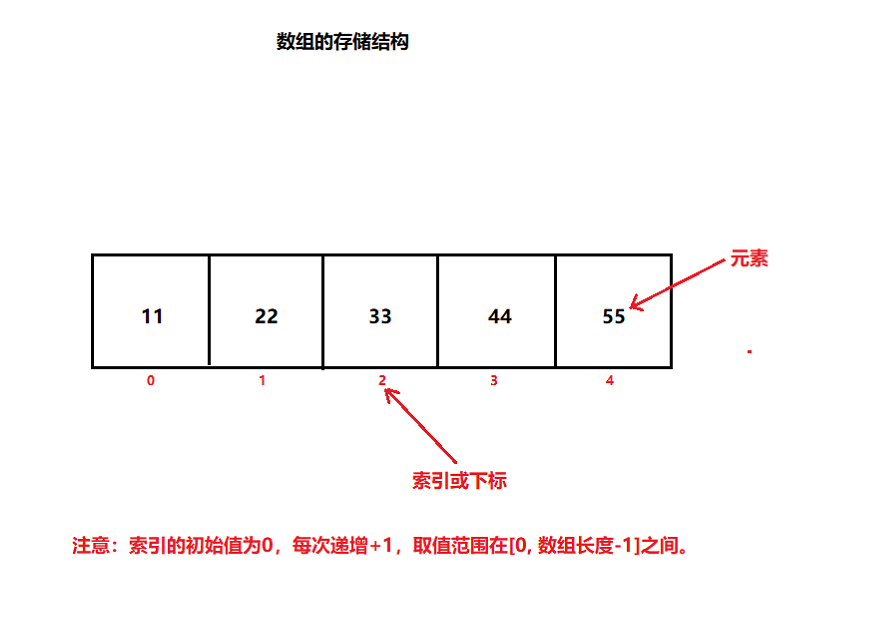
- 数组就是一个存储“相同数据类型”的“有序”集合(容器)。
数组的声明
明确:所谓数组的声明,指的就是给数组取一个名字,类似于变量的声明。
语法1:数据类型[] 数组名;
int[] arr1; String[] arr2;语法2:数据类型 数组名[];
int arr1[]; String arr2[];注意:开发中,建议使用“语法1”来声明数组,因为“数据类型[]”代表的是“数组类型”。
数组的创建
明确:所谓数组的创建,指的就是在内存中为数组开辟存储空间。
方式一:动态创建数组(仅仅在内存中开辟存储空间,但没有给数组元素指定赋值)
语法:数据类型[] 数组名 = new 数据类型[空间长度];
int[] arr1 = new int[5]; String[] arr2 = new String[10];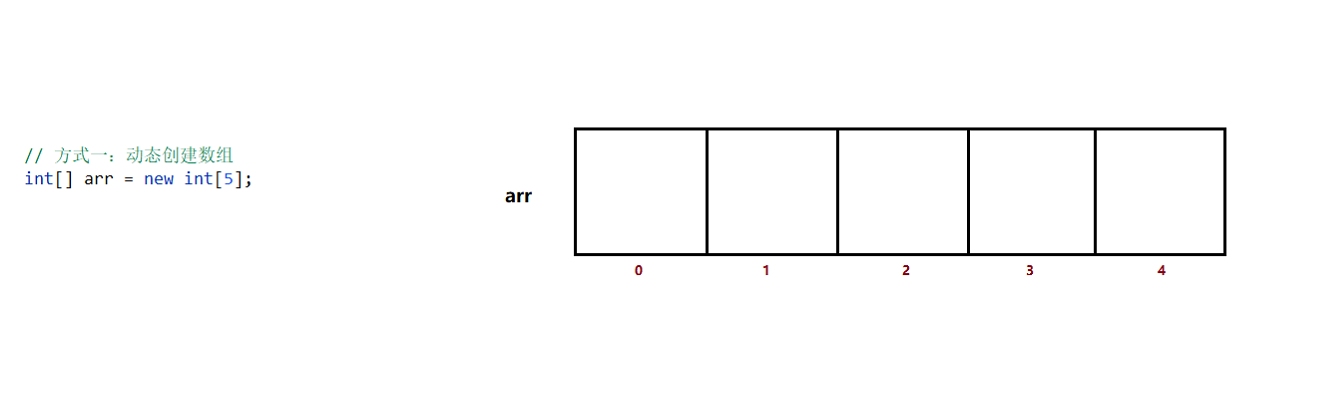
方式二:静态创建数组(不但在内存中开辟存储空间,并且还给数组元素指定赋值)
语法1:数据类型[] 数组名 = {数据1,数据2,数据3,…};
int[] arr1 = {11,12,34,43}; String[] arr2 = {"aa","gg"};语法2:数据类型[] 数组名 = new 数据类型[]{数据1,数据2,数据3,…};
int[] arr1 = new int[]{11,23,55}; String[] arr2 = new String[]{"ss","tr"};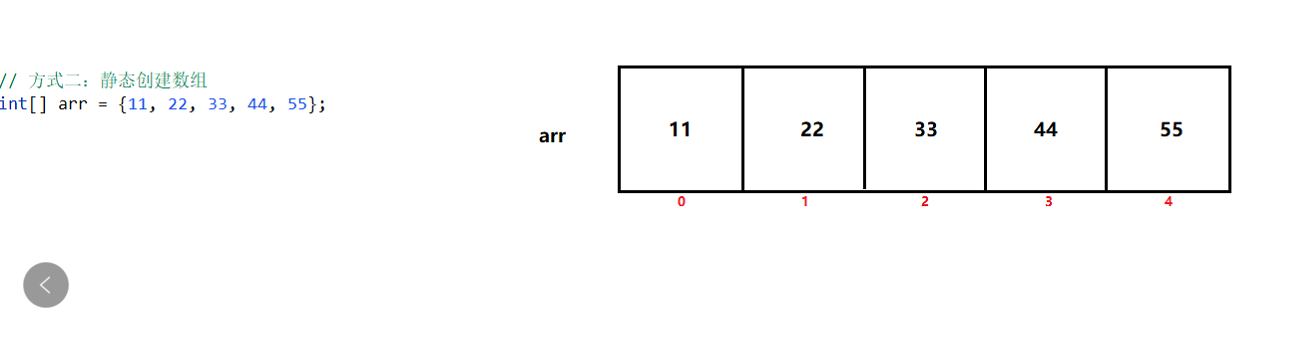
操作数组元素
明确:想要操作数组元素,则必须通过“索引”来实现,因为通过“索引”就能找到元素对应的存储空间,然后就能做出“赋值”和“取值”的操作。
数组的注意点
数组存储的是相同数据类型的元素,则意味着每个元素占用的字节数相同。
数组是一块连续的存储空间,则意味着相邻两个元素的存储空间是紧挨着的。
创建数组的时候,我们必须明确数组的空间长度,并且数组一旦创建成功,则数组的空间长度就不能改变了。
给数组元素赋值的时候,赋值“元素的类型”必须和“声明数组的数据类型”保持一致,否则就会编译错误!
int[] arr = new int[5]; arr[0] = 11; //没问题 arr[1] = "abc"; //编译错误声明数组的时候,我们可以使用“基本数据类型”来声明数组,也可以使用“引用数据类型”来声明数组。
int[] arr1; //基本数据类型 String[] arr2; //引用数据类型通过索引来操作数组元素的时候,操作的索引值必须合法,如果索引值不合法就会抛出数组索引越界异常。
明确:数组索引的合法取值范围在[0,数组长度-1]之间,如果索引越界就会抛出数组索引越界异常(ArrayIndexOutOfBoundsException)。
int[] arr = {11, 22, 33, 44, 55}; System.out.pritnln(arr[0]); //输出11 System.out.println(arr[5]); //抛出数组索引越界异常通过大括号创建出来的数组,则无法“直接”作为方法的”返回值”和”实参”,因为编译器不认识大括号创建出来的数组。
数组的属性
- 明确:基本数据类型没有属性和方法,但是引用数据类型有属性和方法。
- 强调:通过数组的“length”属性,我们可以动态的获得数组的空间长度。
数组元素的默认值
明确:通过“动态创建数组”的方式,则数组中每个元素都有默认值,并且元素的默认值规则如下:
- 整数型(byte、short、int和long)数组元素的默认值为:0
- 浮点型(float和double)数组元素的默认值为:0.0
- 布尔型(boolean)数组元素的默认值为:false
- 字符型(char)数组元素默认值为:’\u0000’ –> 代表空格字符
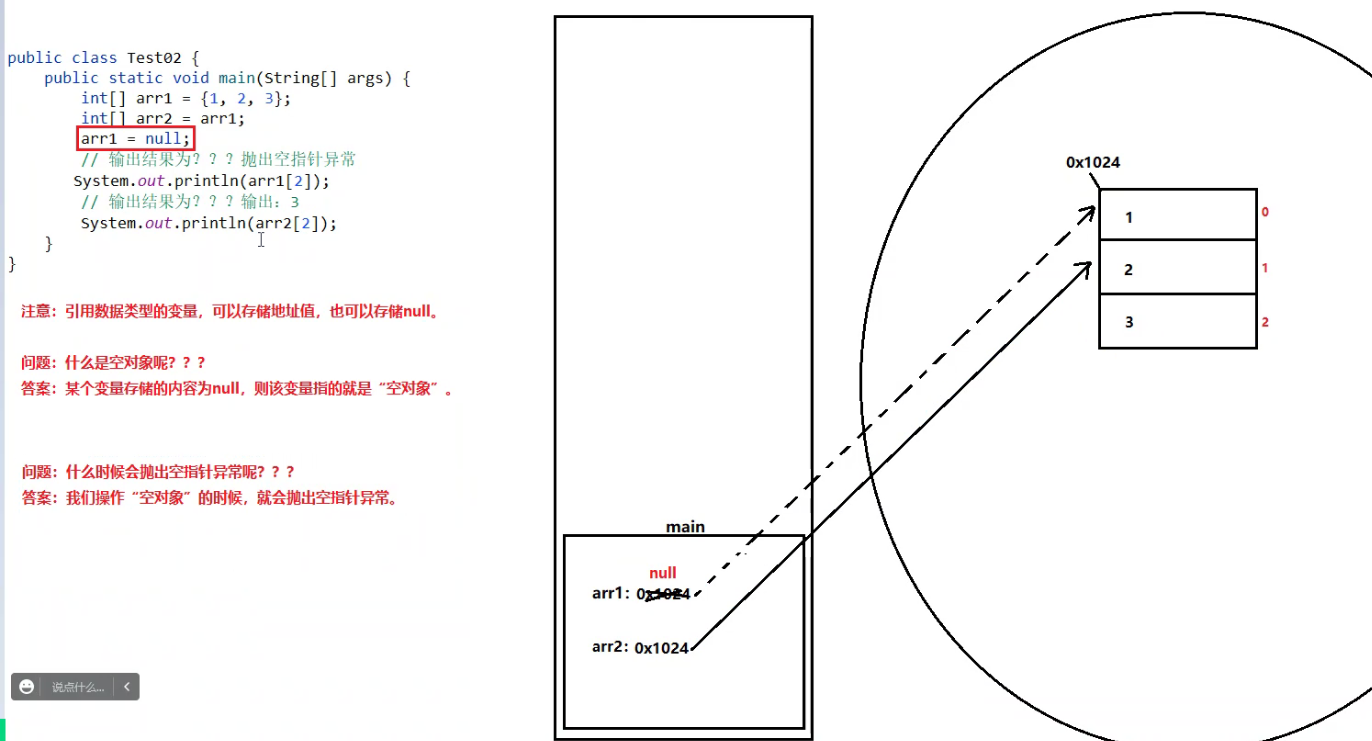
- 引用数据类型(数组、字符串、类和接口)数组元素的默认值为:Null –> 此处是null关键字,代表的是空对象。
数组元素的遍历
使用普通for循环来实现
- 思路:通过普通for循环,获得[0, 数组长度-1]的合法索引取值,然后再通过索引获得数组元素
- 优势:遍历的过程中,可以获得数组的合法索引值,因此遍历过程中我们可以操作数组中的元素。
- 劣势:语法复杂,效率较低。
- 使用场合:遍历数组的过程中,如果想要获得数组的合法索引取值,或者想要在遍历过程中操作数组元素,则“必须”通过普通for循环来实现。
使用增强for循环来实现
语法:
/* for(数据类型 变量名 : 数组或集合){ //循环体 } */ int[] arr = {1,23,4,5}; //增强for循环 for(int element : arr){ System.out.println(element); }优势:语法简洁,效率较高。
劣势:遍历的过程中,不能获得数组的合法索引值,因此遍历过程中我们无法操作数组中的元素。
使用场合:遍历数组的过程中,如果无需获得数组的合法索引取值,也就是遍历数组过程中无需操作数组元素,则建议通过增强for循环来实现。
快速使用增强for循环来遍历数组:数组名.for + enter
强调:通过length属性获得数组空间长度,则该操作的效率是非常低,因此在循环中切记不要使用length属性来获得数组空间长度。
建议定义一个数组长度变量来循环。
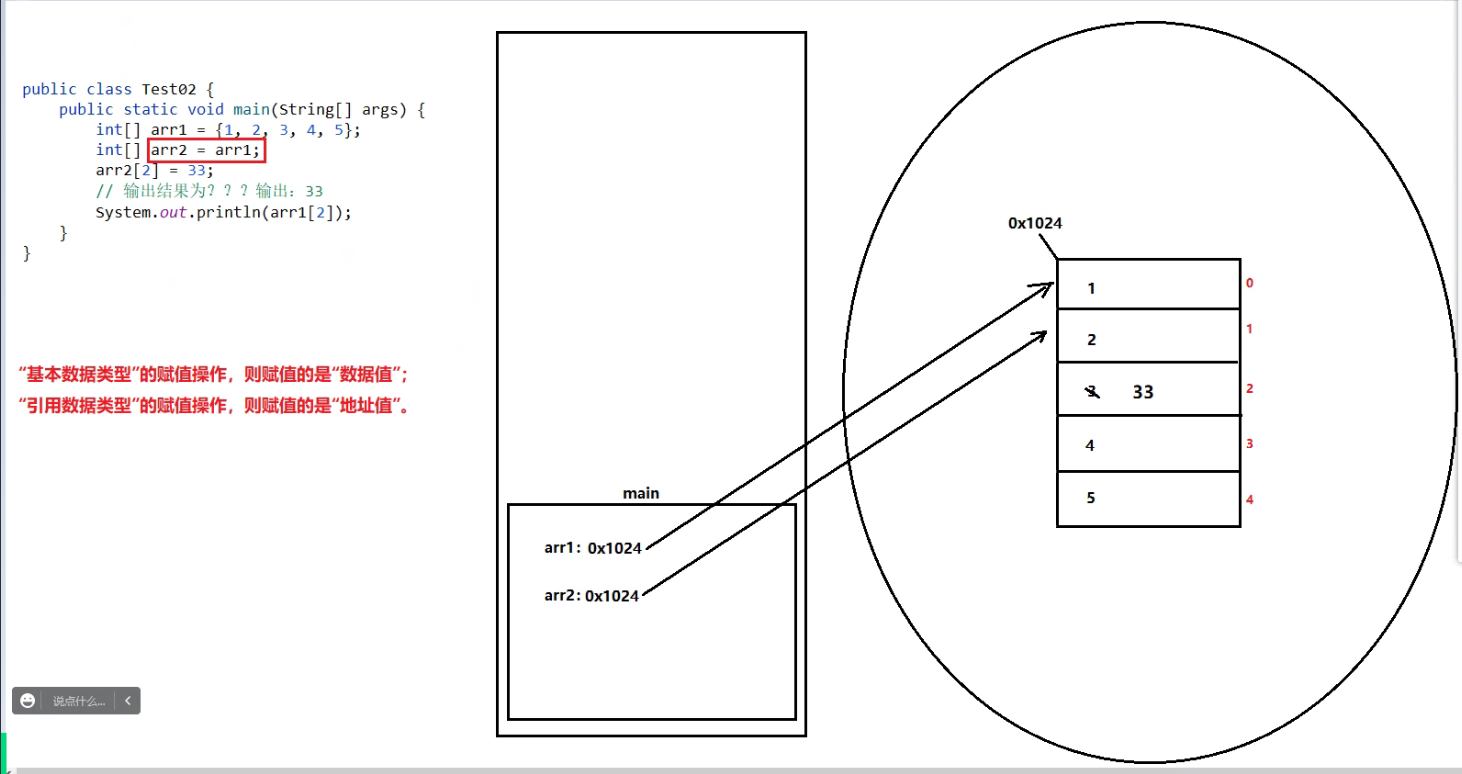
栈内存的概述
存储:局部变量
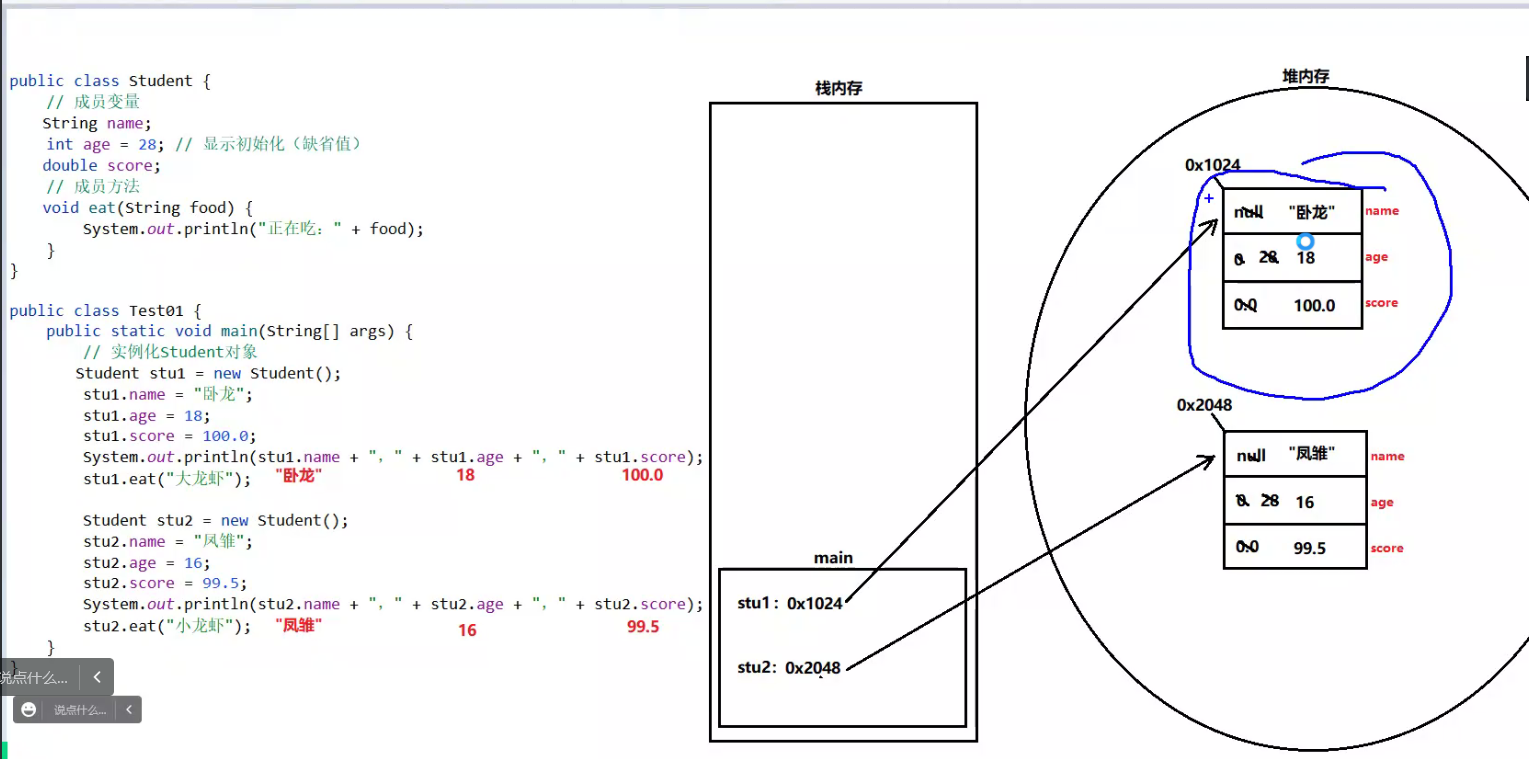
–> “基本数据类型”的局部变量,则在栈内存中存储的是”数据值”。
–> “引用数据类型”的局部变量,则在栈内存中存储的是”地址值”。
特点:
- 栈内存具备”先进后出”或”后进先出”的特点,类似于生活中的”子弹夹”。
- 栈内存是一块连续的存储空间,由虚拟机分配,效率高!
- 栈内存由虚拟机来管理,也就是无需程序员来手动管理内存。
- 虚拟机会为每个线程创建一个栈内存,用于存放该线程执行方法的信息。
堆内存的概述
存储:对象(数组)
特点:
- 堆内存不是一块连续的存储空间,分配灵活,但是效率低。
- 堆内存理论上需要程序员来手动管理,但是实际上交由”垃圾回收机制”来管理。
- 虚拟机中只有一个堆内存,被所有的线程共享。
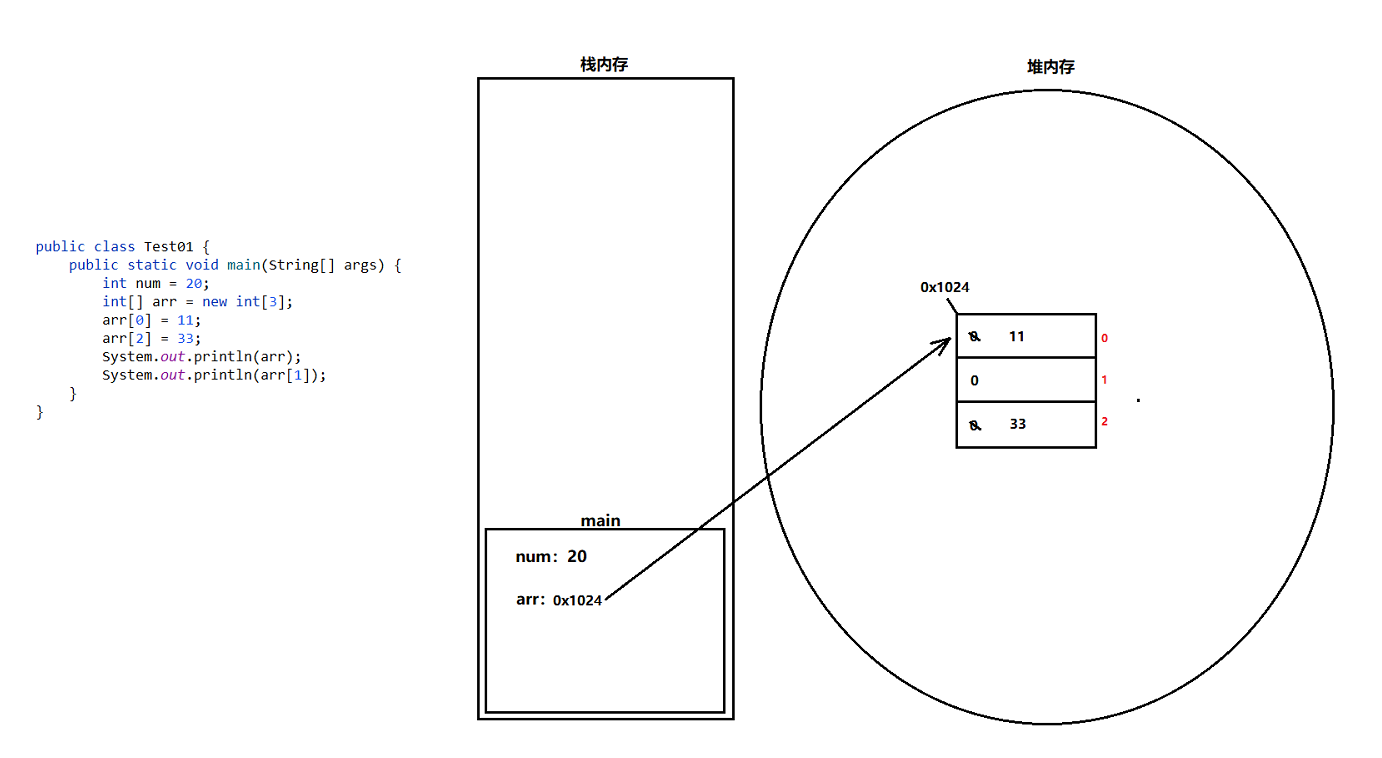
直接输出一个数组,则输出内容是什么?
int[] arr = new int[3];
System.out.println(arr); //输出:[I@4554617c分析:”[I@4554617c”表示的含义是什么?
- [ –> 代表数组类型;
- I –> 代表数组元素为int类型
- @之后 –> 代表哈希编码之后的6进制地址值(简称:地址值)
注意:此处 “ [I “ 代表的就是int类型的数组。
问题:想要输出数组中的所有元素,则该如何实现?
- 必须遍历数组来实现,而不能直接输出该数组(地址值)。
eg1:
eg2:
目前已经见过的异常有哪些?
- 算数异常(ArithmeticException)
- 原因:做除法操作的时候,如果分母为零,则就会抛出算数异常。
- 数组索引越界异常(ArrayIndexOutOfBoundsException)
- 原因:根据索引操作数组元素的时候,如果操作的索引值越界,则就会抛出数组索引越界异常。
- 空指针异常(NullPointerException)
- 原因:我们对空对象做操作,则就会抛出空指针异常。
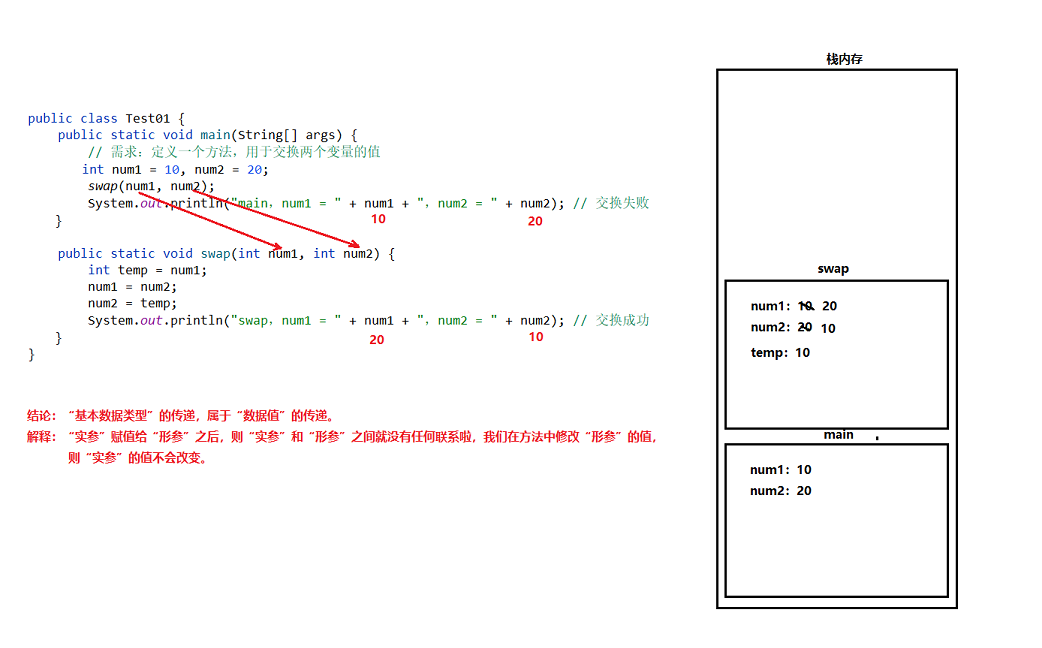
调用方法时,实参传递给形参的过程(超级重点)
调用方法时,基本数据类型的传递
- 结论:”基本数据类型”的传递,属于”数据值”的传递。
- 解释:”实参”赋值给”形参”之后,则”实参”和”形参”就没有任何联系了,我们在方法中修改”形参”的值,则”实参”的值不会改变。
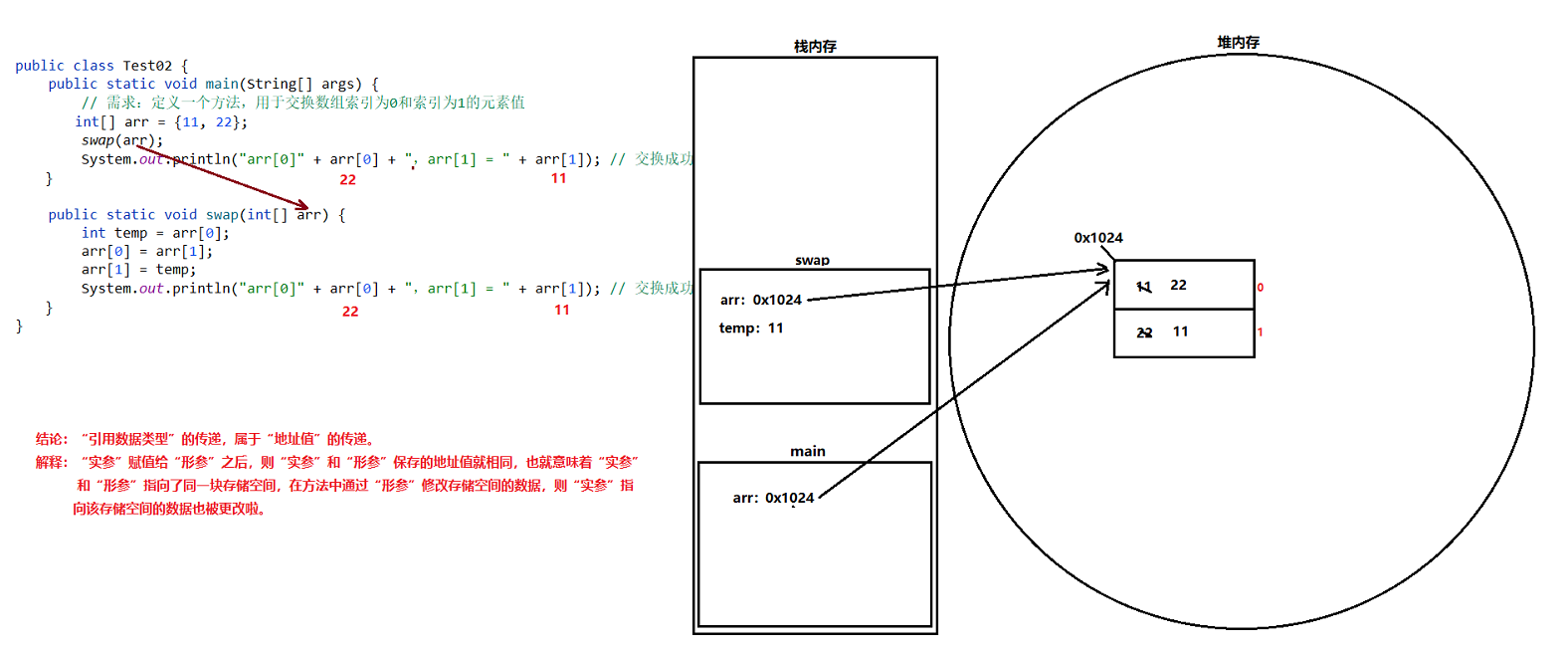
调用方法时,引用数据类型的传递
- 结论:”引用数据类型”的传递,属于”地址值”的传递。
- 解释:”实参”赋值给”形参”之后,则”实参”和”形参”保存的地址值就相同,也就意味着”实参”和”形参”指向了同一块存储空间,我们在方法中修改”形参”指向存储空间的数据,则”实参”指向该存储空间的数据也被修改了。
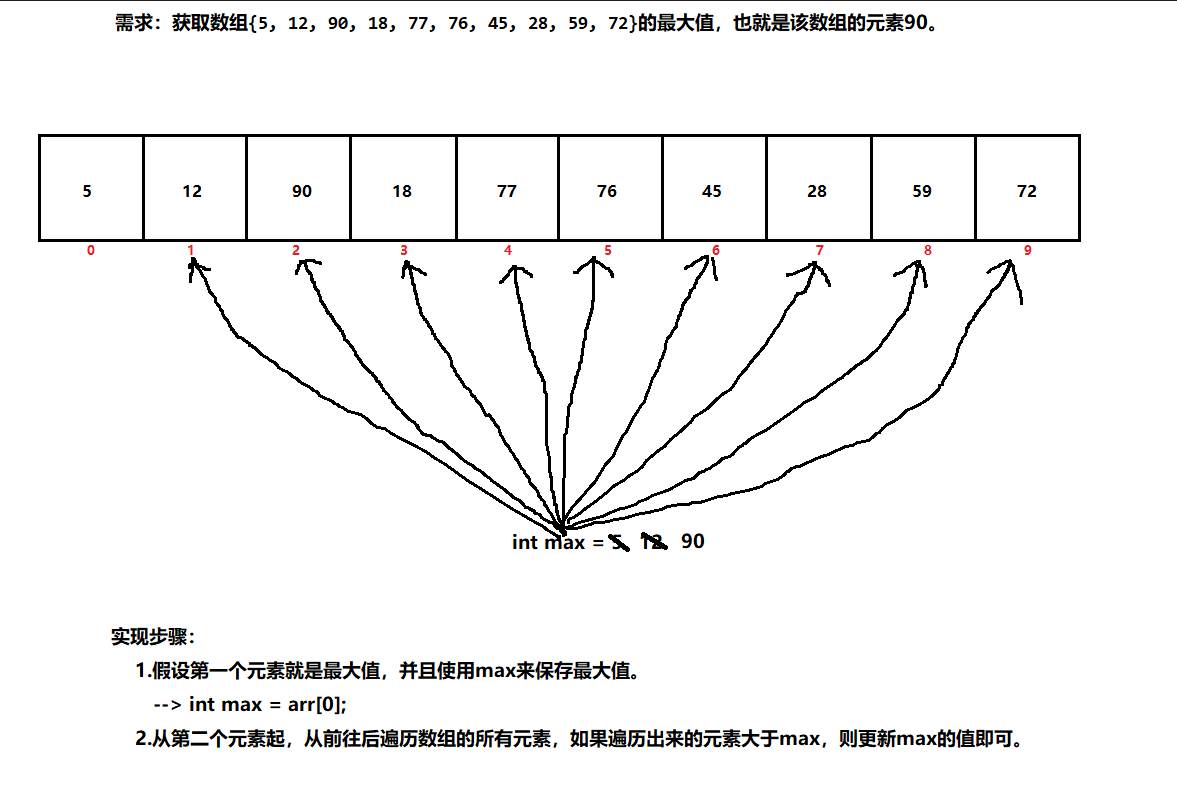
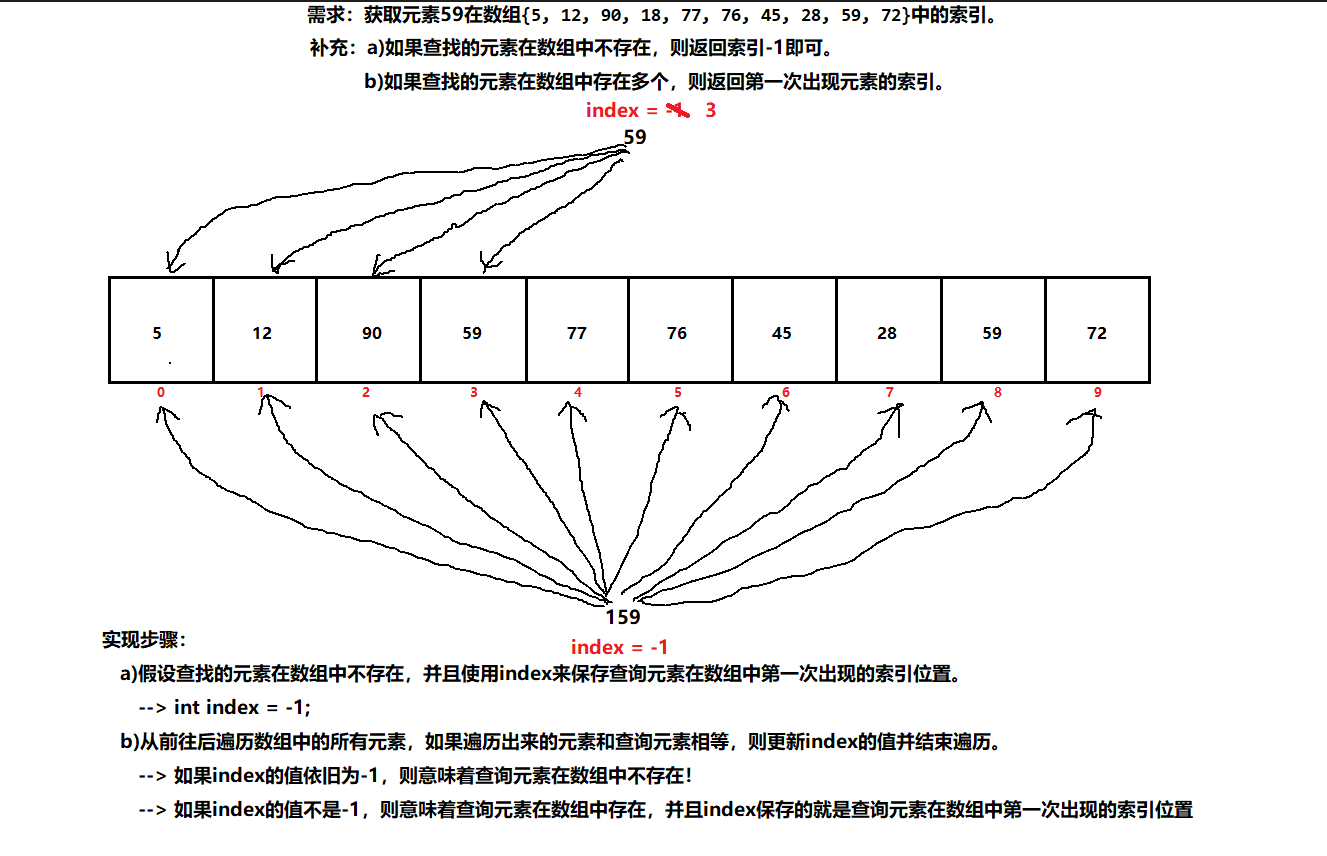
数组例题:
DAY10
数组反转
需求:将数组元素反转,原数组{5, 12, 54,7676,9},反转后为:{9, 676, 54, 12, 5}。
要求:使用两种方式来实现
方式一:创建一个新的数组,用于保存反转之后的结果。
- 缺点:
- 需要创建新的数组,浪费了存储空间。
- 需要完整遍历整个数组,浪费了执行时间。
- 缺点:
方式二:使用“首尾元素交换位置”的思路来实现。
优点:
- 无需创建新的数组,节约了存储空间。
- 只需遍历数组长度的一半,节约了执行时间。
for(int i = 0; i < length/2; i++){ int temp = arr[i]; arr[i] = arr[length - 1 - i]; arr[length -1 -i] = temp; }
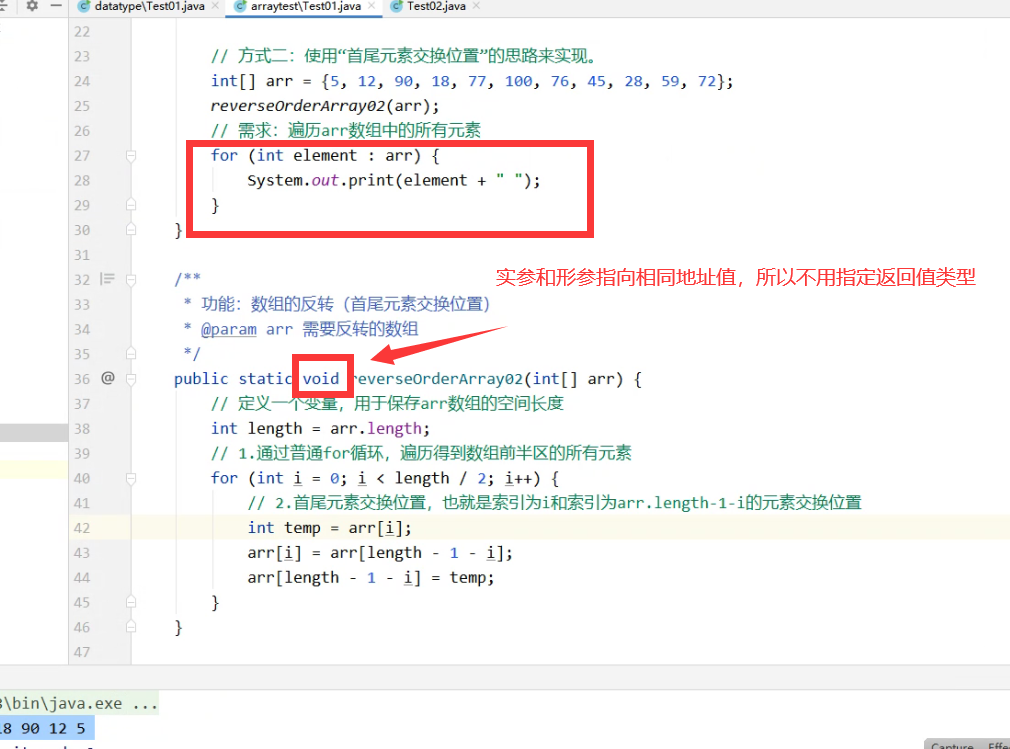
什么是静态方法
- 使用static关键字修饰的方法,我们就称之为“静态方法”。
静态方法的调用:
情况一:调用“当前类”的静态方法
–> 语法:方法名(实参列表);
情况二:调用“别的类”的静态方法
–> 语法:类名.方法名(实参列表);
数组工具类
- 问题:在前面的学习中,我们把操作数组的静态方法放到了不同的类中,因此想要调用这些静态方法的时候,我们首先得明确该方法在那个类中,然后才能通过“类名”来调用这些静态方法,因此调用这些方法的时候非常不方便。
- 解决:定义一个“数组工具类”,然后把操作数组的静态方法都放到该“数组工具类”中。
Arrays工具类的概述
- Arrays工具类在”java.util”包中,因此我们使用Arrays工具类的时候,必须通过import关键字导入Arrays类,然后才能使用Arrays工具类。
- Arrays工具类我们称之为“数组相关的工具类”,在Arrays类中提供了很多操作数组的“静态方法”,因此我们调用这些方法的时候,直接通过类名.来调用。
Arrays工具类的方法
public static String toString(int[] a){...} //作用:把数组转换为字符串并返回,也就是获得数组中的元素,然后把这些元素拼接成字符串并返回。public static void fill(int[] arr, int val){...} //作用:数组的填充操作,把arr数组中的所有元素设置为valpublic static void sort(int[] arr){...} //作用:给数组元素执行“排序”操作,默认为“升序”排序注意:关于数组的排序算法,我们后面会学习(冒泡排序和选择排序)
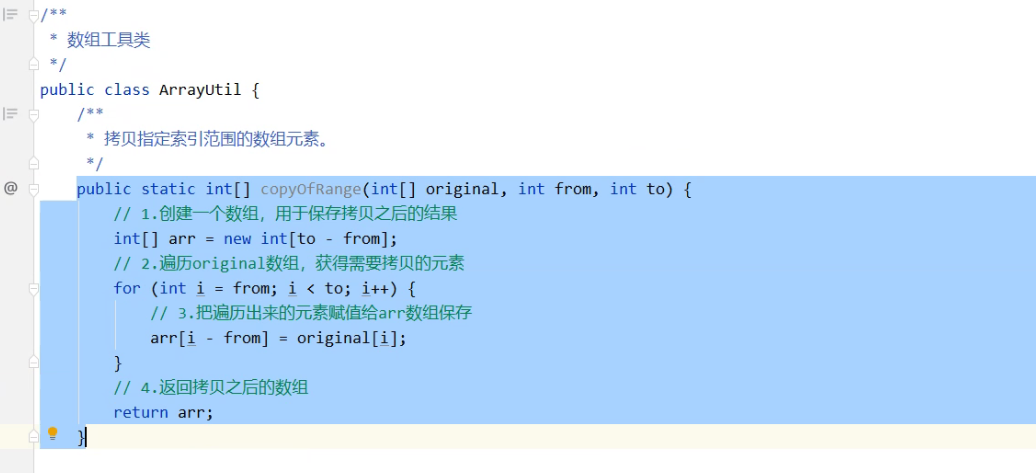
public static void sort(int[] arr, int fromIndex, int toIndex){...} //作用:对“指定范围”的数组元素执行“升序”排序 //范围:从fromIndex索引位置开始(包含),到toIndex索引位置结束(不包含)。 //注意:fromIndex取值范围在[0,数组长度-1]之间,toIndex取值范围在[0,数组长度]之间,并且必须满足toIndex大于fromIndexpublic static void binarySearch(int[] arr, int key){...} /* 作用:二分查找,查询key在arr数组中的索引位置。 返回值:如果查询元素在数组中存在,则返回该元素在数组中的索引位置;如果查询的元素在数组中不存在,则返回负数即可。 */public static int binarySearch(int[] arr, int fromIndex, int toIndex, int key){...} /* 作用:对“指定范围”的数组元素执行二分查找操作,此处要求arr数组为升序排序。 范围;从fromIndex索引位置开始(包含),到toIndex索引位置结束(不包含)。 注意:fromIndex取值范围在[0, 数组长度-1],toIndex取值范围在[0,数组长度]之间,并且必须满足toIndex大于fromIndex。 返回值:如果查询元素在数组中存在,则返回该元素在数组中的索引位置;如果查询的元素在数组中不存在,则返回负数即可。 */public static int[] copyOf(int[] original, int newLength){...} /* 作用:从索引为0的位置开始拷贝,一共拷贝newLength个数组元素并返回。 注意:此处newLength取值范围在[0,数组长度]之间。 */Public static int[] copyOfRange(int[] original, int from, int to){...} /* 作用:拷贝指定索引范围的数组元素 范围:从from索引位置开始(包含),到to索引位置结束(不包含)。 注意:from取值范围在[0,数组长度 - 1]之间,to取值范围在[0,数组长度]之间,并且必须满足to大于from */
public static boolean equals(int[] arr1, int[] arr2){...}
/*
作用:判断arr1和arr2两个数组是否相等。
返回值:如果arr1和arr2的地址值相等或arr1和arr2的数组元素一一对应,则都返回true,否则一律返回false。
*/3.什么是数组拷贝?
- 把A数组中的元素拷贝进入B数组中,则我们修改A数组的元素,那么B数组中的元素不会被修改,这就是数组的拷贝操作。
//需求:把arr1数组前3个元素拷贝进入arr2数组中
int[] arr1 = {11,22,33,44,55};
int[] arr2 = Arrays.copyOf(arr1,3);
System.out.println(arr2); //输出:[11,22,33]问题:查询某个元素在数组中的索引位置,则实现方案有哪些?
方式一:顺序查找(线性查找)
–> 优点:对数组元素是否排序没有要求!
–> 缺点:查询效率非常低!
方式二:二分查找(折半查找)
–> 优点:查询效率非常高
–> 缺点:要求数组元素必须排序,默认为升序排序。
方法的可变参数(掌握)
1、可变参数的引入
需求:定义一个方法,用于获得指定两个int类型数据之和。
实现:
public static int add(int num1, int num2){...}需求:定义一个方法,用于获得任意多个int类型数据之和(至少有两个int类型的数据)
实现1:使用“方法的重载”来实现。
–> 理论上没有问题,但是实际操作有问题。
实现2:
public static int add(int num1, int num2, int[] arr){...}–>使用“数组”来实现虽然可行,但是不太符合题意。
实现3:
public static int add(int num1, int num2, int ... arr){...}–> 使用“方法的可变参数”来实现,该方式是最优的解决方案。
可变参数的语法
- 语法:数据类型 … 可变参数名
- eg:int … arr
可变参数的注意点
“可变参数”必须存在于“形参列表”中,并且“可变参数”必须在形参列表“最末尾”。
–> 也就是说,方法的形参列表中最多只能定义一个可变参数(0或1)
在方法体中,我们可以把可变参数当成“数组”来使用,本质上可变参数就是数组的另外一种语法表现形式。
–> eg:调用方法的是,实参为”int类型的数组”,则方法的形参可以为“int类型的可变参数”。
–>调用方法:
int sum = add(1,2,new int[]{1,2,3,4,5});–> 声明方法:
public static in add(int num1, int num2, int ... arr){...}eg:在同个类中,以下两个同名的方法发生了编译错误,因为这两个方法没有构成方法的重载!
public static int add(int num1, int num2, int ... arr){...} public static int add(int num1, int num2, int[] ... arr){...}调用拥有可变参数的方法时,则实参和形参的“个数”不必相同,但是实参和形参的“类型”必须相同。
可变参数的使用场合
- 定义一个方法的时候,参数的类型都相同,但是参数的个数不确定时。
数组的核心特点
- 数组是一块连续的存储空间,则意味着相邻两个元素的存储空间是紧挨着的。
- 数组存储的是相同数据类型的元素,则意味着每个元素占用的字节数相同。
- 常见数组则必须明确数组的空间长度,数组一旦创建成功,则数组的空间长度就不能改变。
根据索引操作【改和查】
结论:根据索引操作元素效率非常高,甚至是所有数据结构中效率最高的。
依据:数组是一块连续的存储空间,则意味着相邻两个元素的存储空间是紧挨着。
–> 数组存储的是相同数据类型的元素,则意味着每个元素占用的字节数相同。
–> 寻址公式:首地址 + 索引值 * 每个元素占用的字节数

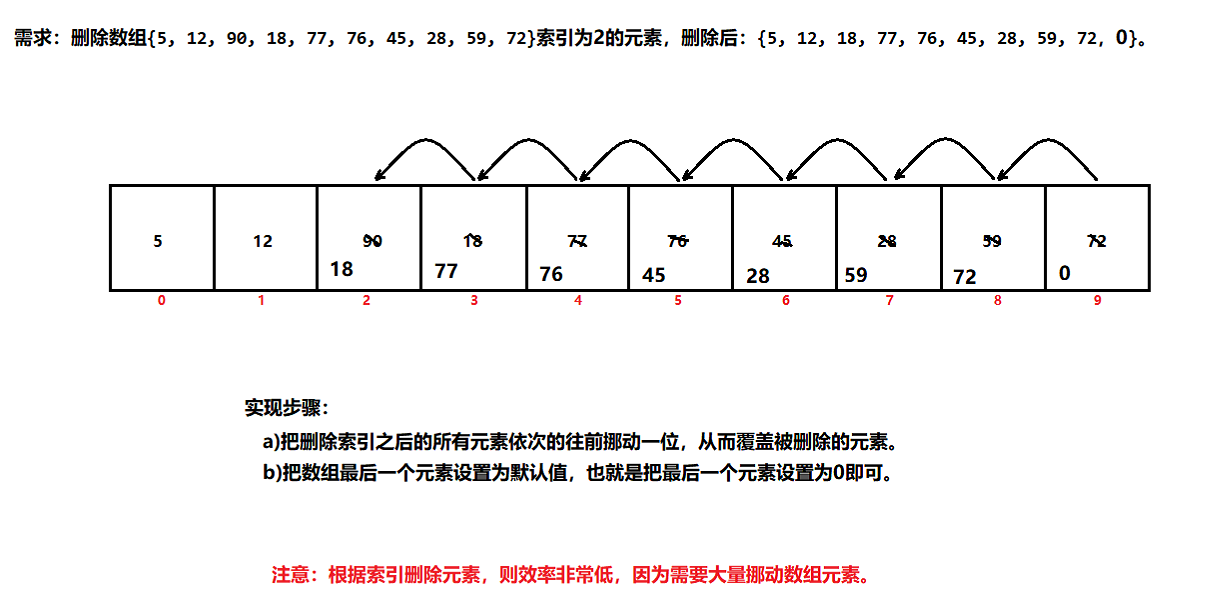
根据索引删除元素【删】
结论:根据索引删除元素的效率非常低,因为需要大量的挪动数组元素。
依据:数组是一块连续的存储空间,则意味着相邻两个元素的存储空间是紧挨着。
–> 常见数组则必须明确数组的空间长度,数组一旦创建成功,则数组的空间长度就不能改变了。
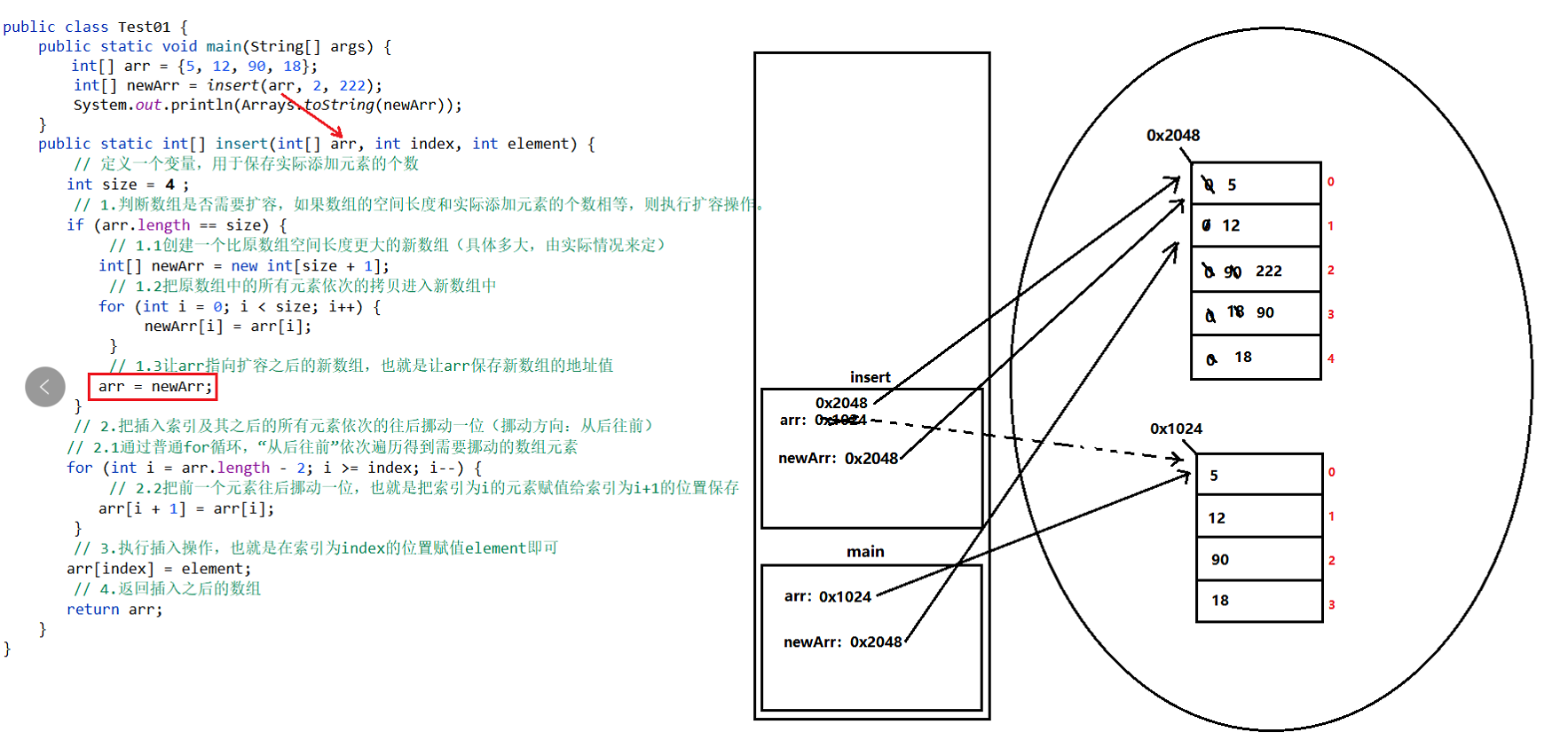
根据索引插入元素【增】
结论:根据索引插入元素的效率非常低,因为需要大量挪动数组元素+扩容操作。
依据:数组时一块连续的存储空间,则意味着相邻两个元素的存储空间时紧挨着。
–> 常见数组则必须明确数组的空间长度,数组一旦创建成功,则数组的空间长度就不能改变啦。
DAY11
二维数组(矩阵,很难,了解)
二维数组的定义
数组中的每个元素都是一堆数组,这样的数组我们就称之为“二维数组”。
eg:
{{11,22,33}, {21,22,23}}
二维数组的声明
明确:所谓二维数组的声明,指的就是给二维数组取一个名字,类似于“变量的声明”。
语法1:
//数据类型[][] 数组名; //int[][] arr1; //String[][] arr2;语法2:
//数据类型[] 数组名[]; //int[] arr1[] //String[] arr2[]注意:实际开发中,我们建议使用”语法1”来声明二维数组,因为“数据类型 [ ] [ ] ”代表的是“二维数组类型”。
二维数组的创建
明确:所谓二维数组的创建,指的就是在堆内存中为二维数组开辟存储空间。
方式一:创建“等长”的二维数组(动态)
//语法:数据类型[][] 数组名 = new 数据类型[m][n]; // m: 设置二维数组得空间长度 //n:设置一维数组的空间长度 int[][] arr1 = new int[3][3]; String[][] arr2 = new String[3][4];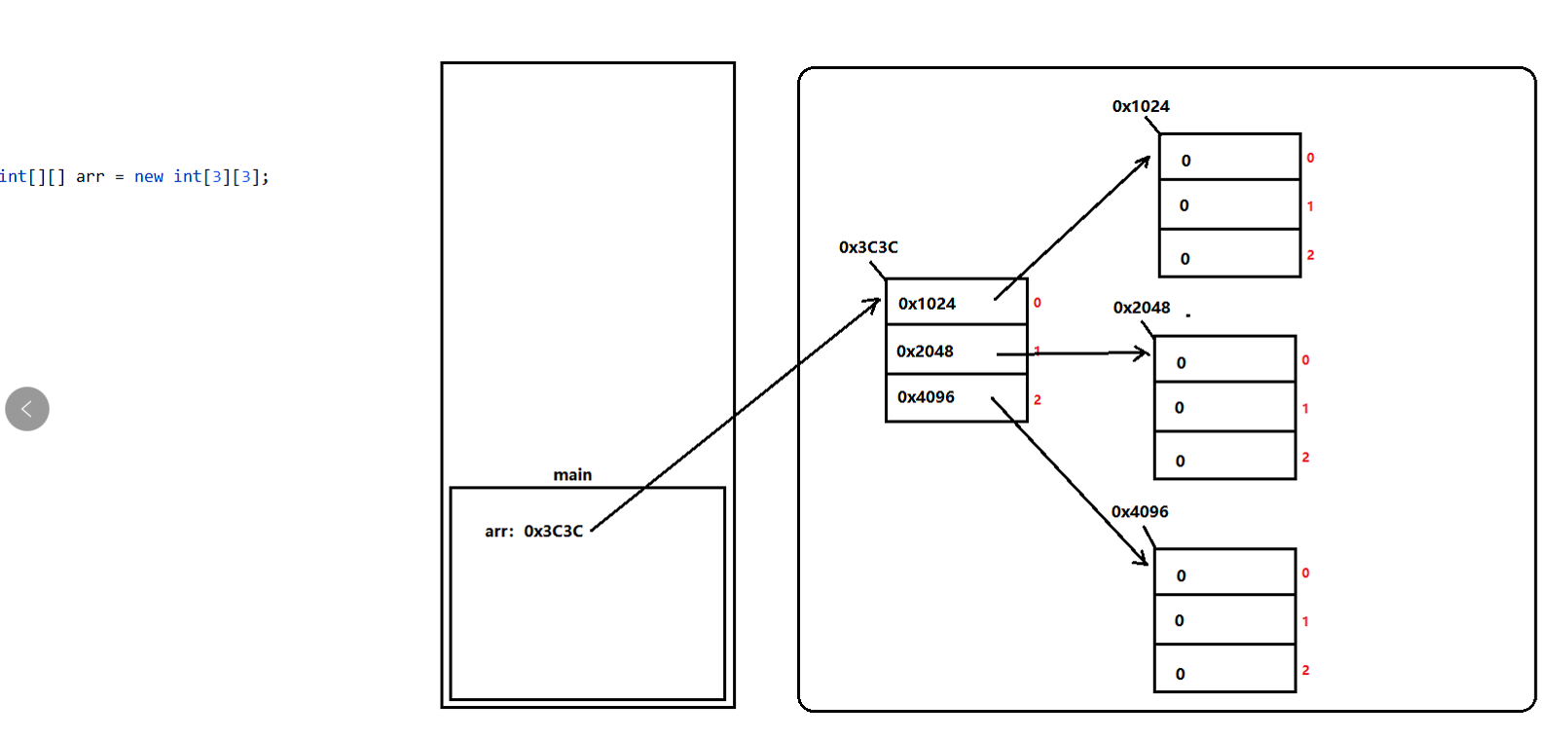
方式二:创建“不等长”的二维数组(动态)
//语法:数据类型[][] 数组名 = new 数据类型[m][]; //m:设置二维数组的空间长度 int[][] arr1 = new int[3][]; String[][] arr2 = new String[4][];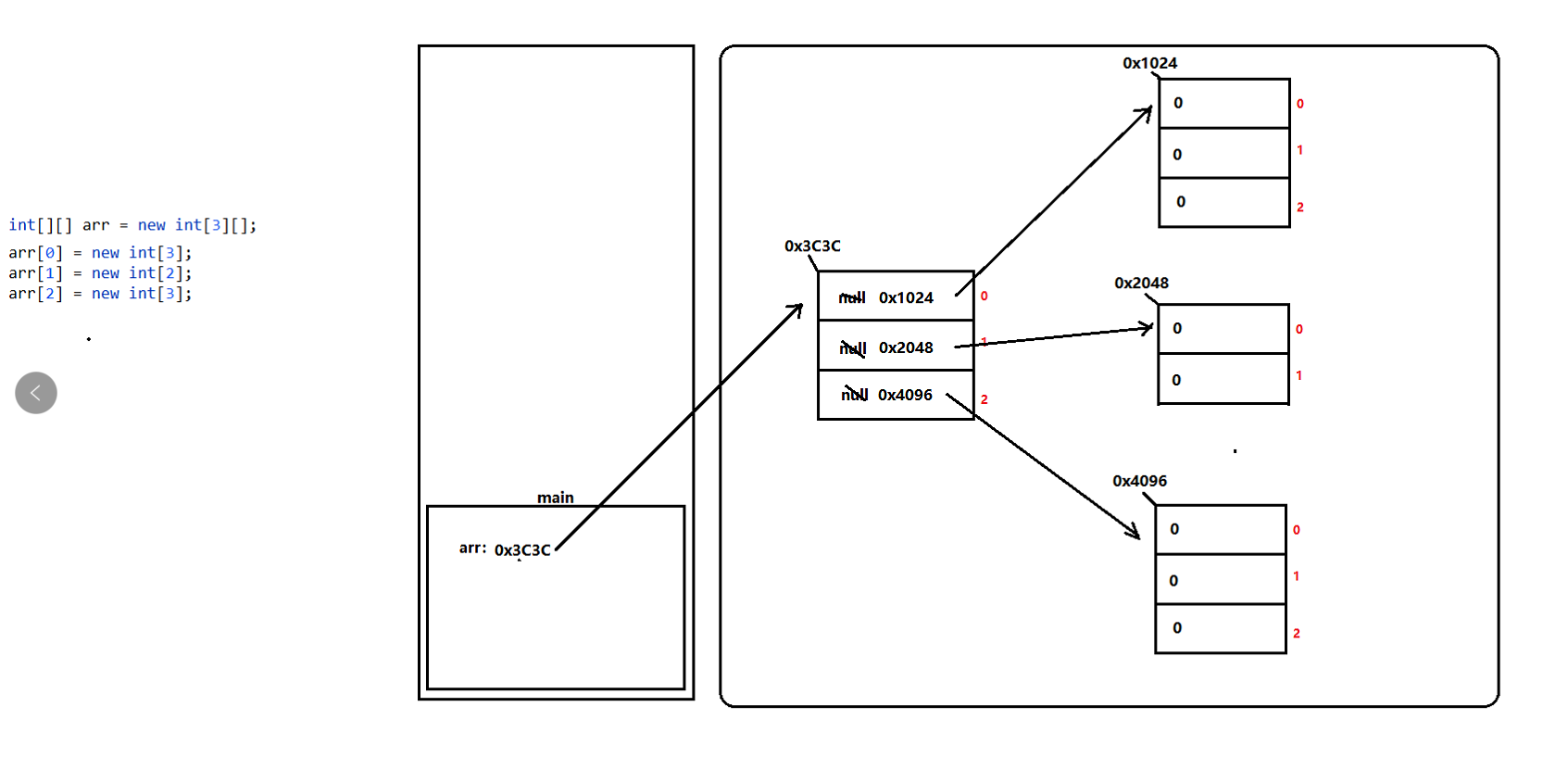
方式三:静态创建的二维数组(静态)(等长|不等长)
–> 语法1:
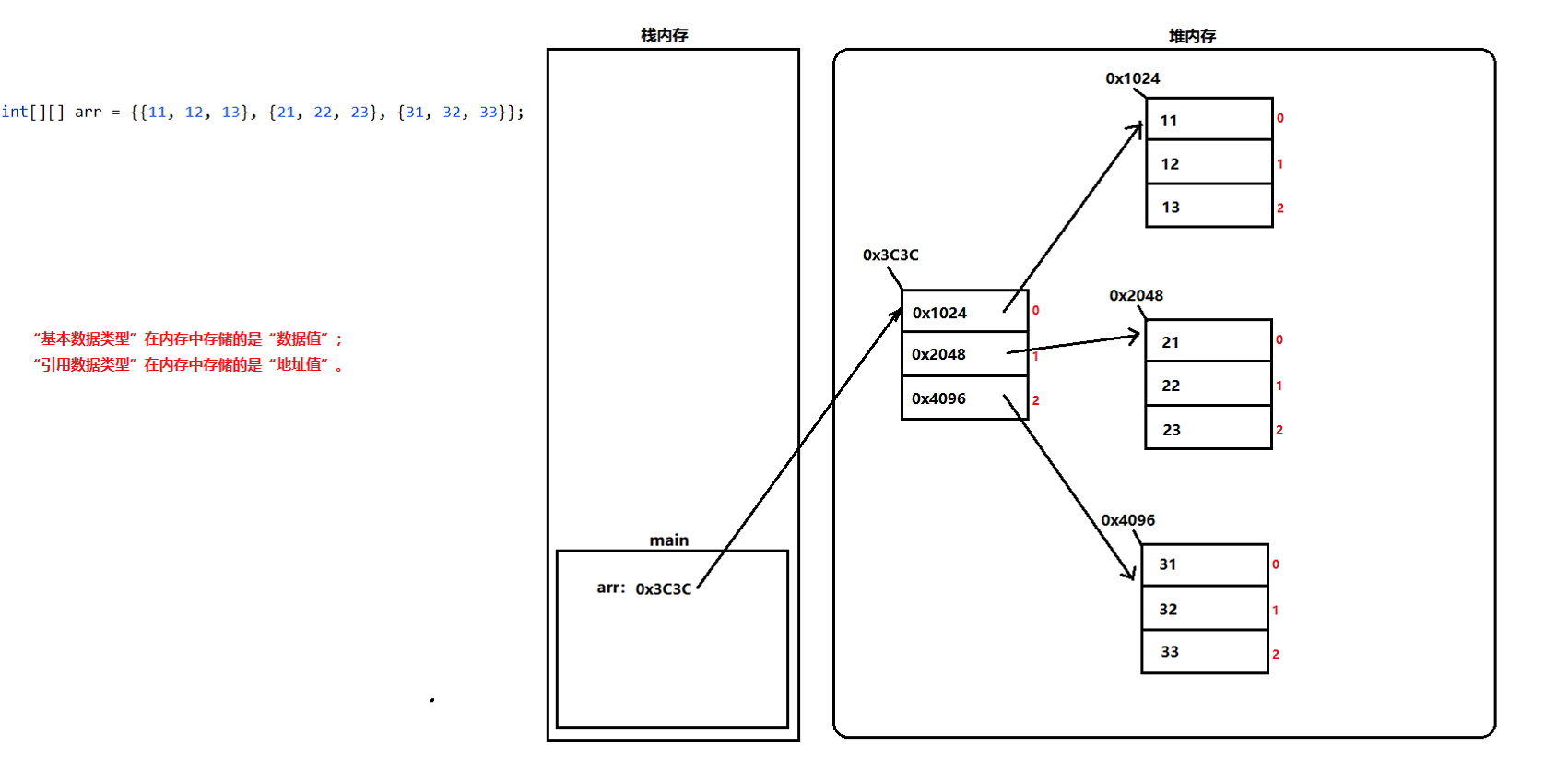
//数据类型[][] 数组名 = {{数据1,数据2}, {数据3,数据4},...} //int[][] arr1 = {{11,22,33},{55,66,77},{13,56,78}}; //String[][] arr2 = {{"aa","bb"},{"cc","dd","yt"}};–>语法2:
//数据类型[][] 数组名 = new 数据类型[][]{{数据1,数据2}, {数据3,数据4},...}; ////int[][] arr1 = new int[][]{{11,22,33},{55,66,77},{13,56,78}}; //String[][] arr2 = new String[][]{{"aa","bb"},{"cc","dd","yt"}};注意:通过大括号创建出来的二维数组,我们无法直接作为方法的”实参”和”返回值”,因为编译器不认识大括号创建的二维数组。
断点调试(debug调试,重点)
debug调试的作用
- 查看代码的执行顺序,分析变量值的变化,从而找到问题的并解决问题。
debug的调试步骤
第一步:在代码可能出现问题的位置,我们在该位置打一个断点。
–> 在该代码行号左侧位置,我们单击打一个断点(红色圆圈)
第二步:开启debug调试来执行程序,则代码就会停留在打断点的位置。
–>方式一: 点击类名或main方法左侧绿色按钮,然后选中”Debug Xxx.main()”即可。
–> 方式二:在代码编辑区域,我们鼠标右键然后选中”Debug Xxx.main()”即可。
–> 方式三:已经执行程序后,我们点击工具栏或控制台左侧的”debug按钮”。
明确:开启debug调试之后,则就会出现debug窗口,debug窗口的作用如下:
Debugger
- Frames:显示代码停留的位置(包、类、方法和行号)
- Variables:显示当前方法已经执行过的变量的值
Console
- 显示输出的内容或获取输入的内容。
第三步:控制代码的执行,也就是通过Debug窗口来控制代码的执行。
- F8:执行下一行代码。
- F7:进入执行方法体中的代码。
- shift + F8:结束当前方法,回到方法的调用位置。
- Alt + F9:直接执行到下一个断点的位置。
- Alt + F8:计算并执行某行未执行代码的运算结果。
第四步:结束debug调试。
首先,取消断点(单击取消);然后,结束程序(点击红色按钮);最后,关闭debug窗口。
面向过程
封装(堆功能method的封装)
典型:c语言
特点:以线性的思维来思考解决问题,强调一步一步的实现。
–> 强调程序员是一个“实施者”,类似于公司中的“小职员”。
优点:效率高。
缺点:程序的复用性、可维护性和可扩展性较低。
使用场合:适用于“小型”的程序,例如:计算器、嵌入式开发等等
面向对象
封装(对数据field和功能method做的封装)、继承和多态。
典型:C++、C#、java等。
特点:以非线性的思维来思考解决问题,强调宏观上的把控。
–> 强调程序员是一个“指挥官”,类似于公司中的“小老板”。
优点:程序的复用性、可维护性和可扩展性较高。
缺点:效率低。
使用场合:适用于“大型”的程序,例如:京东、淘宝、微信等等。
面向对象编程的特点
- 宏观上采用面向对象的思维来把控,微观实施上依旧采用的是面向过程,即:面向对象中包含了面向过程。
类和对象(理解)
对象(instance)
- 从编程的角度来理解:万物皆对象。
- eg:教室里面的每个学生、每个凳子、每张椅子。。。
- 每个对象都是“独一无二”的,类似于每个同学都是“独一无二”的。
类(class)
- 从编程的角度来理解:类就是对一类事物的抽象,抽象就是提取这一类事物的共同属性和行为,这样就形成了类。
- eg:班上的每个同学都有姓名、年龄和成绩等属性,每个同学都有吃饭、睡觉和学习等行为,则我们对班上的同学进行向上提取,那么就得到了学生类。
类和对象
从编程的角度来分析:我们以类为模板,然后实例化出对象。
–> 先有类,后有对象。
–> 类是对象的模板,对象是类的实例。
eg:我们以小汽车图纸(类)为模板,然后生产出一辆一辆的小汽车(对象)。
如何定义类
语法:[修饰类] class类名{ //书写的代码 }
注意:
- 使用class关键字修饰的就是类,也就是类必须使用class来修饰。
- 类名必须满足“标识符”的命名规则,必须满足“大驼峰”的命名规范,并且最好“见名知意”。
- 使用“public”关键字修饰的类,则类名必须和源文件名字保持一致,否则就会出现编译错误。
类中的组成
- 数据(属性),我们使用“变量”来存储类中封装的数据,类中的变量有:
- 成员变量:又称之为“实例变量”或“非静态变量”,因为是从属于“对象”的。
- 静态变量:又称之为“类变量”,从属于“类”的。
- 功能(行为),我们使用“方法”来封装类中的功能。
- 成员方法,又称之为“实例方法”或“非静态方法”,从属于“对象”的。
- 静态方法,又称之为“类方法”,从属于“类”的。
成员变量的概述
定义位置:在类中,代码块和方法体之外。
定义语法:[修饰符] 数据类型 变量名;
–>定义成员变量的时候,则不允许使用static关键字来修饰。
操作成员变量的语法:对象.成员变量名
–> 通过 “对象.成员变量名” 就能找到该成员变量的存储空间,然后就能对该成员变量取值和赋值的操作。
–> 在成员方法中,想要操作当前类的成员变量,则我们可以直接通过“成员变量名”来操作。
成员方法的概述
定义位置:在类中,代码块和方法体之外。
定义语法:
[修饰符] 返回值类型 方法名(形参列表){ //方法体 return [返回值]; }–> 定义成员方法的时候,则不允许使用static关键字来修饰。
调用成员方法的语法:对象.成员变量名(实参列表);
–> 注意:在成员方法中,想要调用当前类的成员方法,则我们可以直接通过“成员变量名(实参列表);”来实现。
实例化对象的概述
语法:
类型 对象 = new 类名(实参列表); //eg: Student stu = new Student(); Scanner input = new Scanner(System.in);理解:我们以类为模板,然后实例化对象。
成员变量的默认值
- 明确:“成员变量”和“数组元素”都有默认值,并且默认值规则一样。
- 整数型(byte、short、int和long)成员变量的默认值为:0;
- 浮点型(float和double)成员变量的默认值为:0.0;
- 布尔型(boolean)成员变量的默认值为:false;
- 字符型(char)成员变量的默认值为:’\u0000’ –> 代表的是空格字符
- 引用数据类型(数组、字符串、类和接口等等)成员变量的默认值为:null
成员变量的初始化
- 最先执行“默认初始化”,然后执行“显示初始化”,最后执行“指定初始化”。
创建对象时的内存分析
- 结论:以类为模板来创建对象,则只需要为类中的成员变量在堆内存中开辟存储空间,而成员方法是调用的时候自动在栈内存中开辟栈帧。
- 注意:每个对象都是“独一无二”的,因为每次创建对象都会在堆内存中开辟存储空间。
成员变量和局部变量的对比
- 定义位置区别
- 成员变量:在类中,代码块和方法体之外。
- 局部变量:在类中,代码块或方法体之内。
- 存储位置区别
- 成员变量:存储在“堆内存”中。
- 局部变量:存储在“栈内存”中。
- 生命周期区别
- 成员变量:随着对象的创建而“出生”,随着对象的销毁而“死亡”。
- 局部变量:定义变量的时候“出生”,所在作用域执行完毕就“死亡”。
- 默认值的区别
- 成员变量:成员变量有默认值,并且默认值规则和数组元素默认值规则一模一样。
- 局部变量:局部变量没有默认值,因为只声明未赋值的局部变量,则不能做取值操作。
- 修饰符的区别
- 成员变量:可以被public、protected、private、static、final等修饰符修饰。
- 局部变量不能被public、protected、private、static修饰,只能被final修饰。
成员变量和局部变量的使用
明确:当成员变量和局部变量同名的时候,则默认采用的是“就近原则”,也就是“谁离的近,就执行谁”。
问题:当成员变量和局部变量同名的时候,我们该如何区分?
解决:局部变量采用“就近原则”来区分,成员变量使用“this”关键字来区分。
System.out.println("局部变量:" + name); System.out.println("成员变量:" + this.name);
我们通过new关键字来创建对象,则创建出来的对象分为两种
匿名对象,指的就是“没有名字的对象”,例如:new Tiger();
非匿名对象,指的就是“有名字的对象”,例如:Tiger tiger = new Tiger();
开发中,匿名对象很少使用,但是以下两种场合建议使用匿名对象来实现。
创建出来的对象,仅仅只调用一次成员方法,则该对象就建议使用匿名对象来实现。
new Tiger().eat("XXX");创建出来的对象,仅仅只作为方法的实参,则该对象就建议使用匿名对象来实现。
show(new Tiger);
DAY12
构造方法(构造器或构造函数)
构造方法的引入
Student stu = new Student(); Scanner input = new Scanner(System.in);构造方法得语法
语法:
[修饰符] 类名(形参列表){ //方法体 }注意:【构造方法的特点】
构造方法中没有“返回值类型”,因为在构造方法中不允许有“返回值”。
–> 构造方法中没有“返回值”,则构造方法中只有“return;”,那么我们就省略”return;”。
构造方法的名字必须为“类名”,也就是构造方法名采用”大驼峰”来命名。
–> 构造方法名采用“大驼峰”,而成员方法名和静态方法名采用“小驼峰”。
构造方法就是一个“特殊”的方法,并且构造方法应该通过new关键字来调用。
构造方法专门给成员变量做初始化,也就是构造方法不为静态变量做初始化。
构造方法可以没有(默认一个无参构造方法),也可以有多个构造方法,他们之间构成重载关系。
如果定义有参构造方法,则无参构造方法被自动屏蔽。
构造方法不能被继承。
构造方法不能手动调用,在创建类实例的时候自动调用构造方法。
创建对象的步骤
分析“new Student();”的执行顺序,也就是分析创建对象的执行步骤:
- 创建对象,并给成员变量开辟存储空间;
- 给成员变量做“默认初始化”;
- 给成员变量做“显式初始化”;
- 调用构造方法,给成员变量做“指定初始化”。
创建对象的时候,是谁来完成的呢?
- new关键字负责创建对象,构造方法负责给成员变量做指定初始化操作,创建对象的时候new关键字和构造方法缺一不可。
构造方法的作用
- 创建对象的时候new关键字和构造方法缺一不可(了解)。
- 通过构造方法来给成员变量做指定初始化操作,从而实现代码的复用【核心】。
无参构造方法的概述
- 作用:用于给成员变量做初始化操作,例如在无参构造方法中给int类型数组做开辟存储空间的操作。
- 注意:如果某个类中没有显式地提供构造方法,则程序编译时会默认为这个类提供一个无参构造方法。
有参构造方法的概述
- 作用:用于给成员变量做初始化操作,例如在有参构造方法中我们将形参的值赋值给成员变量来保存。
- 注意:
- 建议形参的名字和成员变量名保持一致,然后在构造方法中通过this来操作成员变量。
- 如果一个类显式地提供了构造方法,则程序编译时就不会为该类提供默认的无参构造方法了。
- 建议每个类都应该提供无参构造方法,避免在继承体系中子类找不到父类的无参构造方法。
构造方法的重载
- 构造方法依旧可以实现方法的重载,调用构造方法的时候会根据实参的“个数”和“类型”来选中调用合适的构造方法。
成员方法和构造方法的对比
定义语法区别
- 成员方法:
[修饰符] 返回值类型 方法名(形参列表){ //方法体 return [返回值]; }构造方法:
[修饰符] 类名(形参列表){ //方法体 }
调用方式区别
- 成员方法:必须通过“对象”来调用;
- 构造方法:必须通过“new”关键字来调用;
调用时期区别
- 成员方法:对象创建完毕后调用。
- 构造方法:创建对象的时候调用。
调用次数区别
- 成员方法:对象创建完毕后,我们可以调用任意多次成员方法(n)。
- 构造方法:构造方法只能调用一次,每次创建对象,则都会调用一次构造方法(1)。
成员方法和构造方法的特点
- 执行到构造方法中,则此时对象肯定创建完毕,也就意味着构造方法有对象。
- 也就是说,成员方法和构造方法中都有对象,也就意味着成员方法和构造方法中都有this。
this关键字(重点)
this关键字的概述
- 创建一个对象成功之后,则虚拟机就会动态地创建一个引用,该引用指向的就是新创建出来的对象,并且该引用的名字就是this。
this关键字指的是什么?
在构造方法中,this指的是什么?
在构造方法中,this指的是“新创建出来的对象”。
在成员方法中,this指的是什么?
在成员方法中,this指的是“方法的调用者对象”。
this关键字的作用
操作成员变量,语法:对象.成员变量名
- 如果成员变量和局部变量的名字相同,则我们必须通过this关键字来操作成员变量,使用就近原则来操作局部变量。
- 如果成员变量和局部变量的名字不同,则我们可以通过this关键字来操作成员变量,也可以忽略this关键字来操作成员变量。
- –> 忽略this关键字来操作成员变量,则编译时会默认添加this关键字来操作。
调用成员方法,语法:对象.成员变量名(实参列表);
调用当前类的别的成员方法时,我们可以通过this关键字来调用,也可以忽略this关键字来调用。
–> 忽略this关键字来调用成员方法,则编译时会默认添加this关键字来操作。
调用构造方法,语法:this(实参列表);
作用:调用“当前类”的别的构造方法,此处仅仅调用方法并不创建对象,从而实现了代码的复用。
注意:
“this(实参列表)”只能存在于构造方法中,并且必须在构造方法有效代码的第一行。
–> “this(实参列表)”必须在构造方法有效代码的第一行,则意味着一个构造方法中最多只能有一个“this(实参列表)”。(0或1)
构造方法切记不能“递归”调用,否则就会陷入死循环,从而造成程序编译错误!
–> 在构造方法中,我们不允许通过“this(实参列表)”来自己调用自己,否则就会编译错误!
在一个类中,不可能所有的构造方法中都存在“this(实参列表)”,因为这样肯定会陷入死循环。
–> 一个类中,可以定义多个构造方法,但是至少有一个构造方法中没有“this(实参列表)”。
静态变量(重点)
静态变量的引入
- 需求:班上所有同学的姓名、年龄和成绩等属性,并且所有的学生都共享同一个教室和饮水机。
- 解决:定义一个Student类,然后在Student类中定义姓名、年龄、成绩、教室和饮水机等成员变量即可。
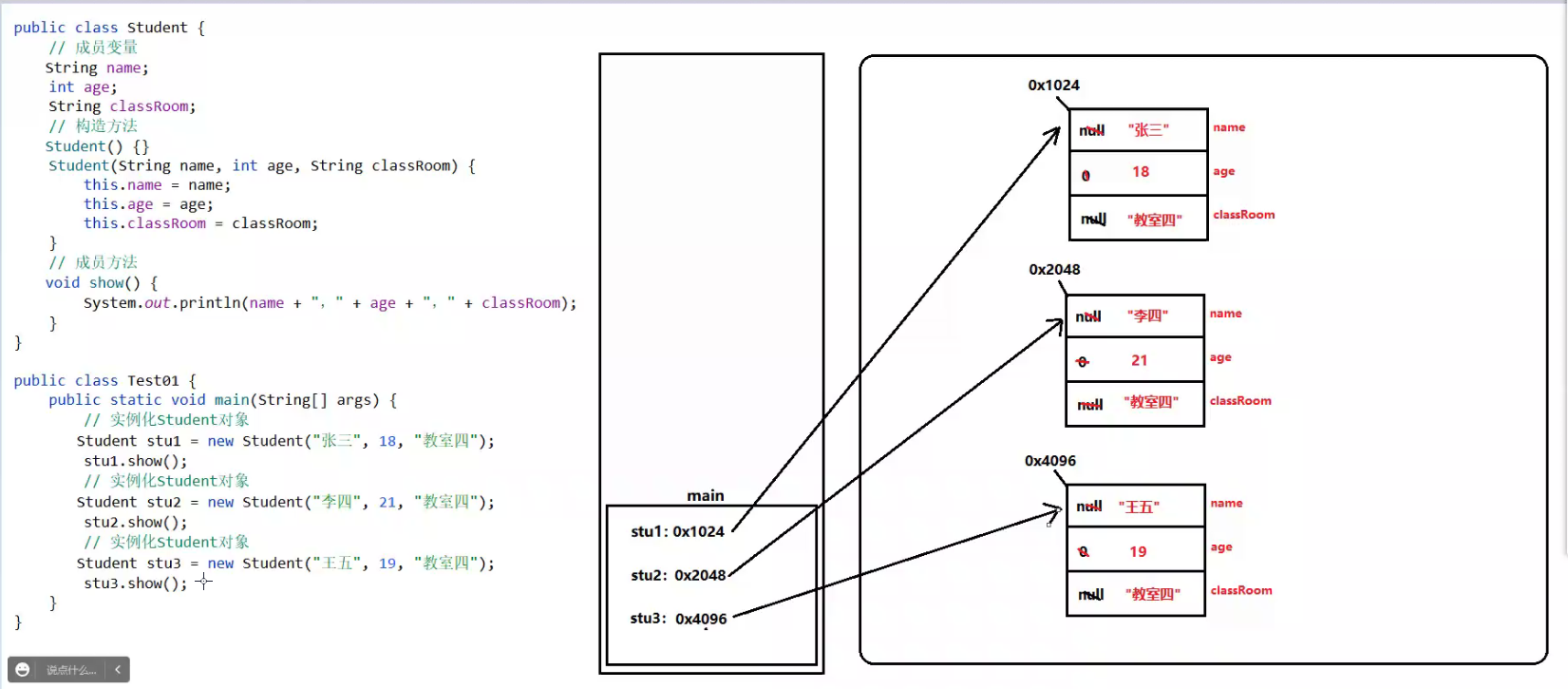
问题:一个班有几十个同学,也就意味着需要创建几十个学生对象,每个学生对象都需要为classRoom开辟存储空间,并且每个对象存储的内容都相同,则浪费了存储空间。
解决:把姓名、年龄和成绩使用“成员变量”来保存;把教室和饮水机使用“静态变量”来存储。
–> 如果存储的是“特有数据”,则就使用“成员变量”来存储,例如:姓名、年龄和成绩就属于学生特有数据,那么就使用成员变量来存储。
–> 如果存储的是“共享数据”,则就使用“静态变量”来存储,例如:教室和饮水机就属于学生的共享数据,那么就使用静态变量来存储。
静态变量的概述
在类中,代码块和方法体之外,使用static关键字修饰的变量,我们就称之为“静态变量”。
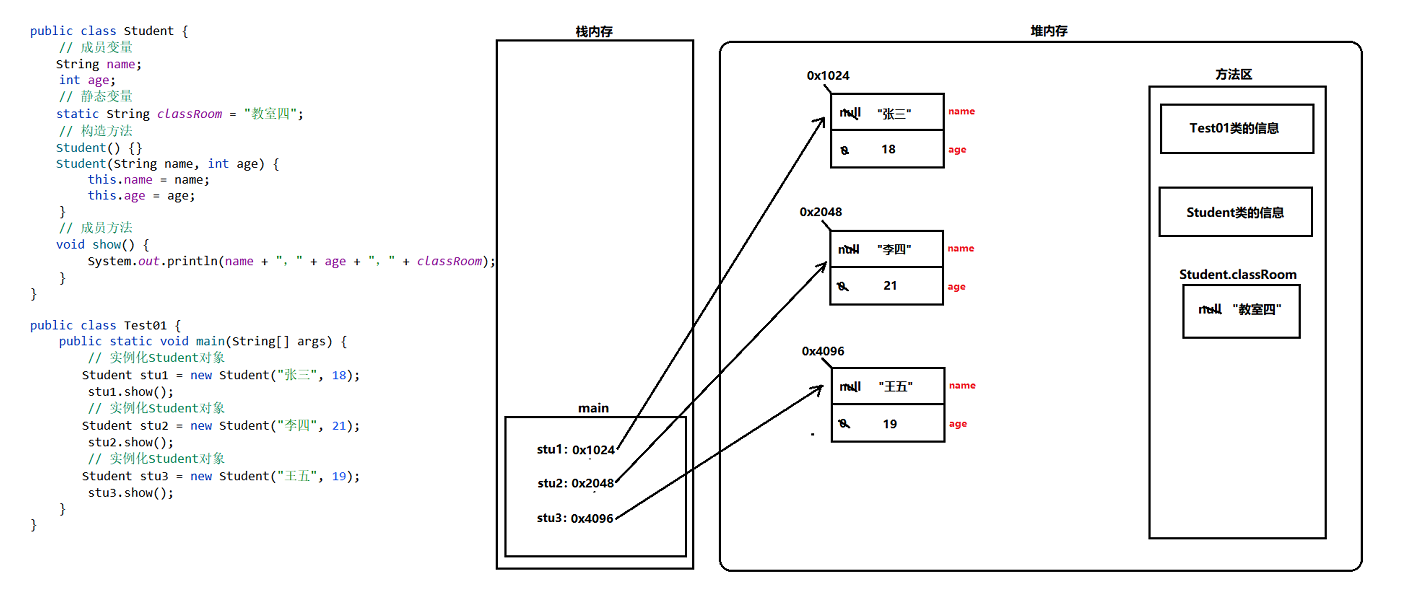
类的加载过程分析
第一次使用某个类的时候,就会加载该类的信息进入方法区,如果该类中存在静态变量,则还会在方法区中为该静态变量开辟存储空间并设置默认值。
问题1:什么时候执行加载类的操作呢?
–> 第一次使用某个类的时候,则就会执行加载类的操作。
问题2:一个类会加载几次呢?
–> 每个类都只会加载一次,因为第一次使用某个类的时候就执行加载类的操作。
问题3:什么是方法区?方法区存储的内容是什么??
–> 方法区就是一块存储空间,并且方法区属于堆内存中的一部分,方法区用于存储类的信息、静态变量等等内容。
问题4:静态变量什么时候开辟存储空间呢?
–> 加载类的时候,则就会把该类中的静态变量在方法区中开辟存储空间,也就意味着静态变量优先于对象存在。
问题5:一个类中的静态变量,会开辟几次存储空间?
–> 因为类只会加载一次,因此每个类中的静态变量就只有一份,也就是每个静态变量只会开辟一次存储空间。
问题6:静态变量的默认值是什么?
–> 静态变量和成员变量都有默认值,并且他们的默认值规则一模一样。
静态变量的特点
静态变量优先于对象存在,随着类的加载就已经存在了。
一个类中,每个静态变量都只有一份,为类和对象所共享。
我们可以通过“类名”来操作静态变量,也可以通过“对象”来操作静态变量。
语法1:类名.静态变量 –> 建议
语法2:对象.静态变量 –> 不建议
成员变量和静态变量的对比
存储位置区别
- 成员变量:存储在堆内存中。
- 静态变量:存储在方法区中。
生命周期
- 成员变量:随着对象的创建而“出生”,随着对象的销毁而”死亡”。
- 静态变量:随着类的加载而“出生”,随着程序执行完毕而“死亡”。
创建次数的区别:
- 成员变量:对象创建多少次,则成员变量就创建多少次。
- 静态变量:因为类只会加载一次,因次静态变量就只会创建一次。
调用语法区别
成员变量:必须通过”对象”来调用。
静态变量:可以通过“类名”来调用,也可以通过“对象”来调用。
成员变量和静态变量的使用
- 成员变量:如果存储的是“特有数据”,则就使用成员变量来存储。
- 静态变量:如果存储的是“共享数据”,则就是用静态变量来存储。
什么是静态方法
- 使用static关键字修饰的方法,我们就称之为“静态方法”。
静态方法的特点
- 静态方法优先于对象存在,随着类的加载就已经存在了。
- 静态方法可以通过“对象”来调用,也可以通过“类名”来调用。
- 语法1:类名.静态方法名(实参列表); –> 建议
- 语法2:对象.静态方法名(实参列表); –> 不建议
成员方法和静态方法的对比
操作变量的区别
在成员方法和构造方法中,不但能直接操作当前类的静态变量,还能直接操作当前类的成员变量。
–> 在成员方法中,则意味着对象都创建完毕,也就是意味着肯定加载完毕,那么就能操作当前类的静态变量。
在静态方法中,可以直接去操作当前类的静态变量,但是不能直接操作当前类的成员变量。
–> 在静态方法中,则意味着类已经加载完毕了,但是静态方法中还没有对象。
调用方法的区别
在成员方法和构造方法中,不但能直接调用当前类的静态方法,还能直接调用当前类的成员方法。
–> 在成员方法中,则意味着对象都创建完毕,也就意味着类肯定加载完毕,那么就能调用当前类的静态方法。
在静态方法中,可以直接调用当前类的静态方法,但是不能直接调用当前类成员的方法。
–> 在静态方法中,则意味着类已经加载完毕,但是静态方法中还没有对象。
操作this的区别
- 在成员方法和构造方法中,我们可以直接操作this关键字。
- 在静态方法中,我们不能直接操作this关键字。
注意:操作“成员内容”的时候,默认省略的是“this”;操作“静态内容”的时候,默认省略的是“类名”。
成员方法和静态方法的使用
成员方法:如果在方法体中,想要直接操作当前类的成员变量,则该方法就”必须”是成员方法。
静态方法:如果在方法体中,我们无需操作当前类的成员变量,则该方法就”建议”是静态方法。
–> 工具类中的方法都是静态方法,也就是静态方法常用于工具类中,例如:Arrays、Math等。
DAY12
代码块
什么是代码块
{ }代码块的分类
- 局部代码块
- 静态代码块
- 构造代码块(非静态代码块)
局部代码块的概述
- 定义位置:在类中,代码块或方法体的内部。
- 定义个数:任意多个。
- 执行顺序:从上往下,顺序执行。
- 注意事项:
- 在局部代码块中定义的变量,则该变量就只能在当前作用域中使用,不能在代码块之外使用。
静态代码块的概述
定义位置:在类中,代码块和方法体之外(必须使用static来修饰)。
定义个数:任意多个
执行顺序:从上往下,顺序执行
注意事项:a)加载某个类的时候,就会执行该类中的静态代码块,并且静态代码块只会执行一次。
–>执行时间:加载类的时候,就会执行该类中的静态代码块。
–> 执行次数:因为类只会加载一次,因此静态代码块就只会执行一次。
b)在静态代码块中,我们可以直接操作当前类的静态内容,但是不能直接操作当前类的成员内容和this。
–> 原因:加载类的时候,就会执行该类中的静态代码块,则执行静态代码块的时候对象都还未创建。
c)加载类的时候,静态变量和静态代码块属于“从上往下,顺序执行”,建议把静态变量定义在静态代码块之前。
–> 注意:在静态代码块中,我们“未必”能直接操作当前的静态变量。
d)在静态代码块中定义的变量,则该变量就只能在当前作用域中使用,不能再代码块之外使用。
使用场合:开发中,我们经常再静态代码块中完成对静态变量的初始化操作(常见)。
–>例如:创建工厂、加载数据库初始信息等等。
构造代码块的概述
- 定义位置:在类中,代码块和方法体之外(不能使用static来修饰)
- 定义个数:任意多个
- 执行顺序:从上往下,顺序执行。
- 注意事项:
- 创建对象的时候,则就会执行该类中的构造代码块,对象创建了多少次则构造代码块就执行多少次。
- 执行时间:创建对象的时候,则就会执行该类中的构造代码块。
- 执行次数:对象创建了多少次,则该类中的构造代码块就执行多少次。
- 在构造代码块中,我们不但能直接操作当前类的静态内容,并且还能直接操作当前类的成员内容和this。
- 原因:执行代码块的时候,此时对象都已经创建完毕,因此就能操作当前类的成员内容和this。
- 创建对象的时候,成员变量和构造代码块属于“从上往下,顺序执行”,建议把成员变量定义在构造代码块之前。
- 注意:在构造代码块中,我们“未必”能直接操作当前类的成员变量。
- 在构造代码块中定义的变量,则该变量就只能在当前作用域中使用,不能在代码块之外使用。
- 使用场合:开发中,我们偶尔会在构造代码块中完成对成员变量的初始化操作。(不常见)
- 可以将各个构造方法中公共的代码提取到构造代码块。
- 匿名内部类不能提供构造方法,此时初始化操作可以放到构造代码块中。
- 创建对象的时候,则就会执行该类中的构造代码块,对象创建了多少次则构造代码块就执行多少次。
问题:静态代码块、构造代码块和构造方法执行顺序?
–> 静态代码块 > 构造代码块 > 构造方法
包(package)
包的作用
- 我们使用包来管理类,也就是类应该放在包中。
- 包的出现,为类提供了多层的命名空间,也即是类的完整名字为”包名.类名”。
- 注意:不同的包中,我们可以定义同名的类;同一个包中,我们不允许定义同名的类。
如何定义包
包名必须满足“标识符”的命名规则,必须满足“单词全部小写,多个单词之间以’.’链接,并且做到顶级域名倒着写”的命名规范。
问题:以下两个包是否存在父子关系?【没有】
–> com.bjpowernode.demo com.bjpowernode.demo.test
如何使用包
–> 在源文件有效代码第一行,使用package关键字来声明当前源文件中的类在那个包中。
注意:通过IDEA新建的源文件,则源文件有效代码的第一行默认就有包声明;如果通过DOS命令来运行IDEA创建的源文件,则必须删除源文件中的包声明。
java语言提供的包
- java.lang 包含一些java语言的核心类,如String、Math、System等;
- java.awt 包含了构成抽象窗口工具集(abstract window toolkits)的多个类,这些类被用来构建和管理应用程序的图形用户界面(GUI);
- java.net 包含执行与网络相关的操作的类;
- java.io 包含能提供多种输入、输出功能的类;
- java.util 包含一些实用工具类,如定义系统特性、使用与日期日历相关的函数。
类的访问方式
简化访问
解释:当我们需要访问“java.lang”或“当前包”中的类时,则就可以直接使用“类名”来实现简化访问。
例如:访问“当前包”中的类
–> Tiger tiger = new Tiger(“老虎”, 18);
例如:访问“java.lang”中的类
–> String str = “hello world”;
带包名访问
解释:当我们需要访问“当前包”之外的类时(排除java.lang包中的类),则我们就必须通过“包名.类名”的方式来访问。
例如:访问”p1包”中的类
–> com.bjpowernode.p1.staticblock.student stu = new com.bjpowernode.p1.staticblock.student();
例如:访问“java.util”中的类
–> java.util.Scanner input = new java.util.Scanner(System.in);
import关键字的概述
解释:当我们需要访问“当前包”之外的类(排除java.lang包中的类),则必须通过“带包名”的方式来访问,则此访问方式太麻烦,想要实现简化访问,则就可以先通过import关键字导入需要访问的类,然后再通过“类名”来实现简化访问。
例如:访问“p1包”中的类
–> import com.bjpowernode.p1.staticblock.student;
–> Student stu = new Steudent();
例如:访问”java.util”中的类
–> import java.util.Scanner;
–> Scanner input = new Scanner(System.in);
import关键字的注意点
如果需要使用某个包中的多个类时,则我们可以通过”*”通配符来导入这个包中的所有类。
–> 注意:开发中,不建议使用“*”来导入某个包中的所有类,因此此方式效率非常低。
如果需要使用不同包中的同名类时,则其中一个类必须通过“带包名”的方式来访问。
–> 原因:通过import关键字导入多个不同包的同名类,则在源文件中使用导入的类时,无法区分。
在JDK1.5之后,还新增了静态导入,也就是能导入某个类中的静态属性和静态方法。
–> 例如:导入Math类中的静态属性
- 第一步:import static java.lang.Math.PI;
- 第二步:System.out.println(PI);
–> 例如:导入Math类中的静态属性和静态方法
- 第一步:import static java.lang.Math.*;
- 第二部:System.out.println(PI);
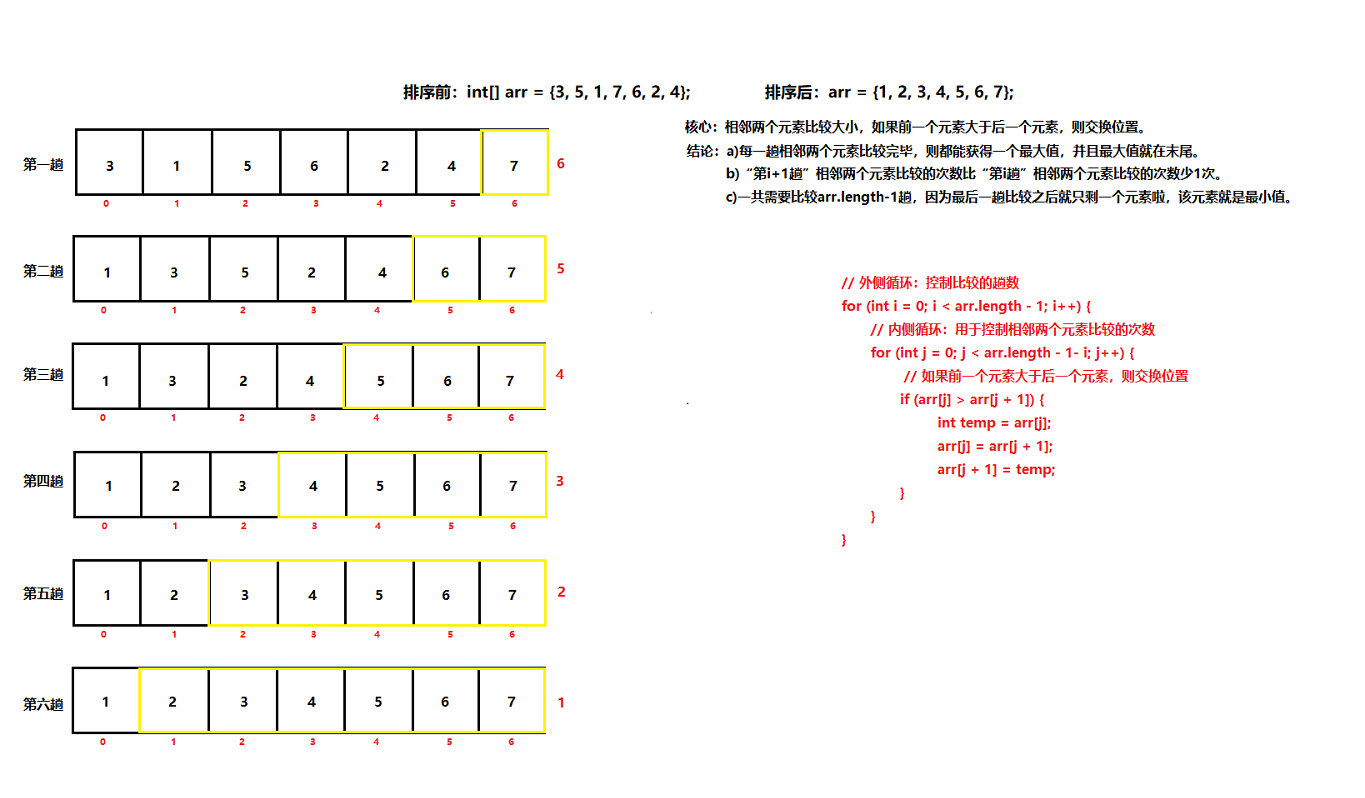
数组算法_冒泡排序
数组算法_选择排序
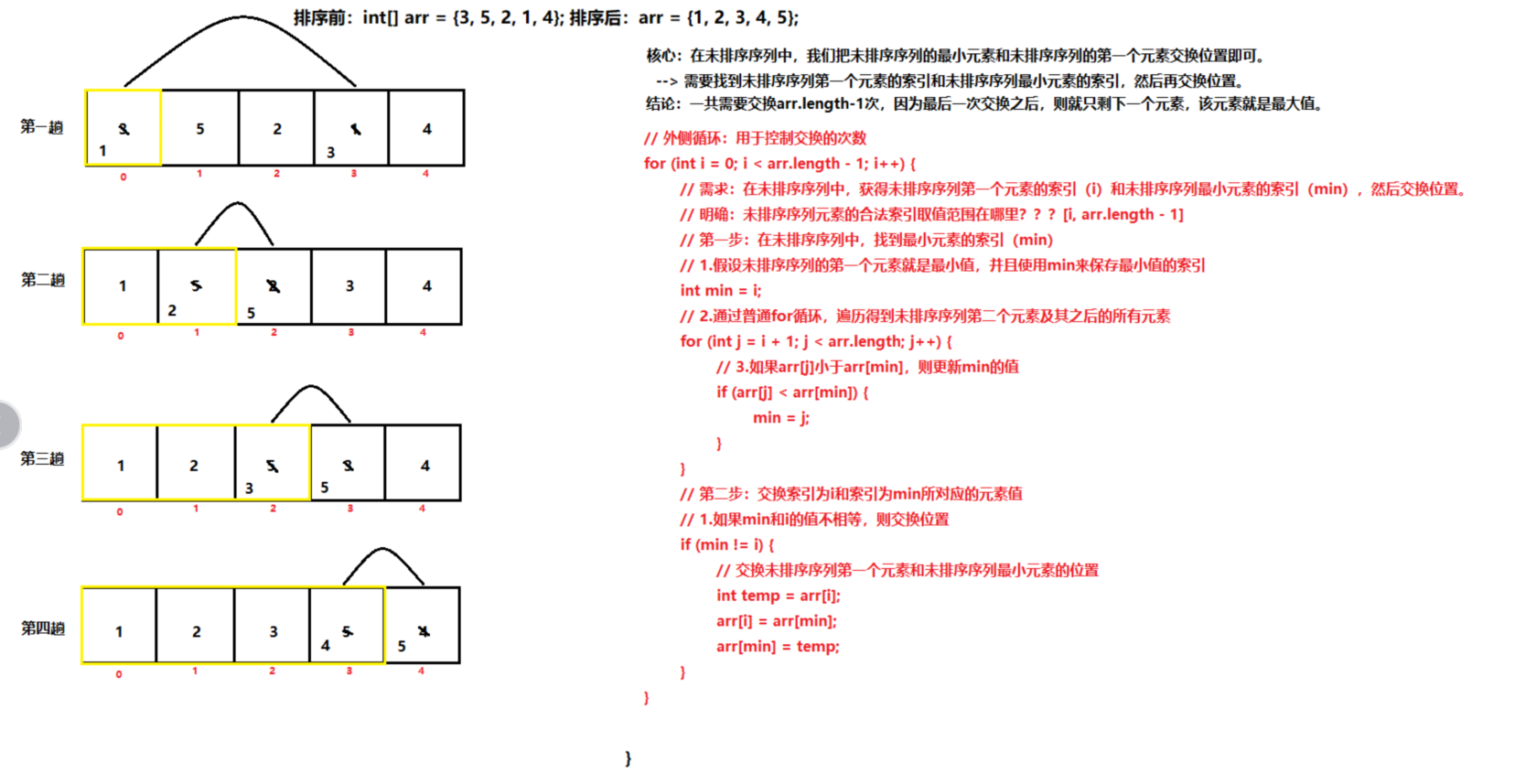
数组算法_查找
需求:查找元素8在数组{0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20}中的索引位置,查找元素在数组中不存在则返回-1。
- 方式一:顺序查找(线性查找)
- 优点:对查找的数组元素是否排序没有要求。
- 缺点:查找效率非常低。
- 方式二:二分查找(折半查找)
- 优点:查询效率非常高。
- 缺点:要求查找的数组元素必须排序(升序 | 降序)。

封装
问题:具备那三大特性的编程语言,我们才称之为面向对象语言?
–> 封装、继承、多态
封装的引入
问题1:给学生年龄赋值的时候,赋值的年龄不能为负数!
–> 使用“setter和getter”方法来解决
问题2:相同的代码在不同的包中,可能会发生编译错误!
–> 使用“权限修饰符”来解决
编程中的封装
- 核心:对于使用者而言,只需掌握其公开的访问方式,无需了解内部的具体实现细节。
封装的层次
- 面向过程:对功能做的封装,也就是使用方法来完成的封装。
- 面向对象:对数据和功能做的封装,也就是使用类来完成的封装。
封装的好处
- 封装的出现,提高了代码的安全性【了解】。
- 封装的出现,提高了代码的复用性【核心】。
权限修饰符
private,私有的,权限:只能在“当前类”中访问,因此我们称之为“类可见性”。
default,默认的,权限:只能在“当前类 + 当前包”中访问,因此我们称之为“包可见性”。
–> 注意:在权限修饰符中,没有default关键字,省略权限修饰符默认就是包可见性。
protected,受保护的,权限:只能在“当前类 + 当前包 + 别的包中的子类包”中访问,因此我们称之为“子类可见性”。
public,公开的,权限:只能在“当前类 + 当前包 + 加别的包”中访问,因此我们称之为“项目可见性”。
- 权限大小【由低到高】:private << default << protected << public
权限修饰符的使用
明确:实际开发中,“默认的”和“受保护的”很少使用,但是“私有的”和“公开的”却很常用。
private:default、protected和public都能修饰”成员变量”和“静态变量”。
–> 成员变量:因为存储都是“特殊数据”,因此使用private修饰。
–> 静态变量:因为存储是“共享数据”,因此使用public来修饰。
private:default、protected和public都能修饰”成员方法”和“静态方法”。
–> 如果该方法需要外界访问,则就把该方法使用public来修饰。
–> 如果该方法无需外界访问,也就是只为当前类服务,那么久把该方法使用private来修饰。
private:default、protected和public都能修饰“构造方法”。
–> 如果该类需要被外界实例化,则该类的构造方法就采用public来修饰;
–> 如果该类无需被外界实例化,则该类的构造方法就采用private来修饰。
注意:工具类中只有静态内容,因此工具类就无需被实例化,那么工具类的构造方法都采用了private修饰,eg:Arrays和Math等等。
定义类的时候,类只允许使用public和default,不允许使用private和protected来修饰。
–>使用public修饰的类(公开权限),则该类就能在整个项目中使用。
–> 使用default修饰的类(默认权限),则该类就只能在当前包中使用。
使用权限修饰符,则不允许修饰局部变量、局部代码块、静态代码块和构造代码块。
setter和getter
setter和getter方法的概述
- 成员变量一律私有化(private),避免外界直接去访问成员变量,然后提供公开的setter和getter方法来操作私有的成员变量。
setter方法的概述
作用:用于给私有的成员变量做赋值操作,并且还能对赋值的数据做检查和处理。
eg:给私有的name成员变量提供setter方法,则实现代码如下:
public void setName(String name){ this.name = name; }问题:给学生年龄赋值的时候,赋值的年龄不能为负数!【假设年龄在0-130之间】
public void setAge(int age){ //处理赋值年龄不合法的情况 if(age < 0 || age > 130){ //System.out.println("输入年龄不合法"); //需求:在此处需要抛出一个参数不合法异常! throw new IllegalArgumentException("赋值年龄参数不合法,age" + age); }else{ //执行到此处,则证明赋值年龄合法,则就执行赋值操作。 this.age = age; } }
getter方法的概述
作用:用于获取私有成员变量的值(取值操作),并且还能对获得的数据做统一的处理。
例如:给私有的name成员变量提供getter方法,则实现代码如下:
public String getName(){ return name; }
setter和getter的注意点
- 通过构造方法给成员变量赋值,如果赋值的数据需要做检查和处理,则在构造方法中就必须调用setter方法来实现赋值操作。
- 给boolean类型成员变量提供getter方法的时候,此时getter方法的名字前缀必须是“is”开头,而不是能以“get”来开头。
- 给类提供“构造方法”和“setter和getter方法”的时候,则建议使用“alt + insert”快捷键来实现,而不建议手动写代码来实现。
DAY13
继承
继承的引入
- 问题:讲师类和学生类中都有相同的name和age两个成员变量,都有相同的eat()和sleep()两个成员方法,因此需要实现代码的复用。
- 解决:使用“继承”来实现。
继承的本质
- 就是提取一系列类中相同的成员变量和成员方法,这样就得到了一个父类,从而形成了继承关系。
- 即:**向上提取。**
继承的语法
[修饰符] class 父类{} [修饰符] class 子类 extends 父类{}- 问题:请问extends表达的含义是什么? –> 扩展的含义
- 注意:父类又称为“超类”或“基类”,子类又称之为“派生类”。
继承的特点
- 子类不但能继承父类的成员变量和成员方法,并且子类还可以有自己特有的成员变量和成员方法。
- 即:**子类对父类做的扩展。**
继承的好处
- 继承的出现,提高了代码的复用性,从而提高了开发的效率。
- 继承的出现,让类与类之间产生了联系,为后面学习“多态”打下了技术铺垫。
- 强调:继承是一把“双刃剑”,父类代码一旦发生了变化,则就会影响所有的子类,使用继承的时候慎重。【高耦合】
哪些内容子类不能继承
- 父类私有的内容,子类不能继承。
- 父类的构造方法,子类不能继承。
- 父类静态的内容,虽然子类能够使用,但父类静态内容“不参与”继承。
- 强调:继承强调的是“对象”之间的关系,因此成员内容能参与继承,但是静态内容不参与继承。
继承的注意点
java语言采用的是“单继承”,C++语言采用的是“多继承”。
- 单继承:一个子类只能有一个直接父类。
- 多继承:一个子类可以有多个直接父类。
AA类继承于BB类,BB类继承于CC类,CC类继承于DD类,。。。,从而就形成了“继承链”。
–> 此处BB类,CC类和DD类都是AA类的“父类”,只有BB类属于AA类的“直接父类”。
java语言中,一个子类只能有一个直接父类,但是一个父类可以有多个直接子类。
如果一个类没有显式地使用extends关键字,则该类就默认继承于”java.lang.Object”类。
–> 所有的java类都可以使用object类提供的方法。【最终继承的都是object类】
方法重写(方法复写,override)
方法重写的引入
- eg:智能机是对功能机做的扩展,也就是应该让“智能机类”继承于“功能机类”,也就意味着“父类”和“子类”中都有show()方法,从而就形成了“方法重写”。
什么是方法重写呢?
- 在子类中,我们定义一个和父类“几乎”一模一样的方法,这就形成了“方法重写”。
什么时候使用方法重写?
- 当父类提供的方法无法满足子类的需求,则在子类中就可以重写父类提供的方法,从而满足开发的需求。
父类的哪些方法子类不能重写?
- 父类的构造方法,子类不能重写。
- 父类的静态方法,子类不能重写。
- 父类私有的成员方法,子类不能重写。
方法重写的注意点
通过子类对象来调用重写方法,则默认调用的是子类重写的方法,而不是调用父类被重写的方法。
保证子类的某个方法肯定是重写方法,则可以在该方法声明之前添加“@Override”注解,从而保证该方法肯定是重写方法。
–> 如果某个方法声明之前添加了“@Override”注解,则该方法就必须是重写方法,否则就会编译错误。
在子类重写方法中,如果想要调用父类被重写的方法,则必须通过super关键字来调用(this和super使用类似)
方法重写的具体要求
==,子类重写方法的“方法名”和“形参列表”必须和父类被重写方法的“方法名”和“形参列表”相同。
–> 此处“形参列表”必须相同,指的是“形参个数”和“形参类型”必须相同,形参名字不同不影响。
“>=”,子类重写方法的修饰符权限必须大于等于父类被重写方法的修饰符权限【权限】。
–> 修饰符权限:public > protected > default > private
–> 注意:子类就不能重写父类采用了static或private来修饰的方法。
“<=”,子类重写方法的“返回值类型”必须小于等于父类被重写方法的“返回值类型”【辈分】。
–> 如果父类被重写方法的返回值类型为void、基本数据类型和String类型,则子类重写方法的返回值类型必须和父类被重写方法的返回值类型保持一致(==)。
–> 如果父类被重写方法的返回值类型为引用数据类型(排除String类型),则子类重写方法的返回值必须小于等于被重写方法的返回值类型。(<=,辈分)。
方法重载和方法重写的区别
整体区别
英文名字区别
方法重载:overload
方法重写:override
使用位置区别
方法重载:同一个类中使用。
方法重写:必须在继承体系中使用。
具体作用区别
方法重载:允许在同一类中定义多个同名的方法,从而避免了方法名被污染。
方法重写:父类提供的方法如果无法满足子类需求,则子类就可以重写父类提供的方法。
具体区别
语法:
[修饰符] 返回值类型 方法名(形参列表){ //方法体 return [返回值]; }修饰符的区别
方法重载:修饰符不同,不构成方法重载。
方法重写:子类重写方法的“修饰符权限”必须大于等于父类被重写方法的“修饰符权限”【权限】。
返回值类型的区别
方法重载:返回值类型不同。不构成方法重载。
方法重写:子类重写方法的“返回值类型”必须小于等于父类被重写方法的“返回值类型”【辈分】。
方法名的区别
方法重载:方法名必须相同。
方法重写:方法名必须相同。
形参列表的区别
方法重载:形参个数不同 或 形参类型不同,形参名字不同不影响。
方法重写:形参个数 和 形参类型必须相同。
重写toString()方法(理解)
请问print()和println()方法的作用
- 通过输出语句,都能把输出的内容转化为字符串类型,然后把转化为字符串类型的结果输出到控制台。
请问基本数据类型和引用数据类型在内存中存储的是什么?
- “基本数据类型”在内存中存储的是“数据值”,“引用数据类型”在内存中存储的是“地址值”。
直接输出一个对象,则输出的内容是什么呢?
输入一个对象的时候,底层做了什么嘛操作?
问题: 引用数据类型在内存中存储的是“地址值”,则我们输出一个对象的时候,为什么输出的是“带包名的类@地址值”呢?
–>原因:输出一个对象的时候,则默认就调用toString()这个方法,此时我们Tiger类中没有定义toString()方法,则默认调用的就是Object类中的toString()方法,在Object类提供的toString()方法中,就返回了“带包名的类@地址值”这个字符串,因此输出一个对象就输出了“带包名的类@地址值”。
源码:分析Object类提供toString()方法的底层源码

重写Object类提供的toString()方法
问题:开发中,输出一个对象的时候,则直接输出“带包名的类@地址值”是没有任何意义的,实际开发中,我们输出一个对象的 时候,更多的是想输出该对象中的所有成员变量值,如何实现?
解决:也就是说Object类提供的toStrig()方法无法满足我们的需求,则我们就可以重写Object类所提供的toString()方法,也就是在 重写toString()方法中返回该对象的所有成员变量值(字符串拼接成员变量后返回即可)。
实现:使用“alt + insert”快捷键来重写toString()方法,不要自己手动去重写toString()方法。

注意:建议每个类都应该重写Object类中的toString()方法,并且建议用“alt + insert”快捷键来重写toString()方法。
super关键字(重点)
super关键字的概述
- 创建一个对象成功之后,则虚拟机就会动态地创建一个引用,该引用指向的就是“新创建出来的对象”,并且该引用的名字就是this。
- 创建一个子类对象成功之后,则虚拟机还会动态创建一个引用,该引用指向的就是“当前对象的直接父类对象”,并且该引用的名字就是super。
- 总结:this指的就是“当前对象”,super指的就是“当前对象的直接父类对象”。并且this可以单独使用,但是super不能单独使用。
super关键字的作用
- 强调:this和super指的都是“对象”,并且this和super使用场合是相同的(构造方法、成员方法和构造代码块)。
- 操作父类的成员变量,语法: super.父类成员变量名
- 调用父类的成员方法,语法:super.父类成员方法(实参列表);
- 调用父类的构造方法,语法:super(实参列表);
this和super的区别
- this的特点:先在当前类找,找不到再去父类找。
- super的特点:直接去父类找,而不会在当前类找。
super关键字的注意点
在子类重写方法中,如果想要调用父类被重写的方法,则必须通过super关键字来实现。
当局部变量,子类的成员变量和父类的成员变量同名的时候,则该如何去区分呢?
局部变量采用“就近原则”,子类成员变量通过“this”来操作,父类成员变量通过“super”来操作。
父类私有的成员变量,在子类中即使使用super关键字也无法操作,只能通过setter和getter方法来操作父类私有成员变量。
super(实参列表)的概述
- 在子类构造方法中,如果想要显式地调用父类的某个构造方法,则必须通过“super(实参列表)”来实现,从而实现了代码的复用。
- 在子类构造方法中,如果没有显式地调用别的构造方法,则默认就会调用父类的无参构造方法,也就是编译时会默认添加“super();”语句。
super(实参列表)的注意点
- “super(实参列表)”只能存在于构造方法中,并且必须在构造方法有效代码的第一行。
- 建议每个类都应该有自己的无参构造方法,避免在继承体系中子类找不到父类的无参构造方法。
this(实参列表)和super(实参列表)的区别
- this(实参列表)的特点:调用“当前类”的别的构造方法,并且必须在构造方法有效代码的第一行。
- super(实参列表)的特点:调用“父类”中的某个构造方法,并且必须在构造方法有效代码的第一行。
- 结论:因为“this(实参列表)”和“super(实参列表)”都必须在构造方法有效代码的第一行,因此构造方法中不允许同时存在“this(实参列表)”和“super(实参列表)”。
继承体系下,创建子类对象的步骤分析
- 第一步:加载类(先加载父类,后加载子类)
- 先执行父类的静态代码块,然后执行子类的静态代码块。
- 第二步:创建对象(先创建父类对象,后创建子类对象)
- 首先,执行父类的构造代码块,接着执行父类的构造方法。
- 然后,执行子类的构造代码块,接着执行子类的构造方法。
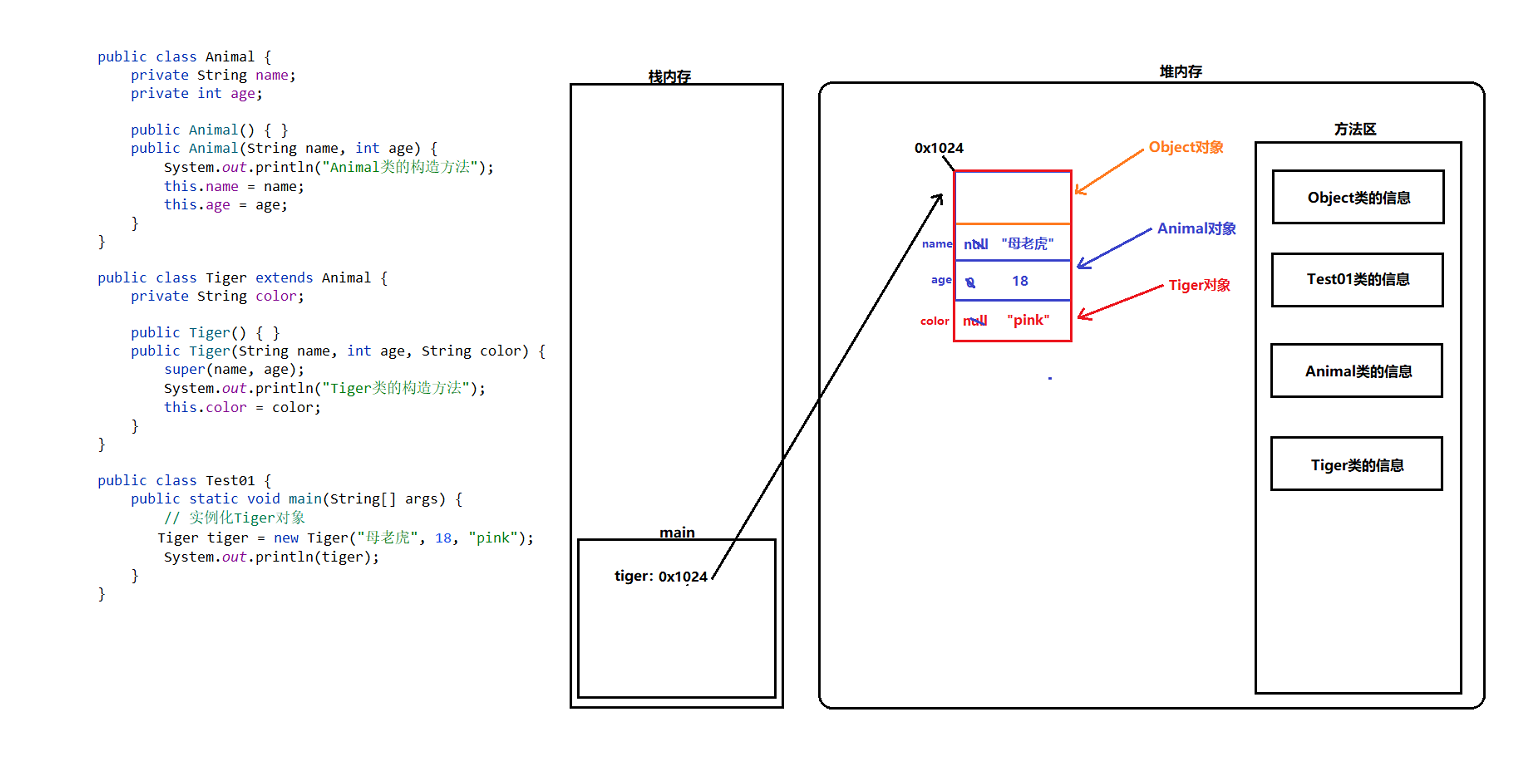
继承体系下,创建子类对象的内存分析
- 创建一个子类对象,则默认还会创建他的父类对象,并且创建的这些对象之间属于“包含”关系。
- 也就是说,子类对象中包含了父类对象,那么子类对象和父类对象的“首地址”肯定是相同的。
继承和组合
- 组合的引入
- 需求:有一台电脑,电脑中包含鼠标、键盘和CPU等。
- 实现:定义电脑类(Computer),然后再定义鼠标类(Mouse)、键盘类(KeyBoard)和CPU类(CPU),然后把鼠标、键盘和CPU作为电脑类的“成员变量”即可,这就形成了“组合”关系。
- 继承和组合
- 相同点
- 都能让类与类之间产生联系,都能实现代码的复用。
- 不同点
- 继承描述的是“is a”的关系,例如:Tiger is Animal, Student is a Person等等。
- 组合描述的是“has a”的关系,例如:Computer has a Mouse,Computer has a keyBoard等等。
- 相同点
final关键字的概述
- final关键字的含义
- 最终的、不可变的
- final关键字能修饰的内容?
- final关键字能修饰类、变量(局部变量、成员变量和静态变量)和方法(成员方法和静态方法),但是不能修饰构造方法和代码块。
final关键字的特点
- 使用final关键字修饰的类,则该类就不能被继承。
- 使用final修饰的类,则改类肯定是一个子类,例如String、Math和System都采用了final修饰。
- 使用final关键字修饰的方法(成员方法和静态方法),则该方法就不能被重写。
- 如果某个成员方法不想被子类重写,则该方法就采用final来修饰即可,例如Object类中的很多方法都采用了final修饰。
- 使用final关键字修饰的变量(局部变量、成员变量和静态变量),则该变量就变为常量了。
- 常量名必须符合“标识符”的命名规则,必须符合“字母全部大写,多个单词之间以下划线连接”的命名规范。
- 使用final修饰的静态变量,要么做显式初始化,要么在静态代码块中初始化,否则就会编译错误。
- 使用final修饰的成员变量,要么做显式初始化,要么在构造代码块中初始化,要么在构造方法中初始化,否则就会编译错误。
- 使用final关键字,我们不能修饰构造方法、局部代码块、构造代码块和静态代码块。
final修饰引用数据类型变量的特点
- 引用数据类型的变量采用final修饰后,则该变量就变为常量了,因此常量保持的地址值不能更改,但是该常量指向堆内存中的成员变量值可以更改。
public class Test01 {
public static void main(String[] args) {
// 实例化Tiger对象
final Tiger TIGER = new Tiger("母老虎", 18);
// 注意:常量只能赋值一次!
// TIGER = null; // 编译错误
// 问题:请问是否能修改TIGER指向堆内存中的成员变量值呢???
TIGER.setName("公老虎");
TIGER.setAge(22);
System.out.println(TIGER);
/*final int MAX_VALUE = 10;
System.out.println(MAX_VALUE); // 输出:10
// 注意:常量只能赋值一次!
MAX_VALUE = 20; // 编译错误*/
}
}通过javadoc.exe来生成API文档(了解)
- 注释的分类
- 单行注释
- 多行注释
- 文档注释
- 注释的使用
- 单行注释用于对代码块或方法体中的某行代码做解释说明,文档注释是用于给类、方法(成员方法、静态方法和构造方法)、成员变量、静态变量、构造代码块和静态代码块做解释说明,而多行注释在实际开发中很少使用。
- 文档注释的概述
- 使用文档注释的时候,我们需要合理的配合“块标记”来使用,常见的块标记如下:
- @version版本号 –> 说明当前类在那个板块中开发或在那个版本中有修改
- @author 作者名 –> 说明当前类是那个程序员开发的
- @param 形参名 –> 对方法的形参做解释说明
- @return –> 对方法的返回值做解释说明
- 使用文档注释的时候,我们需要合理的配合“块标记”来使用,常见的块标记如下:
- 生成项目的API文档
- IDEA默认集成了javadoc.exe这个可执行程序,因此我们通过IDEA就能够直接生成项目的API文档,详情步骤请看预习文档。【第7章】
DAY14
Object类的概述
- 如果一个类没有显式地使用extends关键字,则这个类默认就是继承于java.Object类,也就是说Object类是所有java类的父类。也就意味着所有的java类都能使用Object类提供的方法。
Object类的方法
1.
public String toString(){...}
//作用:把对象转化为字符串并返回。
//注意:每个类都应该重写Object类的toString()方法,在重写的方法中返回该对象的所有成员变量。2.
public boolean equals(Object obj){...}
//作用:判断this和obj这两个对象是否相等。相等则返回true,不相等则返回flse。回顾:关于比较运算符“==”的作用?
- 如果左右两边属于“基本数据类型”,则比较左右两边的“数据值”是否想等。
- 如果左右两边属于“引用数据类型”,则比较左右两边的“地址值”是否相等。
底层:分析Object类提供equals()方法的底层源码
- ```java
public boolean equals(Object obj){
return(this == obj)
}- 强调:Object类提供的equals(Object obj)方法,则默认比较两个对象的“地址值”是否相等。 - **问题:实际开发中,直接比较两个对象的地址值是否相等是没有任何意义的,因为每次创建出来的对象地址值都不一样,开发中我们比较两个对象是否相等,更多的是想比较两个对象的成员变量值是否相等,则该需求如何实现呢?** - 解决:Object类提供的equals(Object obj)方法无法满足我们的需求,则我们就就可以重写Object类所提供给的equals(Object obj)方法,然后在重写的equals(Object obj)方法中根据成员变量值来判断两个对象是否相等。 - 实现:不建议手动去重写equals(Object obj)方法,而是**建议使用“alt + inset”快捷键来重写equals(Object obj)方法。** - **注意:java提供的类,则默认重写了Object类中的equals(Object obj)方法;自定义的类,则需要我们自己去重写Object类中的equals(Object obj)方法。** - **哈希算法(自行了解)** --- #### hashCode() 1. ```java public native int hashCode(); //作用:根据对象来生成一个哈希值,此处的哈希值是一个int类型的整数。 //底层:Objec类提供的hashCode()方法,则默认是根据对象的地址值来生成的哈希值。
- ```java
问题:实际开发中,根据对象的地址值来生成哈希值是没有任何意义的,因为每次创建出来的对象的地址值都不一样。开发中,我们更多的是想根据对象的成员变量来生成哈希值,则该需求如何实现呢?
解决:Object类提供的hashCode()方法无法满足我们的需求,则我们就可以重写Object类提供的hashCode()方法,并且在重写的hashCode()方法中,根据对象的成员变量值来生成哈希值即可。
实现:不建议手动去重写hashCode()方法,而是建议使用“Alt + insert”快捷键来重写hashCode()方法。
结论:
两个对象调用equals()方法的结果是true,则这两个对象调用hashCode()方法返回的结果“肯定”相等。
–> 如果都没有重写equals()方法和hashCode()方法,则以上结论“肯定”满足。
–> 如果重写了equals()方法,则hashCode()方法也必须重写,从而保证以上结论“肯定”相等。
–> 强调:要么都不重写equals()和hashCode()方法,要么都重写equals()和hashCode()方法,从而保证以上结论“肯定”满足。
两个对象调用hashCode()方法返回的结果相同,则这两个对象调用equals()方法的结果“未必”为true。
–> 不同的两个对象(两个对象调用equals()方法的结果为false),则调用hashCode()方法返回的结果可能相同。
public class Test01 { public static void main(String[] args) { // 实例化两个Tiger对象 Tiger tiger1 = new Tiger("母老虎", 18); Tiger tiger2 = new Tiger("母老虎", 18); // 判断两个对象是否相等 System.out.println(tiger1.equals(tiger2)); // 获得两个对象的哈希值 System.out.println(tiger1.hashCode()); // 输出:854700057 System.out.println(tiger2.hashCode()); // 输出:854700057 } }–> 设计哈希算法的时候,则必须遵守的原则为:不同的两个对象,则生成的哈希值要尽可能不相同。

面试题
设计哈希算法的时候,为啥偏偏要使用31来做乘法运算呢?
原因1:因为31是一个质数,而质数做乘法运算得到相同结果的概率非常低。
–> 例如:31 * 5,则结果为:155,那么得到155的乘法组合有:31 * 5、1 * 155
–> 例如:30 * 5,则结果为:150,那么得到150的乘法组合有:30 * 5、1 * 150、25 * 6、50 * 3、15 * 10等等
原因2:因为31是一个质数,而使用质数做乘法运算的效率非常高(位运算)。
–> 使用31来做乘法运算的公式,例如把“31*i”的操作换算为位运算的公式为:(i << 5) - i
–> 例如:31*5的结果为155,则计算公式“(5 << 5) - 5”,那么得到的结果就是155
–> 例如:31*3的结果为93,则计算公式“(3 << 5) - 3”,那么得到的结果就是93
质数千千万,为啥偏偏要使用31来做乘法运算呢?
- 假设:使用7来做乘法运算,因为7是一个质数,因此做乘法运算得到相同结果的概率较低,并且使用7来做乘法运算的效率还非常高。
- 公式:实现“7*i”的操作,则可以通过“(i << 3) - i”来实现。
- 例如:7*5,则套用公式为“(5 << 3) - 5”,则得到的结果为:35
- 答案:为什么要使用31来做乘法运算,因为这是数学家让我们这么做的。
本地方法
- 什么是本地方法?
- 使用native关键字修饰的方法,我们就称之为“本地方法”。
- 本地方法的特点?
- 本地方法只有方法声明,没有方法内部的具体实现,也就是没有方法体。
- 为什么会有本地方法?
- 因为java语言无法直接操作硬件,因此需要调用别的编程语言来操作硬件,而本地方法体就是调用了别的编程语言,考虑到java程序员可能不认识别的编程语言,因此本次发就省略了方法体。
基本数据类型的转换
隐式类型转换(自动)
- ```java
double num = 123;2. 强制类型转换(手动) - ```java int num = (int)3.14
- ```java
引用数据类型的转换
向上转型(自动)
解释:父类引用指向子类对象。
语法:父类类型 对象 = 子类对象;
eg:
Animal animal = new Dog();优势:隐藏了子类特有内容,从而提高了代码的扩展性(多态)。
劣势:只能使用父类共有的内容,不能使用子类特有的内容。
使用场合:使用“多态”的时候,则我们就必须使用“向上转型”,从而提高了代码的扩展性。
向下转型(手动)
解释:子类引用指向父类对象。
语法:子类类型 对象 = (子类类型) 父类对象;
eg:
Dog dog = (Dog)animal;优势:不但能使用父类共有的内容,并且还能使用子类特有的内容。
劣势:使用向下转型的时候,可能会抛出“类型转换异常(ClassCastException)”。
使用场合:使用多态提高代码的扩展性后,如果需要使用对象实际类型中的内容,则那么就必须做向下转型的操作。
eg1:
public class Test01 { public static void main(String[] args) { // 向上转型(自动) Animal animal = new Dog(); // 向下转型(手动) // 原因:因为animal对象本质上属于Dog类型,因此就无法将animal对象强转为Tiger类型 Tiger tiger = (Tiger) animal; // 类型转换异常 } private static void method02() { // 向上转型(自动) Animal animal = new Dog(); // 向下转型(手动) Dog dog = (Dog) animal; // 优势:不但能使用父类共有的内容,并且还能使用子类特有的内容。 System.out.println(dog.name); dog.eat(); System.out.println(dog.color); dog.show(); } private static void method01() { // 向上转型(自动) Animal animal = new Dog(); // 劣势:只能使用父类共有的内容,不能使用子类特有的内容。 System.out.println(animal.name); animal.eat(); // System.out.println(animal.color); // 编译错误 // animal.show(); // 编译错误 } }eg2:
/** * 需求:调用一个方法,传入一个字符串类型的类名,则就返回该类名所对应的对象。 */ public class Test02 { public static void main(String[] args) { // 父类引用指向子类对象(多态) Animal dog = getAnimalInstance("Dog"); // 父类引用指向子类对象(多态) Animal tiger = getAnimalInstance("Tiger"); } /** * 场合二:返回值类型为父类类型,则返回值就可以是该父类的任意子类对象。 */ public static Animal getAnimalInstance(String name) { switch (name) { case "Dog": return new Dog(); case "Cat": return new Cat(); case "Pig": return new Pig(); case "Bird": return new Bird(); case "Tiger": return new Tiger(); default: throw new IllegalArgumentException("参数不合法异常,name:" + name); } } }
多态的引入
需求:在动物园中,管理员专门给动物们喂食。
实现:定义管理员类(Admin),然后再定义动物类(Dog、Cat、Pig、Bird和Tiger),接着给每个动物提供eat()方法,最后再管理员类中给每个动物提供喂食的方法,例如给Dog提供的喂食方法为:
void feedDog(Dog dog){ dog.eat(); }问题:
- a)动物园中有无穷无尽的动物,则在管理员类中就需要提供无穷无尽的喂食方法。
- b)当动物园引进一只新的动物,则在管理员类中就需要为它提供喂食的方法,这样不利于程序的维护性。
解决:使用“多态”来解决。
修改代码的步骤?
- 第一步:定义一个Animal类,然后再Animal类中提供eat()方法。
- 第二步:让所有的动物类都继承于Animal类,并重写Animal类的eat()方法。
- 第三步:在Admin类中,我们只提供一个喂食的方法,也就是专门给所有的动物们喂食。
- 第四步:在测试类中,我们调用Admin类的feedAnimal()方法,用于给所有动物们喂食。
使用多态的前提?
前提1:继承是实现多态的前提。
–> 让所有的动物类都继承于Animal类,也就是Animal类是所有动物类的父类!
前提2:子类必须重写父类方法。
–> 所有的动物类都重写了Animal类的eat()方法,毕竟每个动物吃的东西都不同。
前提3:父类引用指向子类对象。
–> Admin类中的feedAnimal()方法的形参为“Animal”类型,调用该方法时的实参为“Animal类的子类对象”,此处就用到了“父类引用指向子类对象”。
–> 调用feedAnimal()方法的代码为“admin.feedAnimal(new Dog());”,则实现赋值给形参的操作就等效于:Animal animal = new Dog();
使用多态的场合
场合一:方法的形参为父类类型,则实参就可以是该父类的任意子类对象。
–> 例如:管理员给动物们喂食的案例
场合二:返回值类型为父类类型,则返回值就可以是该父类的任意子类对象。
–> 例如:简单工厂模式的案例
目前的学习中,我们在哪些地方遇到多态呢?
- 在Object类中,提供的equals(Object obj)方法就使用了多态。
eg:
public class Test01 { public static void main(String[] args) { // 实例化管理员对象 Admin admin = new Admin(); // 实例化动物对象 Dog dog = new Dog(); Pig pig = new Pig(); Cat cat = new Cat(); Bird bird = new Bird(); Tiger tiger = new Tiger(); Panda panda = new Panda(); // 管理员给动物们喂食 admin.feedAnimal(dog); admin.feedAnimal(cat); admin.feedAnimal(pig); admin.feedAnimal(bird); admin.feedAnimal(tiger); admin.feedAnimal(panda); } }
多态情况下,操作成员变量的特点
- 编译时:检查“编译时类型”,也就是检查编译时类型中是否有该成员变量。
- 运行时:检查“编译时类型”,也就是操作了编译时类型中的成员变量。
- 总结:多态情况下操作成员变量,则编译和运行都检查“编译时类型”。
多态情况下,调用成员方法的特点?
编译时:检查“编译时类型”,也就是检查编译时类型中是否有该成员方法。
运行时:检查“运行时类型”,也就是调用了运行时类型中的成员方法。
总结:编译时检查“编译时类型”,运行时检查“运行时类型”。
eg:
public class Test01 { public static void main(String[] args) { Animal animal = new Tiger(); animal.show(); } private static void method02() { // 父类引用指向子类对象(多态) // animal对象的编译时类型为“Animal”类,animal对象的运行时类型为“Tiger”类。 Animal animal = new Tiger(); // 运行时:检查“运行时类型”,也就是调用了运行时类型中的成员方法。 animal.eat(); // 编译时:检查“编译时类型”,也就是检查编译时类型中是否有该成员方法。 /*animal.eat(); animal.sleep(); // 编译错误*/ } private static void method01() { // 父类引用指向子类对象(多态) // animal对象的编译时类型为“Animal”类,animal对象的运行时类型为“Tiger”类。 Animal animal = new Tiger(); // 运行时:检查“编译时类型”,也就是操作了编译时类型中的成员变量。 System.out.println(animal.name); // 编译时:检查“编译时类型”,也就是检查编译时类型中是否有该成员变量。 /*System.out.println(animal.name); System.out.println(animal.color); // 编译错误*/ } }
instanceof二元运算符的概述
语法:
boolean result = obj instanceof class;注意:
- 此处obj可以是一个对象,也可以为null。
- 此处class可以是一个类,也可以是一个接口。
- 此处instanceof二元运算符返回的结果肯定是boolean类型。
instanceof二元运算符的作用
- 官方:判断左边的“对象”是否为右边“类或接口”的实例,如果“对象”属于“类或接口”的实例,则返回true,否则一律返回false。
- 通俗:如果强转的“对象”属于强转“类或接口”的实例,则就可以把该“对象”强转为该“类或接口”的类型,否则就会出现类型转换异常。
编译时类型和运行时类型的概述
编译时类型:指的就是声明对象的类型,也就是等号左边的类型。
运行时类型:指的就是对象的实际类型,也就是等号右边的类型。
eg:没有使用多态之前,则编译时类型和运行时类型如下:
Dog dog = new Dog();- 此处dog对象的编译时类型为”Dog“类,dog对象的运行时类型为”Dog“类。 4. eg:学习使用多态之后,则编译时类型和运行时类型如下: - ```java Animal animal = new Dog();此处animal对象的编译时类型为“Animal”类,animal对象的运行时类型为“Dog”类。
instanceof二元运算符编译的特点
- 情况一:当obj存储的内容就是null的情况
- 当obj的存储的内容为null,则无论右侧的类或接口属于哪种类型,那么都编译都通过。
- 情况二:当obj存储的内容不是null的情况
- 当右边的“类或接口”属于左边“对象”编译时类型的父类、本身类和子类时,则编译通过,否则一律编译错误。
- 注意:此处参照左边“对象”的“编译时类型”,并且此处的“本身类”指的也就是对象的“编译时类型”。
instanceof二元运算符运行的特点
情况一:当obj存储的内容就是null的情况
- 当obj存储的内容为null,则无论右侧的类或接口属于哪种类型,那么返回的结果都是false。
- 结论:null不是任何类或接口的实例。
情况二:当obj存储的内容不是null的情况
- 当右侧的“类或接口”属于左边“对象”运行时类型的父类和本身类时,则一律返回true;
- 当右侧的“类或接口”属于左边“对象”运行时类型的子类和兄弟类时,则一律返回false。
- 注意:此处参照左边“对象”的“运行时类型”,并且此处的“本身类”指的也就是对象的“运行时类型”。
eg:
public class Test01 { public static void main(String[] args) { // 父类引用指向子类对象(多态) // animal对象的编译时类型为“Animal”类,animal对象的运行时类型为“Dog”类 Animal animal = new Dog(); // 编译时:父类 运行时:父类 System.out.println(animal instanceof Object); // 输出:true // 编译时:本身类 运行时:父类 System.out.println(animal instanceof Animal); // 输出:true // 编译时:子类 运行时:本身类 System.out.println(animal instanceof Dog); // 输出:true // 编译时:子类 运行时:兄弟类 System.out.println(animal instanceof Tiger); // 输出:false // 编译时:子类 运行时:子类 System.out.println(animal instanceof SmallDog); // 输出:false // 编译时:没有关系 // System.out.println(animal instanceof String); // 编译时:没有关系 // System.out.println(animal instanceof Test01); /*System.out.println(null instanceof Object); // 输出:false System.out.println(null instanceof Animal); // 输出:false System.out.println(null instanceof Dog); // 输出:false System.out.println(null instanceof Tiger); // 输出:false System.out.println(null instanceof SmallDog); // 输出:false System.out.println(null instanceof String); // 输出:false System.out.println(null instanceof Test01); // 输出:false*/ } private static void method01() { // 父类引用指向子类对象(多态) Animal animal = new Dog(); // 需求:把animal对象强转为Dog类型 // 1.判断animal对象是否为Dog类的实例 if (animal instanceof Dog) { // 2.把animal对象强转为Dog类型 Dog dog = (Dog) animal; System.out.println("把animal对象强转为Dog类型"); } // 需求:把animal对象强转为Tiger类型 // 1.判断animal对象是否为Tiger类的实例 if (animal instanceof Tiger) { // 2.把animal对象强转为Tiger类型 Tiger tiger = (Tiger) animal; System.out.println("把animal对象强转为Tiger类型"); } // 需求:把animal对象强转为SmallDog类型 // 1.判断animal对象是否为SmallDog类的实例 if (animal instanceof SmallDog) { // 2.把animal对象强转为SmallDog类型 SmallDog smallDog = (SmallDog) animal; System.out.println("把animal对象强转为SmallDog类型"); } } }
abstract的引入
- 需求:在动力节点中,有讲师和助教两个工种,他们都具备工作的能力。
- 实现:定义讲师类(Teacher)和助教类(Assistant),然后分别提供work()的方法。
- 问题:讲师类和助教类都有work()方法,也就是讲师类和助教类都有相同的代码,因此我们需要实现代码的复用。
- 解决:使用“继承”来实现。定义一个员工类(Employee),并且给员工类提供work()方法,然后让讲师类和助教类继承于员工类,并重写员工类中的work()方法。
- 问题1:世界上没有任何一个工种就叫做员工,因此员工类不应该被实例化!
- –> 使用“抽象类”来解决,也就是把员工类设置为抽象类即可。
- 问题2:为了避免讲师和助教偷懒,因为要求讲师类和助教类必须重写员工类的work()方法!
- –> 使用“抽象方法”来解决,也就是把员工类的work()方法设置为抽象方法。
抽象类
什么是抽象类
- 使用abstract关键字修饰的类,则我们就称之为“抽象类”。
抽象类的组成
- a)在抽象类中,依旧可以拥有成员变量和静态变量。
- b)在抽象类中,依旧可以拥有成员方法和静态方法,并且还可以有任意多个抽象方法。
- c)在抽象类中,依旧可以拥有构造方法,该构造方法用于给抽象类中的成员变量做指定初始化操作。
- d)在抽象类中,依旧可以拥有构造代码块和静态代码块。
- 总结:抽象类就是一个特殊的类,抽象类对比普通类新增了任意多个抽象方法。
抽象类的特点
a)抽象类不能被实例化,因为抽象类中包含了抽象方法。
b)抽象类肯定是一个父类,只有实现类“实现”了抽象类中的所有抽象方法,则该实现类才能被实例化,否则该实现类就是一个抽象类。
实现:子类重写父类的抽象方法,我们就称之为“实现”。
重写:子类重写父类的普通方法,我们就称之为“重写”。
c)抽象类可以作为方法的“形参类别”和“返回值类型”,也就是抽象类也可以实现多态。
d)实现类与抽象类之间属于“extends”的关系,并且属于“单继承”。
抽象方法
什么是抽象方法?
- 使用abstract关键字修饰的方法,我们就称之为“抽象方法”。
抽象方法的特点
- a)抽象方法只有方法声明,没有方法内部的具体实现,也就是没有方法体。
- b)抽象方法只能存在于“抽象类”和“接口”中,不能存在于“普通类”中。
关于abstract关键字的补充?
- a)请问abstract关键字和哪一个关键字是反义词???final
- b)请问abstract关键字不能和哪些关键字共存呢???final、private、static
eg:
public class Test01 { public static void main(String[] args) { // Employee employee = new Employee(); // 父类引用指向子类对象(多态) Employee employee = new Teacher(); // 实例化Teacher对象 Teacher teacher = new Teacher(); teacher.work(); // 实例化Assistant对象 Assistant assistant = new Assistant(); assistant.work(); } }
DAY15
接口(interface)
- 接口的引入
- 需求:让飞机、炮弹、小鸟和超人进行飞行表演!
- 实现:定义飞机类(Plane)、炮弹类(Peng)、小鸟类(Bird)和超人类(SuperMan),然后为每个类提供showFly()的方法。
- 问题:飞机类、炮弹类、小鸟类和超人类都有showFly()方法,也就是这些类中有相同的代码,那么我们就需要实现代码的复用,如何实现?
- 解决:使用“继承”来解决。定义一个Flyable类,然后给Flyable类提供showFly()的方法,接着让飞机类、炮弹类、小鸟类和超人类“继承”于Flyable类,并重写Flyable类中的showFly()方法。
- 问题:继承描述的是“is a”的关系,也就是描述“相同体系”的基本行为,此处飞机、炮弹、小鸟和超人属于不同体系,因此使用继承不合适
- 解决:使用“接口”来解决。定义一个Flyable接口,然后给Flyable接口提供showFly()方法,接着让飞机类、炮弹类、小鸟类和超人类“实现”于Flyable接口,并实现Flyable接口中的showFly()方法。
- 总结:接口描述的是“is like a”的关系,也就是描述“不同体系”的相同行为,此处飞机、炮弹、小鸟和超人属于不同体系,因此使用接口很合适。
接口的概述
接口的定义
明确:接口使用interface关键字来修饰,并且interface和class属于平级的,因此interface和class不能共存!
语法:
[修饰符] interface 接口 extends 父接口1, 父接口2, 父接口3, ... { // 全局静态常量和全局抽象方法 }
接口的组成
a)接口中的属性,默认全部是“全局静态常量”,也就是默认使用了“public static final”来修饰。
b)接口中的方法,默认全部是“全局抽象方法”,也就是默认使用了“public abstract”来修饰。
在JDK1.8之后,接口中还新增了“全局静态方法”和“default修饰的全局默认方法”。
c)在接口中,不允许存在构造方法,因为接口中都没有成员变量,因此就无需存在构造方法。
d)在接口中,不允许存在静态代码块和构造代码块。
接口的特点
- a)接口不能被实例化,因为接口中存在抽象方法,并且接口中没有构造方法。
- b)接口可以作为方法的“形参类型”和“返回值类型”,也就是接口能够实现多态。
- c)接口与接口之间属于“extends”的关系,并且接口还属于“多继承”。
- d)抽象方法只能存在于“抽象类”和“接口”中,不能存在于“普通类”中。
实现类的概述
实现类的定义
明确:实现类和接口之间属于“implements”的关系,而不是属于“extends”的关系。
语法:
[修饰符] class 实现类 extends 父类 implements 接口1, 接口2, 接口3, ... { // 实现类中书写的代码 }
实现类的特点
- a)实现类只有“实现”了接口中的所有抽象方法,则该实现类才能被实例化,否则该实现类就是一个抽象类。
- b)实现类可以先继承一个父类,然后再去实现多个接口,实现多个接口的操作我们就称之为“接口的多实现”。
eg:
/** * 接口 */ public interface Flyable extends Runable, Sleepable, Eatable { // a)接口中的属性,默认全部是“全局静态常量”,也就是默认使用了“public static final”来修饰。 /*public static final*/ String CLASS_ROOM = "教室四"; // d)在接口中,不允许存在静态代码块和构造代码块。 // {} // static {} // c)在接口中,不允许存在构造方法,因为接口中都没有成员变量,因此就无需存在构造方法。 // public Flyable() {} // b)接口中的方法,默认全部是“全局抽象方法”,也就是默认使用了“public abstract”来修饰。 /*public abstract*/ void showFly(); // 在JDK1.8之后,接口中还新增了“全局静态方法”。 /*public*/ static void staticMethod() { System.out.println("static method ..."); } // 在JDK1.8之后,接口中还新增了“default修饰的全局默认方法”。 /*public*/ default void show() { System.out.println("default method ..."); } }public class Test01 { public static void main(String[] args) { System.out.println(Flyable.CLASS_ROOM); Flyable.staticMethod(); // 父类引用指向子类对象(多态) // bird对象的编译时类型为“Flyable”接口,bird对象的运行时类型为“Bird”类。 Flyable bird = new Bird(); // 编译时:检查“编译时类型”,也就是检查Flyable接口中是否有showFly()方法。 // 运行时:检查“运行时类型”,也就是调用了Bird类中的showFly()方法 bird.showFly(); bird.show(); } }
抽象类和接口的总结
普通类、抽象类和接口的特点
- 接口的抽象程度最高,抽象类的抽象程度次之,普通类的抽象程度最低。
抽象类和接口的对比
相同点
- 都是向上提取的结果,因此都不能被实例化。
- 都是向上提取的结果,因此都包含了抽象方法。
不同点
接口与接口之间属于“extends”的关系,并且属于“多继承”。
抽象类与抽象类之间属于“extends”的关系,并且属于“单继承”。
实现类与接口之间属于“implements”的关系,并且属于“多实现”。
实现类与抽象类之间属于“extends”的关系,并且属于“单继承”。
接口描述的是“is like a”的关系,也就是描述“不同体系”的相同行为。
抽象类描述的是“is a”的关系,也就是描述“相同体系”的基本行为。
接口中只有“全局静态常量”和“全局抽象方法”,JDK1.8之后新增了“全局静态方法”和“default修饰的全局默认方法”。
抽象类就是一个特殊类,抽象类对比普通类新增了任意多个抽象方法。
单继承和多继承的概述?
- 单继承:java、C#等等
- 解释:一个子类只能有一个直接父类,类似于一个儿子只有一个亲爹。
- 优势:简单、安全。
- 劣势:只能继承一个父类的内容,则子类功能不够强大。
- 多继承:C++
- 解释:一个子类可以有多个直接父类,类似于一个儿子可以有多个亲爹。
- 优势:可以继承多个父类的内容,则子类功能非常强大。
- 劣势:复杂、不安全。
接口的多实现的概述
- 需求:要求子类不但简单又安全,同时还要求子类功能非常强大,如何实现?
- 不但要集合单继承和多继承的优势,并且还要摒弃单继承和多继承的劣势。
- 实现:先让子类继承于某个父类,然后再让该子类实现多个接口,实现多个接口的操作就称之为“接口的多实现”。
- 通过以上的实现方式,我们就模拟了C++的多继承操作,并且还摒弃了C++多继承的劣势。
内部类的概述
什么是内部类
- 在OutClass类的内部,我们再定义InnerClass类就是内部类。
内部类的定义位置?
- 位置一:在类中,代码块或方法体的内部。
- 位置二:在类中,代码块和方法体的外部。
什么时候使用内部类?
- 描述一个事物的时候,我们发现该事物内部还有别的事物,此时就可以使用内部类来实现。
- 例如:描述小汽车的时候,我们发现小汽车内部还有发动机,此时的发动机就是一个内部类。
内部类的分类?
- 成员内部类(掌握)、静态内部类(掌握)、局部内部类(了解)和匿名内部类(重点)。
内部类编译的特点?
在OuterClass类的内部,我们再定义InnerClass类,此时我们对程序进行编译,则就会获得两个字节码文件
–> OuterClass.class 外部类的字节码文件,也就是OuterClass类的字节码文件
–> OuterClass$InnerClass.class 内部类的字节码文件,也就是InnerClass类的字节码文件
操作内部类的特点?
- 想要操作内部类,则必须通过外部类来实现,也就是内部类是依附于外部类的。
成员内部类(掌握)
明确:学习成员内部类的时候,我们建议把“成员内部类”当成“成员变量”来理解。
定义位置
- 在类中,代码块和方法体之外。
定义语法
- ```java
[修饰符] class 外部类{
//成员内部类
[修饰符] class 内部类{
//内部类中的代码
}
}3. 注意事项 - a)**定义成员内部类的时候**,我们可以使用private、protected、public、final和abstract来修饰,但是**不能使用static来修饰。** - b)**在成员内部类中**,我们只能定义成员变量、成员方法、构造方法和构造代码块,但是**不能定义静态变量、静态方法和静态代码块。** - c)想要操作成员内部类,则我们必须通过外部类对象来操作,也就是**成员内部类是依附于外部类对象的**,此处联想“成员变量”来理解。 **在外部类的成员位置,我们可以直接操作当前类的成员内部类;但是在外部类的静态位置,我们不能直接操作当前类的成员内部类。** - d)在成员内部类中,我们不但能直接操作外部类的成员变量和成员方法,并且还能直接操作外部类的静态变量和静态方法。 代码执行到成员内部类中,则意味着外部类对象肯定已经创建完毕,因此就能操作外部类的成员内容和静态内容。 - e)在成员内部类中,当局部变量、成员内部类的成员变量和外部类的成员变量同名的时候,则如何区分呢? - ```java System.out.println{"局部变量:" + name} System.out.println("内部类的成员变量:" + this.name); System.out.println("外部类的成员变量:" + OuterClass.this.name);
- ```java
成员内部类的实例化方式?
情况一:在外部类的内部,我们实例化成员内部类对象(掌握)
–> 语法:
内部类 对象 = new 内部类(实参列表);情况二:在外部类的外部,我们实例化成员内部类对象。(了解)
–> 语法:
外部类.内部类 对象 = new 外部类(实参列表).new 内部类(实参列表);eg:
// 外部类 class OuterClass { String name = "OuterClass"; int age; static String classRoom; // 成员内部类 public final class InnerClass { String name = "InnerClass"; {} public InnerClass(String name) { this.name = name; } public void show(String name) { // 在成员内部类中,当局部变量、成员内部类的成员变量和外部类的成员变量同名的时候,则如何区分呢??? System.out.println("局部变量:" + name); System.out.println("内部类的成员变量:" + this.name); System.out.println("外部类的成员变量:" + OuterClass.this.name); /*System.out.println(age); // 没问题 System.out.println(classRoom); // 没问题 System.out.println("show ...");*/ } } /** * 情况一:在外部类的内部,我们实例化成员内部类。 */ public void method() { InnerClass innerClass = new InnerClass("小花"); innerClass.show("局部变量"); } } public class Test02 { public static void main(String[] args) { // new OuterClass().method(); // 情况二:在外部类的外部,我们实例化成员内部类对象 OuterClass.InnerClass innerClass = new OuterClass().new InnerClass("小花"); innerClass.show("局部变量"); } }
静态内部类(掌握)
明确:学习静态内部类的时候,我们把“静态内部类”当成“静态变量”来理解。
定义位置
- 在类中,代码块和方法之外。
定义语法
-
[修饰符] class 外部类{ //静态内部类 [修饰符] static class 内部类{ //书写静态内部类的代码 } }注意事项
a)定义静态内部类的时候,我们可以使用private、protected、public、final和abstract来修饰,并且还必须使用static来修饰
b)在静态内部类中,我们不但能定义成员变量、成员方法、构造方法和构造代码块,并且还能定义静态变量、静态方法和静态代码块。
c)想要操作静态内部类,则直接通过外部类名来操作即可,因为静态内部类是依附于外部类的,此处联想“静态变量”来理解即可。
在外部类的成员位置,我们可以直接操作当前类中的静态内部类;在外部类的静态位置,我们可以直接操作当前类中的静态内部类。
d)在静态内部类中,我们可以直接操作外部类的静态变量和静态方法,但是不能直接操作外部类的成员变量和成员方法。
静态内部类是依附于外部类的,也就是只要外部类加载完毕,则就能操作当前类中静态内部类。
e)想要操作静态内部类中的静态变量和静态方法,则我们还可以通过以下方式来直接操作:
- 操作静态变量:外部类.静态内部类.静态变量名;
- 操作静态方法:外部类.静态内部类.静态方法名(实参列表);
静态内部类的实例化方式?
情况一:在外部类的内部,我们实例化静态内部类对象(掌握)
–> 语法:
内部类 对象 = new 内部类(实现列表);情况二:在外部类的外部,我们实例化静态内部类对象(了解)
–> 语法:
外部类.内部类 对象 = new 外部类.内部类(实参列表);
成员内部类和静态内部类的总结
- 成员内部类:如果内部类需要依附于外部类对象,则该内部类就必须为成员内部类。
- 静态内部类:如果内部类只需依附于外部类即可,并且需要在该内部类中定义静态内容,则该内部类就必须定义为静态内部类。
eg:
// 外部类 class OuterClass { int age; static String userName; // 静态内部类 public final static class InnerClass { String name; static String classRoom; {} static {} public InnerClass(String name) { this.name = name; } public void show() { /*System.out.println(age); // 编译错误 System.out.println(userName); // 没问题*/ System.out.println("show ..."); } public static void method() { System.out.println("method ..."); } } /** * 情况一:在外部类的内部,我们实例化静态内部类对象 */ public static void method() { InnerClass innerClass = new InnerClass("小花"); innerClass.show(); } } public class Test01 { public static void main(String[] args) { // 操作静态方法:外部类.静态内部类.静态方法名(实参列表); OuterClass.InnerClass.method(); // 操作静态变量:外部类.静态内部类.静态变量名 System.out.println(OuterClass.InnerClass.classRoom); // OuterClass.method(); // 情况二:在外部类的外部,我们实例化静态内部类对象 OuterClass.InnerClass innerClass = new OuterClass.InnerClass("小花"); innerClass.show(); } }
局部内部类(了解)
明确:学习局部内部类,则我们把“局部内部类”当成“局部变量”来理解。
定义位置
- 在类中,代码块或方法体的内部。
定义语法
-
[修饰符] class 外部类{ { //位置一:定义在代码块中 class内部类{ //书写局部内部类中的代码 } } [修饰符] 返回值类型 方法名(形参列表){ //位置二:定义在方法体中 class 内部类{ //书写局部内部类中的代码 } } }注意事项
a)定义局部内部类的时候,我们不能使用private、protected、public和static修饰,但是可以使用final和abstract来修饰。
b)在局部内部类中,我们只能定义成员变量、成员方法、构造方法和构造代码块,但是不能定义静态变量、静态方法和静态代码块。
c)局部内部类只能在“当前作用域”中使用,不能在代码块或方法体之外使用,此处我们可以联想局部变量的“生命周期”来理解。
d)在局部内部类中,我们“肯定”能操作外部类的静态变量和静态方法,但是“未必”能操作外部类的成员变量和成员方法。
在局部内部类中,是否能操作外部类的成员变量和成员方法,关键是看该局部内部类在哪个位置中定义的。
e)在局部内部类中,想要操作外部的局部变量,则该局部变量必须采用final来修饰,从而保证数据的安全性。
在局部内部类中,如果操作了外部的局部变量,则该局部变量的生命周期就延长了,也就是该局部变量的生命周期和局部内部类对象的生命周期保持一致了。
补充:在JDK1.8之后,如果在局部内部类中使用了外部的局部变量,则该局部变量默认就会采用final来修饰,从而保证数据的安全性。
eg1:
// 外部类 class OuterClass { int age; static String classRoom; public static void method() { // 外部的局部变量 /*final*/ int num = 10; // num出生 // 局部内部类 final class InnerClass { String name; {} public InnerClass(String name) { this.name = name; } public void show() { System.out.println(num); // num = 20; --> 编译错误 /*System.out.println(age); // 未必 System.out.println(classRoom); // 没问题*/ System.out.println("show ..."); } } // 实例化InnerClass对象 InnerClass innerClass = new InnerClass("小花"); // 调用show()方法 innerClass.show(); } // 如果在局部内部类中,我们没有使用外部的局部变量num,则该变量num就在此处死亡 // 如果在局部内部类中,我们使用了外部的局部变量num,则该num就和局部内部类对象的生命周期保持一致啦。 } public class Test01 { public static void main(String[] args) { OuterClass.method(); } }eg2:
package com.bjpowernode.p5.innerclass; /** * 需求:调用一个方法,则就返回某个抽象类的实现类对象,并且该实现类必须是一个局部内部类。 */ // 抽象类 abstract class Animal { public abstract void eat(); } // 外部类 class Outer { // 返回Animal的实现类对象 public static Animal getAnimalInstance() { // 外部的局部变量 /*final*/ int num = 10; // num出生 // 定义一个继承于Animal类的局部内部类 class Bird extends Animal { /** * 此处就是我写的方法,在该eat()方法中我们需要使用num的值,也就是需要使用num的初始值10即可 */ @Override public void eat() { System.out.println(num); System.out.println("小鸟在吃虫子..."); } /** * 这个是同事写的方法,在该方法中需要定义一个变量来保存数据20,如果使用num来保存20,则数据就不安全啦 */ public void sleep() { // num = 20; --> 编译错误 } } // 实例化Bird对象(多态) Animal bird = new Bird(); // 返回该局部内部类对象 // 因为在局部内部类中,我们没有使用外部的局部变量num,则局部变量num就在此处“死亡”。 // 因为在局部内部类中,我们使用了外部的局部变量num,则该局部变量num就和局部内部类对象的生命周期保持一致啦 return bird; } } public class Test02 { public static void main(String[] args) { // 获得Animal抽象类的实现类对象 // 父类引用指向子类对象(多态) // bird对象的编译时类型为“Animal”,bird对象的运行时类型为“Bird” Animal bird = Outer.getAnimalInstance(); // 调用eat()方法,涉及到多态情况下调用成员方法的特点 // 编译时:检查“编译时类型”,也就是检查Animal类中是否有eat()方法 // 运行时:检查“运行时类型”,也就是调用Bird类中的eat()方法。、 bird.eat(); } // 执行到此处,则意味着bird对象被销毁,那么则局部变量num也在此处“死亡” }
匿名内部类(重点)
匿名内部类的引入
需求1:定义一个方法,在该方法体中定义一个继承于某个抽象类的局部内部类,然后再创建该局部内部类对象并调用方法。
// 需求1:定义一个方法,在该方法体中定义一个继承于某个抽象类的局部内部类,然后再创建该局部内部类对象并调用方法。 // 抽象类 abstract class Animal { public abstract void eat(); } // 外部类 class OuterClass01 { public static void method() { // 需求:定义继承于Animal类的局部内部类,并且创建该局部内部类对象。 // 方式一:使用“局部内部类”来实现 /*// 定义一个继承于Animal的局部内部类 class Bird extends Animal { @Override public void eat() { System.out.println("小鸟在吃虫子..."); } } // 实例化Bird对象(多态) // bird对象的编译时类型为“Animal”,bird对象的运行时类型为“Bird” Animal bird = new Bird(); // 调用eat()方法,设计到多态情况下调用成员方法的特点 // 编译时:检查“编译时类型”,也就是检查Animal类中是否有eat()方法 // 运行时:检查“运行时类型”,也就是调用Bird类中的eat()方法 bird.eat();*/ // 方式二:使用“匿名内部类”来实现 // 父类引用指向子类对象(多态) // bird对象的编译时类型为“Animal”,bird对象的运行时类型为“继承于Animal类的实现类” Animal bird = new Animal() { String name; public void show() { System.out.println("show ..."); } @Override public void eat() { System.out.println("小鸟在吃虫子..."); } }; // 调用eat()方法,设计到多态情况下调用成员方法的特点 // 编译时:检查“编译时类型”,也就是检查Animal类中是否有eat()方法 // 运行时:检查“运行时类型”,也就是调用“继承于Animal类的实现类”中的eat()方法 bird.eat(); // 需求:操作匿名内部类中特有的成员变量 // 问题:多态情况下,操作成员变量的特点??? // 编译时:检查“编译时类型”,也就是检查Animal类中是否有name成员变量。 // 运行时:检查“编译时类型” // System.out.println(bird.name); // 编译错误 // 需求:调用匿名内部类中特有的成员方法 // 问题:多态情况下,调用成员方法的特点??? // 编译时:检查“编译时类型”,也就是检查Animal类中是否有show()方法。 // 运行时:检查“运行时类型” // bird.show(); // 编译错误 // 方式三:使用“匿名对象+匿名内部类”来实现 /*new Animal() { @Override public void eat() { System.out.println("小鸟在吃虫子..."); } }.eat();*/ } } public class Test01 { public static void main(String[] args) { OuterClass01.method(); } }需求2:定义一个方法,在该方法体中定义一个实现于某个接口的局部内部类,然后再创建该局部内部类对象并调用方法。
// 需求2:定义一个方法,在该方法体中定义一个实现于某个接口的局部内部类,然后再创建该局部内部类对象并调用方法。 // 接口 interface Flyable { void showFly(); } // 外部类 class OuterClass02 { public static void method() { // 需求:定义一个实现于Flyable接口的局部内部类,然后再创建该局部内部类对象。 // 方式一:使用“局部内部类”来实现 /*// 定义一个实现于Flyable接口的局部内部类 class Bird implements Flyable { @Override public void showFly() { System.out.println("小鸟自由自在的飞翔..."); } } // 实例化Bird对象(多态) // bird对象的编译时类型为“Flyable”,bird对象的运行时类型为“Bird” Flyable bird = new Bird(); // 调用showFly()方法,涉及到多态情况下调用成员方法的特点 // 编译时:检查“编译时类型”,也就是检查Flyable接口中是否有showFly()方法 // 运行时:检查“运行时类型”,也就是执行Bird类中的showFly()方法 bird.showFly();*/ // 方式二:使用“匿名内部类”来实现 /*// 父类引用指向子类对象(多态) // bird对象的编译时类型为“Flyable”,bird对象的运行时类型为“实现于Flyable接口的实现类” Flyable bird = new Flyable() { @Override public void showFly() { System.out.println("小鸟自由自在的飞翔..."); } }; // 调用showFly()方法,涉及到多态情况下调用成员方法的特点 // 编译时:检查“编译时类型”,也就是检查Flyable接口中是否有showFly()方法 // 运行时:检查“运行时类型”,也就是执行“实现于Flyable接口的实现类”中的showFly()方法 bird.showFly();*/ // 方式三:使用“匿名对象+匿名内部类”来实现 new Flyable() { @Override public void showFly() { System.out.println("小鸟自由自在的飞翔..."); } }.showFly(); } } public class Test02 { public static void main(String[] args) { OuterClass02.method(); } }
匿名内部类的概述
- 匿名内部类本质就是一个“局部内部类”,也就是一个“没有名字”的局部内部类,也就是一个特殊的局部内部类。
匿名内部类的语法
-
[修饰符] class 外部类 { { // 位置一:创建一个继承于某个父类的局部内部类对象,该局部内部类没有名字。 // 第一步:定义了一个继承于某个父类的局部内部类,并且该局部内部类没有名字。 // 第二步:创建该局部内部类对象,也就是常见了一个没有名字的局部内部类对象。 new 父类名() { // 书写匿名内部类中的代码 }; } [修饰符] 返回值类型 方法名(形参列表) { // 位置二:创建一个实现于某个接口的局部内部类对象,该局部内部类没有名字。 // 第一步:定义一个实现于某个接口的局部内部类,并且该局部内部类没有名字 // 第二步:创建该局部内部类对象,也就是常见了一个没有名字的局部内部类对象 new 接口名() { // 书写匿名内部类中的代码 }; } }匿名内部类的注意点
- a)匿名内部类就是一个特殊的局部内部类,因此局部内部类的要求对于匿名内部类依旧生效。
- b)在匿名内部类中,我们不能定义构造方法,因为匿名内部类都没有类名,而构造方法名必须为类名。
- c)在匿名内部类中,我们不建议定义自己“特有”的成员变量和成员方法,因为这样不方便我们去操作。
- 注意:在匿名内部类中,我们一般用于重写父类或接口中的抽象方法。
DAY16
异常的概述
什么是异常?
- 程序在执行过程中,发生的各种不正常情况,我们就称之为“异常”。
- 例如:算数异常、数组索引越界异常、空指针异常和类型转换异常等等
什么是异常类?
- 用于封装和描述各种不正常情况的类,我们就称之为“异常类”。
- 例如:ArithmeticException、ArrayIndexOutOfBoundsException、NullPointerException和ClassCastException等等。
学习异常的好处?
- a)学习异常之后,就能够实现把“正常逻辑代码”和“错误逻辑代码”相分离。
- b)没有学习异常,则某些情况下无论我们如何处理,则都可能无法满足需求。
异常的处理机制?
- 在java语言中,使用面向对象的思想来处理异常。在可能出现问题的位置,我们创建并抛出一个异常对象,该异常对象中封装了异常的详细描述信息(异常类名、异常位置和异常原因),从而实现“正常逻辑代码”和“错误逻辑代码”相分离。
eg:
public class Test01 { // 根据索引获得数组元素的值 public static int getValue(int[] arr, int index) { // 如果index的取值不合法,则抛出一个异常即可 if (index < 0 || index >= arr.length) { throw new ArrayIndexOutOfBoundsException("数组索引越界,index:" + index); } // 执行到此处,则证明index取值合法,则返回索引对应的元素值 int value = arr[index]; return value; } public static void main(String[] args) { int[] arr = {11, 22, 33, 44, 55}; int value = getValue(arr, 12); System.out.println(value); } }
异常的体系
异常体系的引入
- 在程序执行的过程中,可能会发生各种各样的不正常情况,因此我们就需要很多的异常类来封装和描述这些不正常情况,我们对这些异常类进行“向上提取”,那么就得到了异常的继承体系。
异常体系的概述
所有Java类的老祖宗为Object类,所有不正常情况类的老祖宗就是Throwable类,那么Throwable类的继承体系如下:
/* Throwable --> 所有不正常情况类的老祖宗 |-- Error --> 所有错误类的老祖宗 |-- Exception --> 所有异常类的老祖宗 */ //注意:a)如何查看某个类的继承体系呢???选中该类,然后使用“ctrl + h”来查看继承体系。 // b)所有错误类的后缀都以“Error”来结尾,所有异常类的后缀都以“Exception”来结尾。
Throwable的概述
Throwable类是所有不正常情况类的老祖宗,Error类和Exception类都属于Throwable的子类,因此Error类和Exception类都能使用Throwable提供的方法。
public String getMessage() { ... } //作用:返回异常出现的原因。 public String toString() { ... } //作用:返回异常的类名+异常的原因。 public void printStackTrace() { ... } //作用:把异常的类名、异常的位置和异常的原因在控制台输出。
Error类的概述
Error类是所有“错误类”的老祖宗,并且Error类继承于Throwable类,因此Error类能使用Throwable类提供的所有方法。
Error描述的是“资源耗尽”或“虚拟机内部错误”等不正常情况,因此开发中遇到这样的不正常情况,我们程序员是无法解决的(不结束程序的前提来解决),也就是程序员只能先结束程序,然后再去重新修改代码来搞定这种不正常情况,例如:
//案例1:栈内存溢出错误(StackOverflowError) public static void main(String[] args) { main(null); } //案例2:堆内存溢出错误(OutOfMemoryError) long[] arr = new long[1024*1024*1024]; // 创建数组占用的堆内存为:8GB
Exception类的概述
- Exception类是所有“异常类”的老祖宗,并且Exception类继承于Throwable类,因此Exception类能使用Throwable类提供的所有方法。
- Exception类描述的是“程序员能够解决”的不正常情况,开发中我们遇到了Exception异常,则需要拼尽全力去解决该异常(不结束程序的前提来解决)。
- Error属于程序员无法解决的不正常情况,而Exception属于程序员能够解决的不正常情况。
Error与Exception的区别
- 我开着车走在路上,一头猪冲在路中间,我刹车,这叫一个异常。
- 我开着车在路上,发动机坏了,我停车,这叫错误。
- 发动机什么时候坏?我们普通司机能管吗?不能。发动机什么时候坏是汽车厂发动机制造商的事。
自定义异常类(掌握)
自定义异常类的引入
- 问题:给学生年龄复制的时候,则赋值的年龄不能为负数。
- 解决:如果赋值的年龄为负数,则无论我们给年龄赋值任何数据都不合理,那么最好的方案就是如果年龄不合法就抛出异常。
- 问题:如果赋值的年龄不合法,则应该抛出“学生年龄不合法异常”,该如何实现???
- 解决:使用“自定义异常类”来解决。
什么时候使用自定义异常类
- 当Java语言提供的异常类无法满足我们的需求,则我们就可以使用“自定义异常类”来满足需求。
自定义异常类的要求
要求1:自定义异常类必须继承于异常体系中的类,一般继承于Exception类或RuntimeException类。
–> 只有继承于异常体系的中的类,该类才具备可抛型,也就是才能使用throw和throws关键字。
要求2:自定义异常类必须提供两个构造方法,其中一个为无参构造方法,另外一个为字符串参数的有参构造方法。
–> 使用字符串参数的有参构造方法,我们可以用于封装和保存异常出现的原因,从而传递给父类的异常来保存。
eg:
/** * 学生年龄越界异常类 */ public class StudentAgeOutOfBoundsException extends RuntimeException { /** * 无参构造方法 */ public StudentAgeOutOfBoundsException() { super(); } /** * 有参构造方法 * @param message 用于保存异常产生的原因 */ public StudentAgeOutOfBoundsException(String message) { super(message); } }package com.bjpowernode.p2.exception; public class Student { private String name; private int age; public Student() { } public Student(String name, int age) { this.name = name; setAge(age); } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } // 假设:学习年龄的合法取值范围在[0, 130]之间 public void setAge(int age) { // 1.如果赋值的年龄不合法,则抛出一个异常 if (age < 0 || age >= 130) { // 问题:此处我们应该抛出什么异常呢???抛出“学生年龄越界异常” throw new StudentAgeOutOfBoundsException("赋值的年龄不合法,age:" + age); } // 2.执行到此处,则意味着赋值年龄合法,那么就执行赋值操作 this.age = age; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + '}'; } }
异常产生的过程?
1. 如果在方法体中抛出了异常,而我们在方法体中又没有处理该异常,则就会把该异常继续抛给方法的上层调用者,也就是抛给方法的上层调用者来处理。
2. 如果方法的上层调用者依旧没有处理该异常,那么就会继续把该异常抛给方法的上层调用者来处理,以此类推,如果方法的上层调用者都没有处理该异常,那么最终就把该异常抛给了main方法的调用者(虚拟机),而虚拟机也不会处理该异常,那么程序就终止啦。

手动抛出异常(throw)
在可能出现异常的位置,我们创建并抛出一个异常对象,该异常对象中包含了异常的详细描述信息(异常类名、异常位置和异常原因),从而实现了“正常逻辑代码”和“错误逻辑代码”相分离。
注意:throw关键字只能在方法体中使用,也就是我们只能在方法体中来手动抛出一个异常。
eg:
public class Test02 { public static int getValue(int[] arr, int index) { // 如果index的取值不合法,则就抛出数组索引越界异常 if (index < 0 || index > arr.length) { throw new ArrayIndexOutOfBoundsException("数组索引越界异常,index:" + index); } // 执行到此处,则意味着index取值合法,那么就返回数组元素 int value = arr[index]; return value; } public static void main(String[] args) { int[] arr = {11, 22, 33, 44, 55}; int value = getValue(arr, 12); System.out.println(value); } }
异常的分类(重点)
异常的分类的引入?
问题:“学生年龄越界异常类”继承于Exception类和RuntimeException类的区别?
答案:“学生年龄越界异常类”继承于Exception类,则抛出“学生年龄越界异常”就会出现编译错误。
“学生年龄越界异常类”继承于RuntimeException类,则抛出 “学生年龄越界异常”就不会出现编译错误。
异常的分类的概述
运行时异常
–> 包含:RuntimeException类及其所有子类。
–> 特点:程序编译时,不强制我们对抛出的异常进行处理(可以处理,也可以不处理)
编译时异常
–>包含:Exception类及其所有子类(排除运行时异常)。
–>特点:程序编译时,强制我们对抛出的异常进行处理(必须处理,否则就会编译错误)。
异常的处理的方式
声明异常(throws)
–> 属于“消极”的处理方式,本质上并没有处理该异常。
捕捉异常(try…catch…finally)
–>属于“积极”的处理方式,本质上已经解决了该异常。
不正常情况的分类补充
可检查异常(CheckedException)
–>包含:编译时异常
–>特点:程序在编译时期,能够检查出程序中出现的不正常情况。
不可检查异常(UnCheckedException)
–>包含:Error和运行时异常
–>特点:程序在编译时期,不能够检查出程序中出现的不正常情况。
面试题【请问throw和throws关键字的区别?】
- 使用位置区别
- throw:必须在“方法体”中使用。
- throws:必须在“方法声明”末尾使用。
- 操作内容区别
- throw:操作是“异常对象”,只能操作一个异常对象。
- throws:操作是“异常类”,可以操作任意多个异常类。
- 具体作用区别
- throw:抛出异常,如果执行了throw关键字,则肯定会出现异常。
- throws:声明异常,如果使用了throws关键字,则未必会出现异常。
声明异常(throws)
声明异常的概述
- 声明异常属于“消极”的处理方式,本质上并没有解决该异常。
- 程序中出现了异常,此时我们又无法处理该异常,那么就使用声明异常来处理。
声明异常的使用?
- 当方法中“可能”会出现异常,此时我们又无法处理该异常,那么就可以使用“声明异常”来处理。也就是在方法声明的末尾,使用throws关键字将方法体中可能抛出的异常声明出来,然后报告给方法的调用者,交给方法的调用者来处理。
声明异常的语法?
[修饰符] 返回值类型 方法名(形参列表) throws 异常类1, 异常类2, 异常类3, ... { // 方法体 return [返回值]; }eg:
public class Test01 { public static int getValue(int[] arr, int index) throws NullPointerException, ArrayIndexOutOfBoundsException { // 如果arr的值为null,则就抛出空指针异常 if (arr == null) { throw new NullPointerException("空指针异常,arr:" + arr); } // 如果index的取值不合法,则就抛出数组索引越界异常 if (index < 0 || index > arr.length) { throw new ArrayIndexOutOfBoundsException("数组索引越界异常,index:" + index); } // 执行到此处,则意味着index取值合法,那么就返回数组元素 int value = arr[index]; return value; } public static void main(String[] args) throws StudentAgeOutOfBoundsException { int[] arr = {11, 22, 33, 44, 55}; int value = getValue(arr, 12); System.out.println(value); /*// 注意:此处我们可以处理该异常,因此应该使用“捕捉异常”来处理。 Student stu = new Student("卧龙", -18); System.out.println(stu);*/ } }
捕捉异常类(try…catch…finally)
捕捉异常的概述
- 捕捉异常属于“积极”的处理方式,本质上就已经处理了该异常。
- 当程序中可能出现异常,此时我们恰好能解决该异常,则就使用捕捉异常来处理。
try…catch组合
语法:
try{ //书写可能出现异常的代码 }catch(异常类 对象){ //用于处理捕获到的异常。 }执行:如果try代码块中没有出现异常,则try代码块中的代码正常执行完毕,然后就直接执行try…catch之后的代码。 如果try代码块中出现了异常,则catch代码块就会立刻捕获到该异常,然后就执行catch代码中的代码,最后再执行try…catch之后的代码。
try…多catch组合
- 语法:
try{ //书写可能出现异常的代码 }catch(异常类 对象){ //用于处理捕获到的异常 }catch(异常类 对象){ //用于处理捕获到的异常 } ...作用:使用try…多catch组合,我们可以实现对try代码块中出现的异常进行“针对性”的处理。
注意:
使用捕捉异常的时候,建议使用“Ctrl + Alt + T”快捷键来生成try…catch…finally代码。
- 选择中可能出现异常的代码,然后使用使用“Ctrl + Alt + T”快捷键来捕捉异常的代码。
在JDK1.8之后,则我们还以可以这样来处理:
catch (NullPointerException | ArrayIndexOutOfBoundsExceptionexception) { ... }- 以上操作不建议使用,因为使用以上操作无法实现对try代码块中出现的异常进行针对性的处理。
使用try…多catch组合的时候,建议把子类异常catch放在前面,把父类异常catch放在后面,否则就会编译错误。
- 捕获异常的时候,属于“从上往下”来顺序匹配,如果父类异常catch放前面,则后面的子类异常catch将永远无法执行。
try…多catch…finally组合
语法:
```java
try{
//书写可能出现异常的代码
}catch(异常类 对象){
// 用于处理捕获到的异常
}
catch(异常类 对象){
// 用于处理捕获到的异常
}
…
finally{
// 无论是否出现异常,则都会执行finally中代码
}注意: - a)即使在try或catch代码块中执行了return操作,则finally代码块中的代码也依旧会执行。当在try或catch中执行“关闭虚拟机”的操作,那么此时finally代码块中的代码才不会执行。 --> **System.exit(0); --> 关闭虚拟机,也就是结束程序,当实参的值为0的时候,代表整除结束程序。** - b)实际开发中,我们经常在finally代码块中完成关闭“资源的操作”,例如:关闭IO流、关闭数据库链接。 - 生活中,打开一个水龙头(打开资源),然后执行洗手的过程中,无论是否出现不正常情况(异常),则我们最终都需要关闭水龙头(关闭资源)。 5. eg: ```java public class Test03 { public static void main(String[] args) { try { Student stu = new Student("卧龙", -18); System.out.println(stu); System.exit(0); // 关闭虚拟机,也就是结束程序 } catch (StudentAgeOutOfBoundsException exception) { exception.printStackTrace(); System.exit(0); // 关闭虚拟机,也就是结束程序 } finally { // 注意:在此处,以下输出语句不会执行! System.out.println("finally"); } // 注意:在此处,以下输出语句不会执行! System.out.println("over"); /*try { Student stu = new Student("卧龙", -18); System.out.println(stu); // return; // 先执行完毕finally中的代码,然后才会结束main方法 } catch (StudentAgeOutOfBoundsException exception) { exception.printStackTrace(); return; // 先执行完毕finally中的代码,然后才会结束main方法 } finally { // 注意:在此处,无论try中是否发生异常,则都执行并输出了“finally” System.out.println("finally"); } // 注意:此处的代码“未必”会执行 System.out.println("over");*/ /*try { Student stu = new Student("卧龙", 18); System.out.println(stu); } catch (StudentAgeOutOfBoundsException exception) { exception.printStackTrace(); } finally { // 注意:在此处,无论try中是否发生异常,则都执行并输出了“finally” System.out.println("finally"); } // 注意:在此处,无论try中是否发生异常,则都执行并输出了“over” System.out.println("over");*/ } }
eg:
public class Test02 { public static int getValue(int[] arr, int index) throws NullPointerException, ArrayIndexOutOfBoundsException { // 如果arr的值为null,则就抛出空指针异常 if (arr == null) { throw new NullPointerException("空指针异常,arr:" + arr); } // 如果index的取值不合法,则就抛出数组索引越界异常 if (index < 0 || index > arr.length) { throw new ArrayIndexOutOfBoundsException("数组索引越界异常,index:" + index); } // 执行到此处,则意味着index取值合法,那么就返回数组元素 int value = arr[index]; return value; } public static void main(String[] args) { try { int[] arr = {11, 22, 33, 44, 55}; int value = getValue(arr, 12); System.out.println(value); } catch (NullPointerException exception) { exception.printStackTrace(); } catch (Exception exception) { exception.printStackTrace(); } System.out.println("over"); /*try { int[] arr = null; // {11, 22, 33, 44, 55}; int value = getValue(arr, 12); System.out.println(value); } // 专门对空指针异常和数组索引越界异常进行处理 catch (NullPointerException | ArrayIndexOutOfBoundsException exception) { exception.printStackTrace(); }*/ /*try { int[] arr = null; // {11, 22, 33, 44, 55}; int value = getValue(arr, 12); System.out.println(value); } // 专门处理空指针异常 catch (NullPointerException exception) { exception.printStackTrace(); } // 专门处理数组索引越界异常 catch (ArrayIndexOutOfBoundsException exception) { exception.printStackTrace(); } System.out.println("over");*/ } }//try...finally组合??? 语法:try { // 书写可能出现异常的代码 } finally { * // 无论是否出现异常,则都会执行finally中代码 * } * 使用前提: * 前提1:当try代码块中出现了异常,此时我们又无法处理该异常,因此就必须省略catch代码块,而是使用声明异常来处理。 * 前提2:无论try代码块中是否出现异常,则我们都需要做“关闭资源”的操作,也就是在finally中关闭资源,因此就必须存在finally代码块。
方法重写之异常(掌握)
原则:子类重写方法声明的异常类型必须小于等于父类被重写方法声明的异常类型【辈分】。
–>此处说的异常,指的是编译时异常,而运行时异常不用管!
要求:a)如果父类被重写方法没有声明异常,则子类重写方法也不能声明异常。
b)如果父类被重写方法声明了异常,则子类重写方法声明的异常类型必须小于等于父类被重写方法声明的异常类型(辈分)。
eg
class AAException extends Exception { } class BBException extends AAException { } class Parent { public void show() throws AAException { System.out.println("Parent show ..."); } } class Child extends Parent { @Override // public void show() throws AAException { // 没问题 // public void show() throws BBException { // 没问题 // public void show() throws Exception { // 编译错误 public void show() throws AAException, BBException { // 没问题 System.out.println("Child show ..."); } } public class Test01 { public static void main(String[] args) { } }
异常链(了解)
解释:在catch代码块中,我们抛出一个描述更加详细的异常,这就是异常链。
eg:
// 分母为零异常类 class DenominatorZeroException extends Exception { public DenominatorZeroException() { } public DenominatorZeroException(String message) { super(message); } } public class Test03 { /** * 功能:获得两个数相除的结果 * 问题:a)除法运算,如果分母为0,则不应该返回任何结果,而此处却返回了结果为0。 * b)除法运算,如果分母为0,则抛出算数异常,那么意味着异常描述不够清晰。 * 解决:使用“异常链”来解决。 */ public static int division(int fenZi, int fenMu) throws DenominatorZeroException { // 1.定义一个变量,用于保存运算的结果 int result = 0; // 2.执行除法运算,并处理了可能出现的算数异常 try { result = fenZi / fenMu; } catch (ArithmeticException exception) { // 需求:在此处,我们需要抛出一个描述更加详细的异常 throw new DenominatorZeroException("分母为零异常,fenMu:" + fenMu); } // 3.返回除法运算的结果 return result; } public static void main(String[] args) { try { int result = division(5, 0); System.out.println(result); } catch (DenominatorZeroException e) { e.printStackTrace(); } System.out.println("over"); } }
try-with-resource
package com.bjpowernode.p7.exception;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/**
* 1.try-with-resource的引入???
* 在JDK1.8之前,想要实现关闭资源的操作,则必须在finally代码块中完成,这样的操作非常麻烦。
* 在JDK1.8之后,想要实现关闭资源的操作,则就可以通过try-with-resource来自动关闭资源,也就是无需再finally代码块关闭资源。
* 2.try-with-resource的语法???
* try (用于实例化需要关闭资源的对象) {
* // 用于书写可能出现异常的代码
* }
* catch (异常类1 对象) {
* // 用于处理捕获到的异常
* }
* catch (异常类2 对象) {
* // 用于处理捕获到的异常
* }
* ......
* 3.try-with-resource的概述???
* 只要是AutoCloseable接口的实现类,则都可以使用try-with-resource来自动关闭资源,也就是自动会调用实现于AutoCloseable接口的close()方法。
*/
class AutoCloseableImpl01 implements AutoCloseable {
public void show() {
System.out.println("AutoCloseableImpl01 show ...");
throw new NullPointerException("空指针异常");
}
@Override
public void close() throws Exception {
System.out.println("AutoCloseableImpl01 close ...");
}
}
class AutoCloseableImpl02 implements AutoCloseable {
public void show() {
System.out.println("AutoCloseableImpl02 show ...");
}
@Override
public void close() throws Exception {
System.out.println("AutoCloseableImpl02 close ...");
}
}
public class Test01 {
public static void main(String[] args) {
// 案例:需要处理两个关闭资源的对象
try (AutoCloseableImpl01 impl01 = new AutoCloseableImpl01();
AutoCloseableImpl02 impl02 = new AutoCloseableImpl02()) {
impl01.show();
impl02.show();
} catch (Exception exception) {
exception.printStackTrace();
}
/*// 案例:只需要一个关闭资源的对象
try (AutoCloseableImpl01 impl01 = new AutoCloseableImpl01()) {
impl01.show();
} catch (Exception exception) {
exception.printStackTrace();
}*/
}
private static void method02() {
// 需求:读取demo.txt文件中的内容,然后再控制台输出。
// 方式二:使用JDK1.8之后的方案
try (FileInputStream fis = new FileInputStream("demo.txt")) {
// 执行读取数据的操作,此代码块无需掌握
int len = 0;
byte[] bytes = new byte[1024];
while ((len = fis.read(bytes)) != -1) {
String str = new String(bytes, 0, len);
System.out.println(str);
}
} catch (FileNotFoundException exception) {
exception.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
private static void method01() {
// 方式一:使用JDK1.8之前的方案
FileInputStream fis = null;
try {
// 创建字节输入流,注意:“demo.txt”文件在项目中不存在,则抛出异常
fis = new FileInputStream("demo.txt");
// 执行读取数据的操作,此代码块无需掌握
int len = 0;
byte[] bytes = new byte[1024];
while ((len = fis.read(bytes)) != -1) {
String str = new String(bytes, 0, len);
System.out.println(str);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fis != null) {
try {
// 关闭流
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
包装类
包装类的引入
- 世界上没有任何一门语言是完全面向对象的,因为面向对象语言中都包含了“基本数据类型”,为了方便“基本数据类型”和“引用数据类型”之间的转换,因此就诞生了“包装类”。
包装类的概述?
明确:每一种基本数据类型都对应一个包装类,因此Java语言中提供的包装类至少有8种。
byte Byte short Short int Integer long Long float Float double Double char Character boolean Boolean //注意:除了int类型和char类型之外,其余基本数据类型对应的包装类名都是“首字母大写”即可。
Number类的概述
java.lang.Number属于一个抽象类,所有的“数值型包装类”都属于Number的实现类,也就意味着所有的数值型包装类都能使用Number抽象类所提供的方法,并且Number抽象类常见的方法如下:
public byte byteValue() { ... } --> 把数值型包装类对象转化为byte类型 public short shortValue() { ... } --> 把数值型包装类对象转化为short类型 public abstract int intValue(); --> 把数值型包装类对象转化为int类型 public abstract long longValue(); --> 把数值型包装类对象转化为long类型 public abstract float floatValue(); --> 把数值型包装类对象转化为float类型 public abstract double doubleValue(); --> 把数值型包装类对象转化为double类型
包装类的作用
作为和基本数据类型对应的类型存在,方便涉及到对象的操作,如Object[]、集合等的操作。
包含每种基本数据类型的相关属性如最大值、最小值等,以及相关的操作方法(这些操作方法的作用是在基本数据类型、包装类对象、字符串之间提供相互之间的转化)。
public class Test01 { public static void main(String[] args) { System.out.println("int类型表示的最大值:" + Integer.MAX_VALUE); System.out.println("int类型表示的最小值:" + Integer.MIN_VALUE); System.out.println("byte类型表示的最大值:" + Byte.MAX_VALUE); System.out.println("byte类型表示的最小值:" + Byte.MIN_VALUE); /*// 问题:数组的定义???数组就是一个存储“相同数据类型”的“有序”集合(容器)。 // 涉及到的技术:向上转型+自动装箱 Object[] arr = {123, 3.14, true, 'a', "abc", new Test01()}; System.out.println(Arrays.toString(arr));*/ } }
基本数据类型和包装类之间的转换
包装类的底层
- 所谓的包装类,则底层中定义了一个对应基本数据类型的“私有常量”来保存数据,包装类其实就是对基本数据类型的数据执行封装的操作。
- 例如:在Integer包装类中,其底层定义了一个int类型的“私有常量”来保存数据,也就是Integer包装类就是对int类型数据执行的封装操作。
基本数据类型转化为包装类
方式一:通过构造方法来实现
public Integer(int value) { ... } //作用:把基本数据类型转化为包装类对象。 public Integer(String s) throws NumberFormatException { ... } //作用:把字符串的内容转化为包装类对象。 //注意:当字符串存储的内容和对应的基本数据类型的数据格式不匹配的时候,则就会抛出“数值格式化异常”方式二:通过valueOf()静态方法来实现
public static Integer valueOf(int i) { ... } //作用:把基本数据类型转化为包装类对象。 public static Integer valueOf(String s) throws NumberFormatException { ... } //作用:把字符串的内容转化为包装类对象。 //注意:当字符串存储的内容和对应的基本数据类型的数据格式不匹配的时候,则就会抛出“数值格式化异常”。注意事项
- 1、针对Character类型,字符串不能转化为Character类型的包装类对象,因为Character类没有提供字符串参数的构造方法和字符串参数的valueOf()方法。
- 2、针对Boolean类型,只有字符串为“true”(不区分大小写)的时候,转化为包装对象的值才为true,否则一律都为false。
- 3、数值型的包装类中(不包含Character和Boolean),形参字符串的内容为必须为数值型,否则抛出NumberFormatException异常。
包装类转化为基本数据类型?
情况一:数值型包装类
–> 数值型包装类都是Number抽象类的实现类,因此数值型包装类使用Number抽象类提供的方法,我们就可以实现把“数值型包装类对象”转化为“数值型”。
情况二:非数值型包装类
–> 针对Character类型,我们可以使用Character类中提供的charValue()方法,从而将“Character对象”转化为对应的“char类型”。
–> 针对Boolean类型,我们可以使用Boolean类中提供的booleanValue()方法,从而将“Boolean对象”转化为对应的“boolean类型”。
eg:
public class Test02 { public static void main(String[] args) { Boolean aBoolean = new Boolean("TrUe"); boolean flag = aBoolean.booleanValue(); System.out.println(flag); // 输出:true /*Character character = new Character('a'); char ch = character.charValue(); System.out.println(ch); // 输出:a*/ /*Double aDouble02 = Double.valueOf("5.12"); int num1 = aDouble02.intValue(); double num2 = aDouble02.doubleValue(); long num3 = aDouble02.longValue();*/ /*Integer integer = Integer.valueOf(123); int num1 = integer.intValue(); double num2 = integer.doubleValue(); long num3 = integer.longValue();*/ /*Boolean aBoolean01 = new Boolean("TrUe"); System.out.println(aBoolean01); // 输出:true Boolean aBoolean02 = Boolean.valueOf("abc"); System.out.println(aBoolean02); // 输出:false*/ /*// 方式二:通过valueOf()静态方法来实现 Integer integer01 = Integer.valueOf(123); System.out.println(integer01); // 输出:123 Integer integer02 = Integer.valueOf("520"); System.out.println(integer02); // 输出:520 Double aDouble01 = Double.valueOf(3.14); System.out.println(aDouble01); // 输出:3.14 Double aDouble02 = Double.valueOf("5.12"); System.out.println(aDouble02); // 输出:5.12*/ /*// 方式一:通过构造方法来实现 Integer integer01 = new Integer(123); System.out.println(integer01); // 输出:123 Integer integer02 = new Integer("520"); System.out.println(integer02); // 输出:520 Double aDouble01 = new Double(3.14); System.out.println(aDouble01); // 输出:3.14 Double aDouble02 = new Double("5.12"); System.out.println(aDouble02); // 输出:5.12*/ } }
DAY17
自动装箱和自动拆箱(超级重点)
自动装箱和自动拆箱的概述
- 在JDK1.5之前,想要实现“基本数据类型”和“包装类”之间的转换,则必须通过调用包装类的方法来手动完成,此操作比较麻烦。
- 在JDK1.5之后,想要实现“基本数据类型”和“包装类”之间的转换,则我们可以通过自动装箱和自动拆箱来完成,此操作非常简单。
自动装箱机制的概述?
解释:当基本数据类型处于需要对象的环境中,则就会触发自动装箱机制,也就是自动会把基本数据类型转化为对应的包装类对象。
底层:当触发自动装箱机制的时候,则默认就会调用包装类的valueOf(xxx x)静态方法,从而将基本数据类型转化为包装类对象。
//例如:Integer integer = 123; --底层--> Integer integer = Integer.valueOf(123);
自动拆箱机制的概述?
- 解释:当包装类对象处于需要基本数据类型的环境中,则就会触发自动拆箱机制,也就是自动会把包装类对象转化为对应的基本数据类型。
- 底层:当触发自动拆箱机制的时候,则默认就会调用包装类的xxxValue()成员方法,从而将包装类对象转化为对应的基本数据类型。
- 例如:int num = new Integer(123); –底层–> int num = new Integer(123).intValue();
自动装箱的缓存问题?
解释:当“整数型”的数据取值范围在[-128, 127]之间的时候,如果触发了自动装箱机制,则就会从“缓存池”中取出一个包装类对象并返回,也就是不会创建新的包装类对象并返回。
当“整数型”的数据取值范围在[-128, 127]之外的时候,如果触发了自动装箱机制,则就会直接创建一个新的包装类对象并返回,也就是不会从缓存池中取出包装类对象来返回。
底层:public static Integer valueOf(int i) { // 如果i的取值在[-128, 127]之间,则直接从“缓存池”中取出一个Integer对象并返回 // 备注:此处IntegerCache属于一个Integer类中的“私有静态内部类”。 // IntegerCache.low:此处low属于int类型的静态常量,并且默认值为:-128 // IntegerCache.high:此处high属于int类型的静态常量,并且默认值为:127 if (i >= IntegerCache.low && i <= IntegerCache.high) // IntegerCache.cache:此处cache属于Integer数组类型的静态常量,数组中存储的元素依次为[-128, 127]之间的Integer对象 // IntegerCache.cache[i + (-IntegerCache.low)]:返回整数i所对应的Integer对象,例如i的值为127,则就返回127的Integer对象,也就是返回cache数组中的最后一个元素 return IntegerCache.cache[i + (-IntegerCache.low)]; // 如果i的取值在[-128, 127]之外,则创建一个新的Integer对象并返回 return new Integer(i); }
自动拆箱的空指针问题?
解释:当触发自动拆箱机制的时候,则默认就会调用包装类的xxxValue()成员方法,如果该包装对象为null,那么触发自动拆箱机制就会抛出空指针异常。
–> 例如:Integer integer = null; int num = integer; // 等效于: int num = integer.intValue();
public class Test01 { public static void main(String[] args) { Integer integer = null; // 此处Integer对象处于需要int类型的环境中,那么就会触发自动拆箱机制 int num = integer; // 等效于: int num = integer.intValue(); /*Integer integer01 = 128; Integer integer02 = 128; System.out.println(integer01 == integer02); // 输出:false System.out.println(integer01.equals(integer02)); // 输出:true*/ /*Integer integer01 = 123; Integer integer02 = 123; System.out.println(integer01 == integer02); // 输出:true System.out.println(integer01.equals(integer02)); // 输出:true*/ } private static void method() { /*// 此处3.14出于需要Double对象的环境中,则就会触发自动装箱机制,也就是会把3.14从double类型转化为Double对象,然后再赋值 Double num = 3.14; // 此处123出于需要Integer对象的环境中,则就会触发自动装箱机制,也就是会把123从int类型转化为Integer对象,然后再赋值 Integer integer = method01(123); System.out.println(integer);*/ /*// 此处Double对象处于需要基本数据类型的环境中,则就会触发自动拆箱机制,也就是会把Double对象转化为double类型,然后再赋值 double num1 = Double.valueOf(3.14); // 此处Integer对象处于需要基本数据类型的环境中,则就会触发自动拆箱机制,也就是会把Integer对象转化为int类型,然后再赋值 int num2 = method02(new Integer(123)); System.out.println(num2);*/ } public static int method02(int num) { // 此处Integer对象处于需要基本数据类型的环境中,则就会触发自动拆箱机制,也就是会把Integer对象转化为int类型,然后再作为返回值 return Integer.valueOf(456); } public static Integer method01(Integer integer) { // 此处456出于需要Integer对象的环境中,则就会触发自动装箱机制,也就是会把456从int类型转化为Integer对象,然后再作为返回值 return 456; } }
十进制和别的进制之间的转换
十进制转化为别的进制?
明确:把十进制转化为别的进制,则我们需要使用integer包装类提供的静态方法来实现。
// 作用:把十进制转化为二进制 public static String toBinaryString(int i) { ... } // 作用:把十进制转化为八进制,返回的结果没有添加前缀“0” public static String toOctalString(int i) { ... } // 作用:把十进制转化为十六进制,返回的结果没有添加前缀“0x”。 public static String toHexString(int i) { ... }
别的进制转化为十进制?
明确:把别的进制转化为十进制,则我们需要使用Integer包装类提供的“int parseInt(String str, int radix)”静态方法来实现。
–> 参数:str用于保存需要转化为数据,此处str保存的数据可以为“二进制”、“八进制”和“十六进制”的数据。 radix用于保存str属于何种进制,例如str保存的数据为二进制,则radix赋值的内容就是2。
注意:八进制转化为十进制的时候,则str保存的八进制可以添加前缀“0”;十六进制转化为十进制的时候,则str保存的十六进制不能添加前缀“0x”
eg:
public class Test03 { public static void main(String[] args) { // 需求:把二进制转化为十进制 int num1 = Integer.parseInt("10111", 2); System.out.println(num1); // 输出:23 // 需求:把八进制转化为十进制 int num2 = Integer.parseInt("054", 8); System.out.println(num2); // 输出:44 // 需求:把十六进制转化为十进制 int num3 = Integer.parseInt("2B", 16); System.out.println(num3); // 输出:43 /*// 需求:把十进制转化为二进制 String bitStr1 = Integer.toBinaryString(23); System.out.println(bitStr1); // 输出:10111 // 需求:把十进制转化为八进制 String bitStr2 = Integer.toOctalString(44); System.out.println(bitStr2); // 输出:54 // 需求:把十进制转化为十六进制 String bitStr3 = Integer.toHexString(43); System.out.println(bitStr3); // 输出:2B*/ } }
基本数据类型和字符串之间的转换
字符串转化为基本数据类型(重要)
明确:使用包装类提供的parseXxx(String str)的静态方法来实现。
Byte static byte parseByte(String s) //将字符串参数解析为带符号的十进制byte 。 Short static short parseShort(String s) //将字符串参数解析为带符号的十进制short 。 Integer static int parseInt(String s) //将字符串参数解析为带符号的十进制int。 Long static long parseLong(String s) //将字符串参数解析为带符号的十进制long。 Float static float parseFloat(String s) //返回一个新 float值,该值被初始化为用指定字符串表示的值。 Double static double parseDouble(String s) //返回一个新 double值,该值被初始化为用指定字符串表示的值。 Boolean static boolean parseBoolean(String s) //将字符串参数解析为boolean值。注意事项:
- 1.不能把字符串转化为char类型,因为Character包装类中没有提供parseChar(String value)方法。
- 2.针对Boolean类型,只有字符串为“true”的时候(不区分大小写),转化为基本类型的值才为true,否则都为false。
- 3.整数型包装类,字符串中的内容必须是十进制整数;浮点型包装类中,字符串中的内容必须为十进制整数或浮点数,否则抛出NumberFormatException异常。
基本数据类型转化为字符串(了解)
明确:把基本数据类型转换为字符串,我们可以使用“+”连接符来实现,也可以使用包装类提供的方法来实现。
所有包装类 String toString() 返回对象的字符串表示形式。 Byte static String toString(byte b) 把byte类型转化为字符串返回。 Short static String toString(short s) 把short类型转化为字符串返回。 Integer static String toString(int i) 把int类型转化为字符串返回。 Long static String toString(long i) 把long类型转化为字符串返回。 Float static String toString(float f) 把float类型转化为字符串返回。 Double static String toString(double d) 把double类型转化为字符串返回。 Boolean static String toString(boolean b) 把boolean类型转化为字符串返回。 Character static String toString(char c) 把char类型转化为字符串返回。
eg:
public class Test02 { public static void main(String[] args) { // 需求:把int类型的数据转化为字符串类型 String str1 = 123 + ""; System.out.println(str1); // 输出:123 String str2 = Integer.toString(123); System.out.println(str2); // 输出:123 /*boolean flag1 = Boolean.parseBoolean("TrUe"); System.out.println(flag1); // 输出:true boolean flag2 = Boolean.parseBoolean("abc"); System.out.println(flag2); // 输出:false*/ /*// 把字符串转化为基本数据类型 int num1 = Integer.parseInt("123"); System.out.println(num1); // 输出:123 double num2 = Double.parseDouble("3.14"); System.out.println(num2); // 输出:3.14 boolean flag = Boolean.parseBoolean("true"); System.out.println(flag);*/ } }
字符串的创建方式
方式一:通过双引号来创建字符串
String str = "hello world";方式二:通过new+构造方法来创建字符串
String str = new String("hello world");
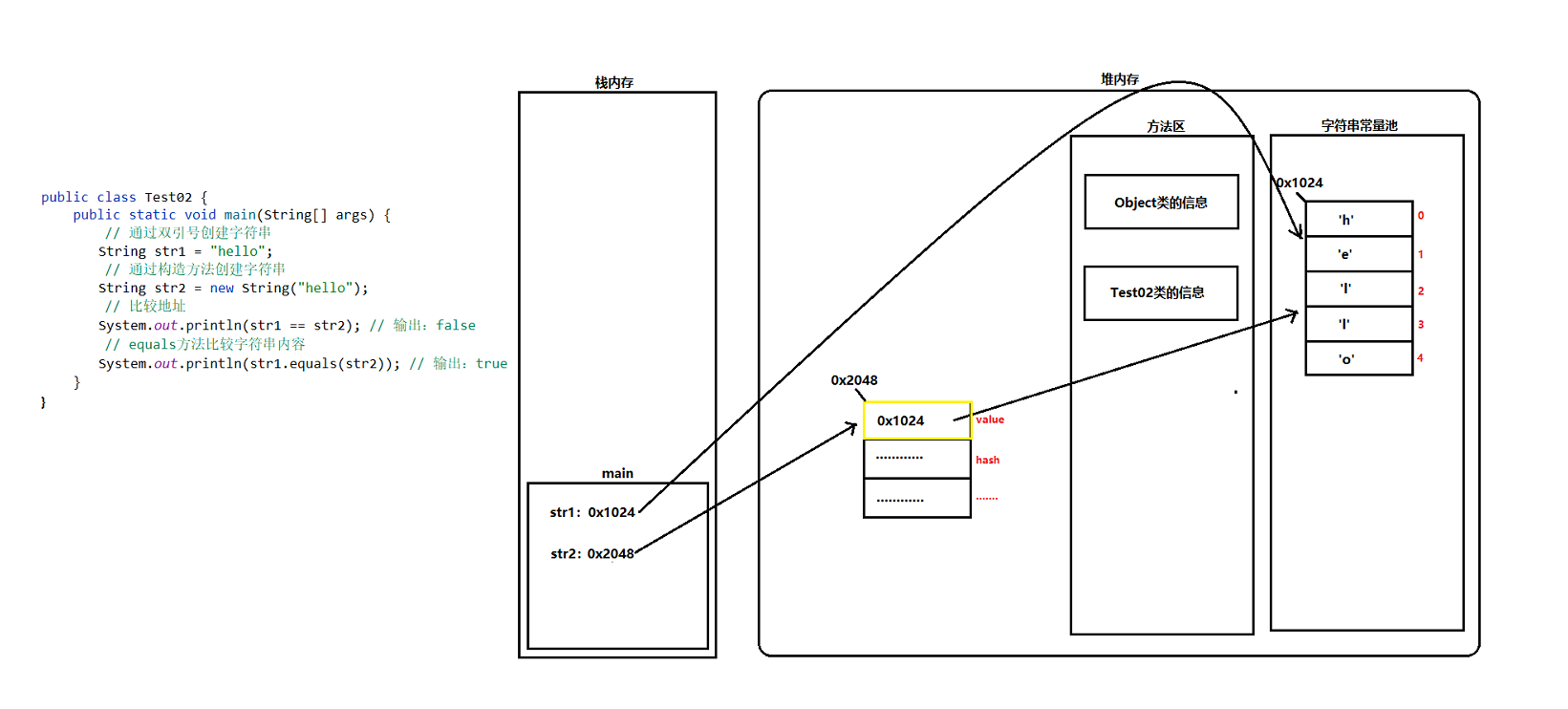
字符串常量池的概述
加载类的时候,如果该类中有双引号创建的字符串,则就把该字符串在常量池中开辟存储空间并存储,并且常量池中存储的字符串都是唯一的。
执行程序的时候,如果遇到了双引号创建的字符串,则直接去常量池中取出该字符串并使用即可,也就是不会再次去创建一个新的字符串。
eg:
public class Test02 { public static void main(String[] args) { // 通过双引号创建字符串 String str1 = "hello"; // 通过构造方法创建字符串 String str2 = new String("hello"); // 比较地址 System.out.println(str1 == str2); // 输出:false // equals方法比较字符串内容 System.out.println(str1.equals(str2)); // 输出:true } private static void method() { String str1 = "hello world"; String str2 = "hello world"; System.out.println(str1 == str2); // 输出:true System.out.println(str1.equals(str2)); // 输出:true /*String str1 = new String("hello world"); String str2 = new String("hello world"); System.out.println(str1 == str2); // 输出:false System.out.println(str1.equals(str2)); // 输出:true*/ } }
字符类(String)
String类的概述
- 在字符串中,存储的是任意多个字符,这些字符以char类型的数组来存储的。在String类中,char类型的数组默认采用了final来修饰,也就意味着char类型的数组不能扩容,也就是字符串中存储的字符内容不可改变,因此我们称String为“不可变的Unicode编码序列”,简称“不可变字符串”。并且,String类还采用了final修饰,则意味着String类不能被继承。
String类的构造方法
String() //初始化新创建的String对象,使其表示空字符序列(不会使用)。 String(String original) //初始化新创建的String对象,新创建的字符串是参数字符串的副本。 String(byte[] bytes) //通过使用平台的默认字符集解码指定的字节数组来构造新的String。 String(char[] value) //分配一个新的String,以便它表示当前包含在字符数组参数中的字符序列。 String(byte bytes[], int offset, int length) //从bytes数组索引为offset位置开始截取length个元素并组成一个字符串。 String(char value[], int offset, int count) //从value数组索引为offset位置开始截取count个元素并组成一个字符串。eg:
public class Test01 { public static void main(String[] args) { // 需求:从value数组索引为offset位置开始截取count个元素并组成一个字符串。 char[] chars = {'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'}; String str = new String(chars, 2, 5); System.out.println(str); // 输出:cdefg /*// 需求:从bytes数组索引为offset位置开始截取length个元素并组成一个字符串。 byte[] bytes = {97, 98, 99, 100, 101, 102, 103}; String str = new String(bytes, 1, 4); System.out.println(str); // 输出:bcde*/ /*// 需求:创建一个字符串,要求字符串内容为字符数组来指定,并且底层的char类型数组空间长度有“字符数组的空间长度”来决定 char[] chars = {'a', 'b', 'c', 'd'}; String str = new String(chars); System.out.println(str); // 输出:abcd*/ /*// 需求:创建一个字符串,要求字符串内容为字节数组来指定,并且底层的char类型数组空间长度有“字节数组的空间长度”来决定 byte[] bytes = {97, 98, 99, 100}; String str = new String(bytes); System.out.println(str); // 输出:abcd*/ /*// 需求:创建一个字符串,要求字符串中存储指定内容,并且底层的char类型数组空间长度为:指定字符串的空间长度 String str = new String("abc"); System.out.println(str); // 输出:abc*/ /*// 需求:创建一个字符串,要求字符串中没有存储任何内容,并且底层的char类型数组空间长度为0 String str = new String(); System.out.println(str); // 输出:*/ } }
String类 的查找方法
length()方法
public int length() { ... } //作用:获得字符串的长度,也就是获得底层char类型数组的空间长度。charAt()方法
public char charAt(int index) { ... } //作用:根据索引获得字符串中的字符。 //注意:index取值范围在[0, 字符串长度-1]之间,超出范围则就会抛出StringIndexOutOfBoundsException异常indexOf()方法
明确:“从前往后”查找某个“字符”或“子串”在“主串”中的索引位置,如果查找的“字符”或“字串”不存在,则返回-1
int indexOf(int ch) //返回指定字符第一次出现在字符串内的索引。 int indexOf(int ch, int fromIndex) //返回指定字符第一次出现在字符串内的索引,以指定的索引开始搜索。 int indexOf(String str) //返回指定子字符串第一次出现在字符串内的索引。 int indexOf(String str, int fromIndex) //返回指定子串的第一次出现在字符串中的索引,从指定的索引开始搜索。 //注意:此处indexOf()方法的底层使用“字符串匹配算法”来实现,常见的字符串匹配算法有:BF算法和KMP算法。
lastIndexOf()方法
明确:“从后往前”查找某个“字符”或“子串”在“主串”中的索引位置,如果查找的“字符”或“字串”不存在,则返回-1
int lastIndexOf(int ch) //返回指定字符最后一次出现在字符串内的索引。 int lastIndexOf(int ch, int fromIndex) //返回指定字符最后一次出现在字符串内的索引,以指定的索引开始搜索。 int lastIndexOf(String str) //返回指定子字符串最后一次出现在字符串内的索引。 int lastIndexOf(String str, int fromIndex) //返回指定子串的最后一次出现在字符串中的索引,从指定的索引开始搜索。
startsWith()方法
public boolean startsWith(String prefix) { ... } // 作用:判断某个字符串是否以prefix开头。endsWith()方法
public boolean endsWith(String suffix) { ... } //作用:判断某个字符串是否以suffix结尾contains()方法
public boolean contains(CharSequence s) { ... } //作用:判断字符串中是否包含某个子串(开头、中间和结尾) //注意:此处CharSequence是一个接口,该接口的实现类有String、StringBuffer和StringBuildereg:
public class Test01 { public static void main(String[] args) { // 需求:判断字符串是否包含“baidu”这个字串 String path = "http://www.baidu.com"; System.out.println(path.contains("baidu")); // 输出:true System.out.println(path.contains("http")); // 输出:true System.out.println(path.contains("com")); // 输出:true System.out.println(path.contains("xixi")); // 输出:false /*// 需求:判断字符串是否以“com”结尾 String path = "http://www.baidu.com"; System.out.println(path.endsWith("com")); // 输出:true System.out.println(path.endsWith("cn")); // 输出:false*/ /*// 需求:判断字符串是否以“http”开头 String path = "http://www.baidu.com"; System.out.println(path.startsWith("http")); // 输出:true System.out.println(path.startsWith("https")); // 输出:false*/ /*String str = "hello hello"; System.out.println(str.lastIndexOf("llo", 6)); // 输出:2 System.out.println(str.lastIndexOf("xixi", 6)); // 输出:-1*/ /*String str = "hello hello"; System.out.println(str.lastIndexOf("llo")); // 输出:8 System.out.println(str.lastIndexOf("xixi")); // 输出:-1*/ /*String str = "hello hello"; System.out.println(str.lastIndexOf('e', 6)); // 输出:1 System.out.println(str.lastIndexOf('a', 6)); // 输出:-1*/ /*String str = "hello hello"; System.out.println(str.lastIndexOf('e')); // 输出:7 System.out.println(str.lastIndexOf('a')); // 输出:-1*/ /*String str = "hello hello"; System.out.println(str.indexOf("llo", 5)); // 输出:8 System.out.println(str.indexOf("xixi", 5)); // 输出:-1*/ /*String str = "hello hello"; System.out.println(str.indexOf("llo")); // 输出:2 System.out.println(str.indexOf("xixi")); // 输出:-1*/ /*String str = "hello hello"; System.out.println(str.indexOf('e', 5)); // 输出:7 System.out.println(str.indexOf('a', 5)); // 输出:-1*/ /*String str = "hello hello"; System.out.println(str.indexOf('e')); // 输出:1 System.out.println(str.indexOf('a')); // 输出:-1*/ /*String str = "hello world"; char ch1 = str.charAt(0); System.out.println(ch1); // 输出:h char ch2 = str.charAt(9); System.out.println(ch2); // 输出:l char ch3 = str.charAt(12); // 抛出字符串索引越界异常*/ /*String str = "hello world"; System.out.println(str.length());*/ } }
String类转换的方法
字符串转数组
String[] split(String regex) //将一个字符串分割为子字符串,并返回字符串数组 char[] toCharArray() //将此字符串转换为新的字符数组。 byte[] getBytes() //得到一个操作系统默认的编码格式的字节数组 //注意:在UTF-8编码中,中文汉字占用3个字节,英文字母占用1个字节。字符串大小写转换
明确:字符串大小写转换,针对“英文字母”有效,针对“中文汉字”无效。
String toUpperCase() //返回一个新的字符串,该字符串中所有英文字符转换为大写字母。 String toLowerCase() //返回一个新的字符串,该字符串中所有英文字符转换为小写字母。 //注意:执行注册或登录操作的时候,就需要使用字符型大小写转换来校对验证码。
忽略字符串前后空格
public String trim() //忽略字符串前后端的空格,中间的空格不用忽略字符串的截取操作
String substring(int beginIndex) //从beginIndex开始截取字符串,到字符串末尾结束。 // 注意:此处beginIndex的取值范围在[0, 字符串长度-1]之间。 String substring(int beginIndex, int endIndex) //从beginIndex开始截取字符串,到字符索引endIndex-1结束。 //注意:beginIndex的取值范围在[0, 字符串长度-1]之间,endIndex的取值范围在[0, 字符串长度]之间,并且endIndex必须大于beginIndex字符串的替换操作
// 通过用newChar字符替换字符串中出现的所有oldChar字符,并返回替换后的新字符串。 String replace(char oldChar, char newChar) //将与字面目标序列匹配的字符串的每个子字符串替换为指定的字面替换序列。 String replace(CharSequence target, CharSequence replacement)字符串拼接的操作
- 明确:我们可以使用“+”连接符来实现字符串的评价操作,也可以使用String类提供的“String concat(String str)”方法来实现。
eg:
public class Test02 { public static void main(String[] args) { // 需求:完成字符串的拼接操作 String str1 = "hello" + "world"; System.out.println(str1); // 输出:helloworld String str2 = "hello".concat("world"); System.out.println(str2); // 输出:helloworld /*// 需求:把字符串中的“CD”替换为“成都” String str = "hello CD hello CD"; String replaceStr = str.replace("CD", "成都"); System.out.println(replaceStr); // 输出:hello 成都 hello 成都*/ /*// 需求:把字符串中的'C'替换为'成' String str = "hello CD hello CD"; String replaceStr = str.replace('C', '成'); System.out.println(replaceStr); // 输出:hello 成D hello 成D*/ /*// 需求:截取字符串索引为[1, 8]之间的字符串 String str = "hello world"; String subStr = str.substring(1, 9); System.out.println(subStr); // 输出:ello wor*/ /*// 需求:从索引为2的位置开始截取字符串,一直截取到字符串的末尾 String str = "hello world"; String subStr = str.substring(2); System.out.println(subStr); // 输出:llo world*/ /*// 需求:忽略字符串前后端的空格,中间的空格不用忽略 String str = " hello world "; String trimStr = str.trim(); System.out.println("aa" + trimStr + "aa"); // 输出:aahello worldaa*/ /*// 需求:把小写字母转化为大写字母 String str = "hello"; String upperCaseStr = str.toUpperCase(); System.out.println(upperCaseStr); // 输出:HELLO // 需求:把大写字母转化为小写字母 String lowerCaseStr = upperCaseStr.toLowerCase(); System.out.println(lowerCaseStr); // 输出:hello*/ /*// 需求:把字符串转化为字节数组 String str = "你好"; byte[] bytes = str.getBytes(); System.out.println(Arrays.toString(bytes)); // 输出:[-28, -67, -96, -27, -91, -67]*/ /*// 需求:把字符串转化为字节数组 String str = "abcd"; byte[] bytes = str.getBytes(); System.out.println(Arrays.toString(bytes)); // 输出:[97, 98, 99, 100]*/ /*// 需求:把字符串转化为char类型的数组 String str = "hello"; char[] chars = str.toCharArray(); System.out.println(Arrays.toString(chars));*/ /*// 需求:根据空格来分割字符串,分割的子串组成一个字符串类型的数组 String str = "hello xixi world haha"; String[] arr = str.split(" "); System.out.println(Arrays.toString(arr));*/ } }
String类的其他方法
isEmpty方法
//作用:判断字符串是否为空,也就是判断底层的char类型数组空间长度是否为0 public boolean isEmpty() { ... }equals方法
boolean equals(Object anObject) //判断字符串内容是否相同,区分字母大小写。 boolean equalsIgnoreCase(String str) //判断字符串内容是否相同,忽略字母大小写。valueOf方法
String类提供了valueOf(xxx x) //这个静态方法,该方法用于将其他的数据类型转化为字符串。eg:
public class Test03 { public static void main(String[] args) { String str1 = String.valueOf(123); String str2 = String.valueOf(3.14); String str3 = String.valueOf(true); String str4 = String.valueOf(new Test03()); /*String str1 = "hEllo"; String str2 = "hello"; System.out.println(str1.equalsIgnoreCase(str2)); // 输出:true*/ /*String str1 = "hello"; String str2 = "hello"; System.out.println(str1.equalsIgnoreCase(str2)); // 输出:true*/ /*String str1 = "hEllo"; String str2 = "hello"; System.out.println(str1.equals(str2)); // 输出:false*/ /*String str1 = "hello"; String str2 = "hello"; System.out.println(str1.equals(str2)); // 输出:true*/ /*// 需求:判断str字符串是否为空 String str = "hello"; boolean isEmpty = str.isEmpty(); System.out.println(isEmpty); // 输出:true*/ /*// 需求:判断str字符串是否为空 String str = ""; boolean isEmpty = str.isEmpty(); System.out.println(isEmpty); // 输出:true*/ } }
StringBuffer类的概述
- StringBuffer类继承于AbstractStringBuilder抽象类,StringBuffer类底层维护者一个char类型的数组,并且该char类型的数组没有使用final修饰,也就意味着该char类型的数组可以自动扩容,也就是该char类型数组存储的元素可以改变,因此我们就称StringBuffer类为“可变的Unicode编码序列”,简称“可变字符串”。并且,StringBuffer类采用了final修饰,也就意味着StringBuffer不能被继承。
String类和StringBuffer类特点
相同点:
- a)底层都维护者一个char类型的数组,也就是存储的都是字符,因此都属于“字符串”。
- b)这个两个类都采用了final修饰,也就意味着String和StringBuffer都不能被继承。
不同点:
String类底层的char类型数组使用了final修饰,因此String类存储的字符内容不可改变,我们就称之为“不可变字符串”。
–> 通过String类提供的方法来操作字符串中的内容时,都不是直接基于char类型数组做的操作,那么都会返回一个新的字符串。
StringBuffer类底层的char类型数组没有使用final修饰,因此StringBuffer类存储的字符内容可以改变,我们就称之为“可变字符串”。
–> 通过StringBuffer类提供方法来操作字符串中的内容,都是直接基于char类型数组做的操作,因此就可以无需返回新的字符串。
StringBuffer类的构造方法
StringBuffer() //构造一个没有字符的字符串缓冲区,初始容量为16个字符(有用)。
StringBuffer(CharSequence seq) //构造一个包含与指定的相同字符的字符串缓冲区CharSequence 。
StringBuffer(int capacity) //构造一个没有字符的字符串缓冲区和指定的初始容量。eg:
public class Test01 {
public static void main(String[] args) {
// 需求:实例化StringBuffer对象,并且可变字符串中没有指定设置内容,而且底层的char类型数组空间长度为:形参的值
StringBuffer sb = new StringBuffer(18);
System.out.println(sb); // 输出:
/*// 需求:实例化StringBuffer对象,并且可变字符串内容可以自定义设置,而且底层的char类型数组空间长度为:形参长度 + 16
StringBuffer sb = new StringBuffer("hello");
System.out.println(sb); // 输出:hello*/
/*// 需求:实例化StringBuffer对象,并且可变字符串中没有指定设置内容,而且底层的char类型数组空间长度为:16
StringBuffer sb = new StringBuffer();
System.out.println(sb); // 输出:*/
}
}StringBuffer类的方法
明确:如果StringBuffer类提供方法的返回值类型为StringBuffer或AbstractStringBuilder,则该返回值就是“当前方法的调用者对象”。
添加的方法
//作用:在可变字符串末尾添加内容。 public AbstractStringBuilder append(Type type) { ... } // 作用:在可变字符串索引为offset位置插入字符串内容。 public AbstractStringBuilder insert(int offset, Type type) { ... } //注意:此处offset的取值范围在[0, 可变字符串长度]之间,超出范围则就会抛出“字符串索引越界异常”。替换的方法
//作用:把可变字符串索引为index的字符替换为ch即可。 public synchronized void setCharAt(int index, char ch) { ... } // 注意:此处index的取值范围在[0, 可变字符串长度 - 1]之间,超出范围则就会抛出“字符串索引越界异常”。 //作用:把可变字符串索引为[start, end)之间的元素替换为str即可。 public synchronized StringBuffer replace(int start, int end, String str) { ... } //注意:此处start的取值范围[0, 可变字符串长度 - 1]之间,end的取值范围在[0, 可变字符串长度]之间,并且end必须大于start。删除的方法
//作用:删除可变字符串中索引为index的字符。 public synchronized StringBuffer deleteCharAt(int index) { ... } // 注意:此处index的取值范围在[0, 可变字符串长度 - 1]之间,超出范围则就会抛出“字符串索引越界异常”。 //作用:删除索引为[start, end)范围之间的元素。 public synchronized StringBuffer delete(int start, int end) { ... } //注意:此处start的取值范围[0, 可变字符串长度 - 1]之间,end的取值范围在[0, 可变字符串长度]之间,并且end必须大于start。查找的方法
charAt(int index) //返回 char在指定索引在这个序列值。 indexOf(String str) //返回指定子字符串第一次出现的字符串内的索引。 indexOf(String str, int fromIndex) //返回指定子串的第一次出现的字符串中的索引,从指定的索引开始。 lastIndexOf(String str) //返回指定子字符串最右边出现的字符串内的索引。 lastIndexOf(String str, int fromIndex) //返回指定子字符串最后一次出现的字符串中的索引,从指定的索引开始。反转的方法
public synchronized StringBuffer reverse() 把可变字符串中的内容进行反转操作操作字符串长度的方法
// 作用:获得可变字符串的长度 public synchronized int length() { ... } // 作用:修改可变字符串的长度。 public synchronized void setLength(int newLength) { ... } //注意:如果“设置的长度”大于“可变字符串的长度”,则默认做“扩容操作”。 //如果“设置的长度”小于“可变字符串的长度”,则默认做“剪切操作”。字符串截取的方法
substring(int start) //返回一个新的 String ,其中包含此字符序列中当前包含的字符的子序列。 substring(int start, int end) //返回一个新的 String ,其中包含此序列中当前包含的字符的子序列。转化为String类的方法
// 作用:把StringBuffer对象转化为String类型。 public synchronized String toString() { ... }eg:
public class Test02 { public static void main(String[] args) { StringBuffer sb = new StringBuffer("hello"); String str = sb.toString(); System.out.println(str); // 输出:hello /*StringBuffer sb = new StringBuffer("hello"); sb.setLength(3); System.out.println(sb); // 输出:hel*/ /*StringBuffer sb = new StringBuffer("hello"); sb.setLength(10); System.out.println("aa" + sb + "aa"); // 输出:aahello aa*/ /*StringBuffer sb = new StringBuffer("hello world"); int length = sb.length(); System.out.println(length); // 输出:11*/ /*StringBuffer sb = new StringBuffer("abc"); sb.reverse(); System.out.println(sb); // 输出:cba*/ /*StringBuffer sb = new StringBuffer("hello world"); sb.delete(2, 10); System.out.println(sb); // 输出:hed*/ /*StringBuffer sb = new StringBuffer("hello world"); sb.deleteCharAt(1); System.out.println(sb); // 输出:hllo world*/ /*StringBuffer sb = new StringBuffer("hello CD hello"); sb.replace(6, 8, "成都市"); System.out.println(sb); // 输出:hello 成都市 hello*/ /*StringBuffer sb = new StringBuffer("hello CD"); sb.setCharAt(6, '成'); System.out.println(sb); // 输出:hello 成D*/ /*StringBuffer sb = new StringBuffer("hello"); sb.insert(3, true); sb.insert(9, 123); System.out.println(sb); // 输出:heltruelo123*/ /*StringBuffer sb = new StringBuffer("hello"); StringBuffer stringBuffer = sb.append(123); System.out.println(stringBuffer == sb); // 输出:true*/ /*StringBuffer sb = new StringBuffer("hello"); sb.append(123); sb.append(true); System.out.println(sb); // 输出:hello123true*/ } }
StringBuilder类的概述
- StringBuilder类继承于AbstractStringBuilder抽象类,StringBuilder类底层维护者一个char类型的数组,并且该char类型的数组没有使用final修饰,也就意味着该char类型的数组可以自动扩容,也就是StringBuilder类存储的字符内容可以改变,因此我们就称呼StringBuilder类为“可变的Unicode编码序列”,简称“可变字符串”。并且,StringBuilder类采用final修饰,也就意味着StringBuilder不能被继承。
StringBuffer类和StringBuilder类的特点
- 相同点
- a)底层都包含char类型的数组,并且该char类型的数组都没使用final修饰,因此都称之为“可变字符串”。
- b)这两个类都采用了final关键字来修饰,也就意味着StringBuffer类和StringBuilder类都不能被继承。
- c)都继承于AbstractStringBuilder抽象类,并且这两个类拥有的方法都相同,因此使用方法属于类似的。
- 不同点
- StringBuffer:线程安全的,会做线程同步检查,因此效率较低(不常用)。
- StringBuilder:线程不安全的,不会做线程同步检查,因此效率较高(常用)。
使用“+”连接符完成字符串拼接操作的底层分析(重点)
情况一:两个字符串都是常量时,使用“+”来完成拼接操作
底层:因为常量保存的内容不可改变,也就是编译时期就能确定常量的值,因此为了提高字符串的拼接效率,所以就在编译时期就完成了拼接操作。
eg1:
String str = "hello" + "world"; 编译之后:String str = "helloworld";eg2:
final String STR1 = "hello"; final String STR2 = "world"; String str = STR1 + STR2; //编译之后:String str = "helloworld";
情况二:其中一个为字符串变量时,使用“+”来完成拼接操作
底层:因为编译时期无法确定变量的值,因此其中一个为字符串变量的拼接操作,那么肯定不是在编译时期完成,而是在运行时期来完成的,并且实现步骤如下。
eg1:【重点】
例如:分析“String hw = str + "world"”代码的底层实现过程 * 第一步:创建一个StringBuilder对象,用于字符串的拼接操作。 * --> StringBuilder sb = new StringBuilder(); * 第二步:调用sb对象的append()方法,用于拼接str字符串。 * --> sb.append(str); * 第三步:调用sb对象的append()方法,用于拼接"world"。 * --> sb.append("world"); * 第四步:调用sb对象的toString()方法,然后再去做赋值操作 * --> String hw = sb.toString();eg2:
public class Test02 { public static void main(String[] args) { String str = "hello"; String hw = str + "world"; System.out.println(str); } /** * 情况一:两个字符串都是常量时,使用“+”来完成拼接操作 */ private static void method02() { final String STR1 = "hello"; final String STR2 = "world"; String str = STR1 + STR2; // 以上三行代码,在编译之后的结果就是:String str = "helloworld"; System.out.println(str); } /** * 情况一:两个字符串都是常量时,使用“+”来完成拼接操作 */ private static void method01() { String str = "hello" + "world"; // 编译之后:String str = "helloworld"; System.out.println(str); } }
三种字符串的拼接效率(重点)
System.currentTimeMillis()方法的概述?
- 作用:获得“当前时间”距离1970年1月1日凌晨的毫秒数。
- –> 公式:1秒 = 1000毫秒
- 使用:计算完成某个功能所需要的耗时,则就可以使用该方法来实现。
- –> 耗时:结束时间 - 开始时间
三种字符串的拼接效率?
StringBuilder的拼接效率最高,StringBuffer的拼接效率次之,String的拼接效率最低。
注意:如果需要大量执行字符串的拼接操作,则建议使用StringBuilder类来完成拼接操作。
public class Test03 { private static int COUNT = 60000; public static void main(String[] args) { Arrays.toString(new int[1]); System.out.println("String类拼接的耗时:" + stringAppend()); System.out.println("StringBuffer类拼接的耗时:" + stringBufferAppend()); System.out.println("StringBuilder类拼接的耗时:" + stringBuilderAppend()); } private static long stringBuilderAppend() { // 1.定义一个变量,用于保存开始时间距离1970年1月1日凌晨的毫秒数 long start = System.currentTimeMillis(); // 2.通过普通for循环,完成StringBuilder类的COUNT次拼接操作 StringBuilder sb = new StringBuilder(); for (int i = 0; i < COUNT; i++) { sb.append(i); } // 3.定义一个变量,用于保存结束时间距离1970年1月1日凌晨的毫秒数 long end = System.currentTimeMillis(); // 4.返回StringBuilder拼接的耗时 return end - start; } private static long stringBufferAppend() { // 1.定义一个变量,用于保存开始时间距离1970年1月1日凌晨的毫秒数 long start = System.currentTimeMillis(); // 2.通过普通for循环,完成StringBuffer类的COUNT次拼接操作 StringBuffer sb = new StringBuffer(); for (int i = 0; i < COUNT; i++) { sb.append(i); } // 3.定义一个变量,用于保存结束时间距离1970年1月1日凌晨的毫秒数 long end = System.currentTimeMillis(); // 4.返回StringBuffer拼接的耗时 return end - start; } private static long stringAppend() { // 1.定义一个变量,用于保存开始时间距离1970年1月1日凌晨的毫秒数 long start = System.currentTimeMillis(); // 2.通过普通for循环,完成String类的COUNT次拼接操作 String str = ""; for (int i = 0; i < COUNT; i++) { str += i; // 使用StringBuilder来完成的拼接 } // 3.定义一个变量,用于保存结束时间距离1970年1月1日凌晨的毫秒数 long end = System.currentTimeMillis(); // 4.返回String拼接的耗时 return end - start; } private static void method() { // 需求:计算完成1+2+3+...+999999+1000000功能的耗时 // 1.定义一个变量,用于保存开始时间距离1970年1月1日凌晨的毫秒数 long start = System.currentTimeMillis(); // 2.完成1+2+3+...+9999999+10000000这个功能 int sum = 0; for (int i = 1; i <= 10000000; i++) { sum += i; } // 3.定义一个变量,用于保存结束时间距离1970年1月1日凌晨的毫秒数 long end = System.currentTimeMillis(); // 4.计算完成该功能所需要的耗时 System.out.println("耗时:" + (end - start)); } }
链式调用语法(了解)
理解:每个成员方法体中都返回this,也就是每个成员方法体中都返回该方法的调用者对象。
问题:在目前已经学习的类中,哪些类支持链式调用语法呢???
答案:StringBuilder和StringBuffer
public class Test04 { public static void main(String[] args) { // 需求:让学生完成吃饭、睡觉和打豆豆的操作 // 方式一:不使用链式调用语法来实现 Student stu = new Student(); stu.eat(); stu.sleep(); stu.play(); System.out.println(); // 方式二:使用链式调用语法来完成 new Student().eat().sleep().play(); } }public class Student { public Student eat() { System.out.println("吃饭"); return this; } public Student sleep() { System.out.println("睡觉"); return this; } public Student play() { System.out.println("打豆豆"); return this; } }
DAY18
时间处理类概述
- 在计算机世界,我们把1970年1月1日凌晨定为基准时间,每个度量单位是毫秒(1秒的千分之一)。
Date类的概述
- java.util.Date我们称之为“时间类”,在程序中我们通过Date对象来保存时间。Date类在JDK1.0版本就诞生,到目前为止Date类中的很多方法都被启用啦,因为Calendar类的出现替代了Date类的很多功能。
Date类的构造方法
//作用:获得保存“当前时间”的Date对象。 public Date() { ... } //作用:获得保存“指定时间”的Date对象。 public Date(long date) { ... } //注意:传入的long类型参数,则表示的就是“指定时间”距离1970年1月1日凌晨的毫秒数。Date类的成员方法
boolean before(Date when)://测试此日期是否在指定日期之前 boolean after(Date when)://测试此日期是否在指定日期之后。 boolean equals(Object obj)://比较两个日期的相等性。 //--------------以上三个方法很少使用,以下两个方法可能使用---------------- long getTime()://返回当前时间距离1970年1月1日凌晨的毫秒数。 void setTime(long time)://使用给定的毫秒时间值设置现有的Date对象。eg:
public class Test01 { public static void main(String[] args) { // 需求:修改Date对象保存的时间,该方法的参数为“设置时间距离1970年1月1日凌晨的毫秒数” Date date = new Date(); // 明确:把date对象保存时间设置为两天之后 date.setTime(date.getTime() + 2 * 24 * 60 * 60 * 1000); System.out.println(date); /*// 需求:获得date对象保存时间距离1970年1月1日凌晨的毫秒数。 Date date = new Date(System.currentTimeMillis() + 2 * 24 * 60 * 60 * 1000); long time = date.getTime(); System.out.println(time);*/ /*Date date1 = new Date(); Date date2 = new Date(System.currentTimeMillis() + 2 * 24 * 60 * 60 * 1000); // 需求:判断date1保存时间是否在date2保存时间之前 // System.out.println(date1.before(date2)); // 输出:true // 需求:判断date1保存时间是否在date2保存时间之后 // System.out.println(date1.after(date2)); // 输出:false // 需求:判断date1保存时间和date2保存时间是否相等 // System.out.println(date1.equals(date2)); // 输出:false*/ /*// 需求:获得保存“指定时间”的Date对象。 Date date = new Date(System.currentTimeMillis() + 2 * 24 * 60 * 60 * 1000); System.out.println(date);*/ /*// 需求:获得保存“当前时间”的Date对象。 Date date = new Date(); System.out.println(date);*/ } }
SimpleDateFormat类的引入
需求:在程序中使用“Date对象”来保存时间,而生活中使用“字符串”来保存时间,如何实现“Date对象”保存时间和“字符串”保存时间之间相互转换呢?
–>解决:使用SimpleDateFormat类来实现。
SimpleDateFormat类的概述
- java.text.SimpleDateFormat类属于DateFormat抽象类的实现类,开发中我们使用SimpleDateFormat类来实现“Date对象”保存时间和“字符串”保存时间之间相互转换,该类在开发中很常用!
时间转换的指定格式规则
当出现 y 时,会将 y 替换成年。 //当出现 M 时,会将 M 替换成月。 当出现 d 时,会将 d 替换成日。 当出现 h 时,会将 h 替换成时(12小时制)。 当出现 H 时,会将 H 替换成时(24小时制)。 当出现 m 时,会将 m 替换成分。 当出现 s 时,会将 s 替换成秒。 //当出现 S 时,会将 S 替换成毫秒。 //当出现D时,获得当前时间是今年的第几天。 当出现w时,获得当前时间是今年的第几周。 //当出现W时,获得当前时间是本月的第几周。SimpleDateFormat类的构造方法
//作用:实例化SimpleDateFormat对象,并且还能设置指定的格式规则 public SimpleDateFormat(String pattern) { ... }SimpleDateFormat类的成员方法
//作用:把Date对象保存时间转化为字符串保存时间。 public final String format(Date date) { ... } // 作用:把字符串保存时间转化为Date对象保存时间。 public Date parse(String source) throws ParseException { ... } // 注意:当“字符串保存时间”的格式和“指定的时间格式”不匹配,则就会抛出ParseException异常。eg:
public class Test02 { public static void main(String[] args) throws ParseException { // 需求:获得Date对象保存时间是本月的第几周。 Date date = new Date(); SimpleDateFormat sdf = new SimpleDateFormat("W"); String format = sdf.format(date); System.out.println(format); /*// 需求:获得Date对象保存时间是今年的第几周 Date date = new Date(); SimpleDateFormat sdf = new SimpleDateFormat("w"); String format = sdf.format(date); System.out.println(format);*/ /*// 需求:获得Date对象保存时间是今年的第几天 Date date = new Date(); SimpleDateFormat sdf = new SimpleDateFormat("D"); String format = sdf.format(date); System.out.println(format);*/ /*// 需求:把字符串保存时间转化为Date对象保存时间,并且字符串时间的格式为“2022年7月30日 13时14分15秒” // 需求:把字符串保存时间转化为Date对象保存时间,并且字符串时间的格式为“2022-7-30 13:14:15” // 1.定义一个字符串,用于保存指定的时间 // String time = "2022年7月30日 13时14分15秒"; String time = "2022-7-30 13:14:15"; // 2.实例化SimpleDateFormat对象,并设置好格式规则 SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); // 3.把字符串保存时间转化为Date对象保存时间 Date date = sdf.parse(time); System.out.println(date);*/ /*// 需求:把Date对象保存时间转化为字符串时间,并且字符串时间的格式为“2022年7月30日 13时14分15秒” // 需求:把Date对象保存时间转化为字符串时间,并且字符串时间的格式为“2022-7-30 13:14:15” // 1.获得保存“指定时间”的Date对象 Date date = new Date(System.currentTimeMillis() + 5 * 60 * 60 * 1000); // 2.实例化SimpleDateFormat对象,并设置好格式规则 // SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒 SSS毫秒"); // 3.把Date对象保存时间转化为字符串保存时间 String format = sdf.format(date); System.out.println(format);*/ } }
Calendar类的概述
- java.util.Calendar我们称之为“日历类”,通过Calendar我们可能表示年、月、日、时、分和秒的一个具体时间,并且Calendar类还提供了日期相关的计算功能,正是因为Calendar类的出现,所以替代了Date类的很多方法。
Calendar类的实例化
- 因为Calendar类是一个抽象类,因此我们就无法直接实例化Calendar对象,而是调用Calendar类的“Calendar getInstance()”静态方法,来获得一个保存“当前时间”的Calendar对象,也就是返回了一个Calendar类的实现类(GregorianCalendar)对象。
Calendar类提供的字段
明确:在Calendar类中提供的字段,默认全部是int类型的“全局静态常量”,也就是这些字段默认采用了“public static final”来修饰。
Calendar.YEAR //获取年份
Calendar.MONTH //获取月份,取值范围在[0, 11]之间,0表示1月,1表示2月,...,11表示12月
Calendar.DAY_OF_MONTH //获取本月的第几天(日)
Calendar.DAY_OF_YEAR //获取本年的第几天
Calendar.HOUR_OF_DAY //小时,24小时制
Calendar.HOUR //小时,12小时制
Calendar.MINUTE //获取分钟
Calendar.SECOND //获取秒
Calendar.MILLISECOND //获取毫秒
Calendar.DAY_OF_WEEK //获取星期几,取值范围在[1, 7]之间,1表示星期日,2表示星期一,...,7表示星期六Calendar类提供的方法
a)获取的方法(了解)
public int get(int field) { ... } //根据字段获得数据b)设置的方法(了解)
public void set(int field, int value) { ... } //根据字段来设置数据 public final void set(int year, int month, int date) { ... } //设置年、月和日的数据 public final void set(int year, int month, int date, int hourOfDay, int minute) { ... } //设置年、月、日、时和分的数据 public final void set(int year, int month, int date, int hourOfDay, int minute, int second) { ... } //设置年、月、日、时、分和秒的数据c)计算的方法(掌握)
public void add(int field, int amount) { ... } //根据字段来“增加”或“减少”数据 //如果amount值为【正数】,则做的是【“添加”】数据的操作;如果amount的值为【负数】,则做的是【“减少”】数据的操作。d)转换的方法(重点)
明确:开发中,我们经常涉及Date对象保存时间和Calendar对象保存时间之间的相互转换,也就是很常用转换相关的方法。
//作用:把Date对象保存时间转化为Calendar对象保存,也就是设置Calendar对象保存时间 public final void setTime(Date date) { ... } //作用:把Calendar对象保存时间转化为Date对象保存时间,也就是获得Calendar对象保存时间 public final Date getTime() { ... }
eg:
public class Test03 { public static void main(String[] args) throws ParseException { // 需求:把Calendar对象保存时间转化为字符串保存时间。 // 分析:Calendar对象 --> Date对象 --> 字符串时间 // 1.获得保存“当前时间”的Calendar对象 Calendar calendar = Calendar.getInstance(); // 2.把Calendar对象保存时间转化为Date对象保存时间,也就是获得Calendar对象保存时间 Date date = calendar.getTime(); // 3.实例化SimpleDateFormat对象,并设置格式规则 SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒"); // 4.把date对象保存时间转化为字符串时间 String format = sdf.format(date); System.out.println(format); } private static void method04() throws ParseException { // 需求:把字符串保存时间转化为Calendar对象来保存该时间。 // 分析:字符串时间 --> Date对象 --> Calendar对象 // 1.定义一个字符串,用于保存某个时间 String time = "2022年5月20日 13时14分15秒"; // 2.实例化SimpleDateFormat对象,并设置格式规则 SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒"); // 3.把字符串时间转化为Date对象来保存 Date date = sdf.parse(time); // 4.获得保存当前时间的Calendar对象 Calendar calendar = Calendar.getInstance(); // 5.把Date对象保存时间转化为Calendar对象保存,也就是设置Calendar对象保存时间 calendar.setTime(date); System.out.println(calendar); } private static void method03() { // 获得“当前时间”的Calendar对象 Calendar calendar = Calendar.getInstance(); // 需求:在当前时间的基础之上添加5年 calendar.add(Calendar.YEAR, 5); // 需求:在当前时间的基础之上减少3月 calendar.add(Calendar.MONTH, -3); System.out.println(calendar); } private static void method02() { // 获得“当前时间”的Calendar对象 Calendar calendar = Calendar.getInstance(); // 根据字段来设置数据 /*calendar.set(Calendar.YEAR, 2020); calendar.set(Calendar.HOUR_OF_DAY, 17);*/ // 设置年、月、日、时、分和秒的数据 calendar.set(2020, 9, 1, 13, 14, 15); System.out.println(calendar); } private static void method01() { // 获得“当前时间”的Calendar对象 Calendar calendar = Calendar.getInstance(); // 根据字段获得数据 System.out.println("年:" + calendar.get(Calendar.YEAR)); // 注意:MONTH的取值范围在[0, 11]之间,0代表1月,1代表2月,依次类推 System.out.println("月:" + (calendar.get(Calendar.MONTH) + 1)); System.out.println("日:" + calendar.get(Calendar.DAY_OF_MONTH)); System.out.println("时(12小时):" + calendar.get(Calendar.HOUR)); System.out.println("时(24小时):" + calendar.get(Calendar.HOUR_OF_DAY)); System.out.println("分:" + calendar.get(Calendar.MINUTE)); System.out.println("秒:" + calendar.get(Calendar.SECOND)); System.out.println("毫秒:" + calendar.get(Calendar.MILLISECOND)); // 注意:DAY_OF_WEEK的取值范围在[1, 7]之间,1代表星期日,2代表星期一,3代表星期二 System.out.println("星期几:" + calendar.get(Calendar.DAY_OF_WEEK)); } }
枚举(enum)
枚举的引入
- 需求:有一个学生类,学生类中有姓名、年龄和性别等属性。
- 实现:定义一个Student类,然后在Student类中定义name、age和sex等成员变量。
- 问题:如果把sex成员变量设置为“char”或“String”类型,则给性别赋值的时候除了能设置“男”和“女”之外,还能设置别的数据。
- 解决:使用“枚举”来解决,也就是把sex成员变量设置为枚举类型。
枚举的语法
[修饰符] enum 枚举名 { 枚举值1, 枚举值2, 枚举值3, ...; } //使用语法:枚举名.枚举值 // 在switch选择结构中,我们使用“枚举值”的时候必须省略“枚举名”,而其余的场合使用“枚举值”则必须通过“枚举名”来操作。枚举的底层
- 对Sex枚举进行反编译,我们发现Sex枚举本质上就是使用final修饰的类,并且显示的继承于java.lang.Enum抽象类
- Sex枚举中的所有枚举值,默认都是Sex类型的全局静态常量,也就是所有的枚举值默认使用了“public static final”来修饰。
- 对Sex枚举进行反编译,发现Sex枚举中还提供了values()的全局静态方法,调用该方法就能返回枚举中的所有枚举值(数组来存储)。
Sex枚举反编译后的结果
public final class Sex extends java.lang.Enum<Sex> { * public static final Sex MAN; * public static final Sex WOMAN; * public static Sex[] values(); * public static Sex valueOf(java.lang.String); * static {}; * } */ public class Test01 { public static void main(String[] args) { Sex[] values = Sex.values(); System.out.println(Arrays.toString(values)); Student stu = new Student("卧龙", 18, Sex.WOMAN); System.out.println(stu); } }eg:
public class Test02 { public static void main(String[] args) { // 需求:随机获得一个季节,然后输出该季节的特点。 // 1.通过values()方法,来获得所有的季节枚举 Season[] seasons = Season.values(); // 2.通过Math提供的方法,随机获得[0, 3]之间的整数 int index = (int) (Math.random() * 4); System.out.println(index); // 3.通过index获得数组元素,也就是获得一个季节 Season season = seasons[index]; // 4.判断season取值(季节),从而输出该季节的特点 switch (season) { case 春: System.out.println("春意盎然"); break; case 夏: System.out.println("夏日炎炎"); break; case 秋: System.out.println("秋高气爽"); break; case 冬: System.out.println("冬雪皑皑"); break; } } }/** * 季节的枚举 */ public enum Season { 春, 夏, 秋, 冬; }/** * 性别的枚举 */ public enum Sex { MAN, WOMAN; }/** * 学生类 */ public class Student { // 成员变量 private String name; private int age; private Sex sex; // 构造方法 public Student() { } public Student(String name, int age, Sex sex) { this.name = name; this.age = age; this.sex = sex; } // setter和getter方法 public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public Sex getSex() { return sex; } public void setSex(Sex sex) { this.sex = sex; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + ", sex='" + sex + '\'' + '}'; } }
System类
public final class System extends Object
//System类包含一些有用的类字段和方法,它不能被实例化。所以该类中的字段和方法一定是静态的。
常用方法:
//从指定源数组中复制一个数组,复制从指定的位置开始,到目标数组的指定位置结束。 static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length) //返回以毫秒为单位的当前时间。 static long currentTimeMillis() //返回最准确的可用系统计时器的当前值,以毫微秒为单位。 static long nanoTime() //终止当前正在运行的 Java 虚拟机。参数用作状态码;根据惯例,非 0 的状态码表示异常终止。 static void exit(int status) // 返回一个不能修改的当前系统环境的字符串映射视图。 Map<String,String> getenv() // 获取指定键指示的系统属性。 static String getProperty(String key) //运行垃圾回收器。 // 调用 gc 方法暗示着 Java 虚拟机做了一些努力来回收未用对象,以便能够快速地重用这些对象当前占用的内存。 static void gc()eg:
public class Demo01 { public static void main(String[] args) { // test01(); // test02(); // test03(); // test04(); test05(); } private static void test05() { /* * stu 在栈内存中 * new Student 在堆中 * */ Student stu = new Student("张三"); System.out.println(stu); /* * 什么时候对象变成垃圾? * 对象引用为null 就会变成垃圾 * * 对象变成垃圾,不一定马上就会被回收,需要垃圾回收器空闲的时候进行回收。 * * 当垃圾回收器确定不存在对该对象的更多引用时,对象的垃圾回收器会调用finalize()方法 。 */ stu = null; System.gc(); // 催促一下垃圾回收回收垃圾,但是依然不敢保证立马回收 } private static void test04() { Map<String, String> map = System.getenv(); String systemRoot = System.getenv("SystemRoot"); System.out.println(map); System.out.println(systemRoot); // 获取操作系统的名称 String property = System.getProperty("os.name"); System.out.println(property); // 获取操作系统的架构 String osArch = System.getProperty("os.arch"); System.out.println("操作系统的架构:" + osArch); // 获取JVM的名称和版本 String vmName = System.getProperty("java.vm.name"); String vmVersion = System.getProperty("java.vm.version"); System.out.println("JVM名称:" + vmName); System.out.println("JVM版本:" + vmVersion); // 获取用户的当前工作目录 String userDir = System.getProperty("user.dir"); System.out.println("当前工作目录:" + userDir); } private static void test03() { /* * java程序是运行在jvm中的,一个java程序一个JVM实例 * JVM退出,那么程序就终止了。 */ for (int i = 0; i < 100; i++) { if(i == 5){ System.exit(0); } System.out.println("i---"+ i); } } private static void test02() { long start = System.currentTimeMillis(); for (int i = 0; i < 100; i++) { } long end = System.currentTimeMillis(); System.out.println("耗时:" + (end - start)); long t = System.nanoTime(); System.out.println(t); } /** * 数组拷贝 * * 在Java中有两处地方的命名是不符合标识符命名规范的,其中一处就是arraycopy() */ private static void test01() { int[] nums = {1,2,3,5,6,4,9}; int[] array = new int[5]; // 需要将nums中数据拷贝到array中 // for (int i = 0; i < array.length; i++) { // array[i] = nums[i]; // } // 【ctrl + p 查看方法的形参】 /* * 第一个参数src: 源数组 * 第二个参数srcPos: 源数组的位置,也就是从源数组的哪个位置开始拷贝数据 * 第三个参数dest: 目的地数组 * 第四个参数destPos: 目的地数组的位置,也就是将拷贝的数据从哪里开始存储 * 第五个参数length: 表示复制多少个数据 * 注意: length一定小于目的地数组的长度 */ System.arraycopy(nums,0,array,0,3); System.out.println(Arrays.toString(array)); } }public class Student { private String name; public Student() { } public Student(String name) { this.name = name; } @Override protected void finalize() throws Throwable { super.finalize(); System.out.println("student被回收了"); } @Override public String toString() { return "Student{" + "name='" + name + '\'' + '}'; } }
UUID类
表示通用唯一标识符(UUID)的类,UUID表示一个128位的值,也就是说UUID的值全球唯一。
//获取类型 4(伪随机生成的)UUID 的静态工厂。 使用加密的强伪随机数生成器生成该 UUID。 public static UUID randomUUID(){...}eg:
public class UUIDDemo01 { public static void main(String[] args) { UUID uuid = UUID.randomUUID(); // 它由一组32位数的16进制数字所构成。 /* * 开发中有时候需要唯一的id,此时可以使用UUID */ System.out.println(uuid); // 0016775d-662a-4418-89af-1236414b5ca0 } }
File类
import java.io.File;
import java.io.FileFilter;
import java.io.FilenameFilter;
import java.io.IOException;
import java.util.Arrays;
/**
* java是面向对象的语言。万事万物皆对象
* 生活中文件或文件夹也是一种物体的,所以文件或文件夹在java中也有对象表示。
* 这个对象就是File的对象
*
* File类:
* 文件和目录(文件夹)路径名的抽象表示形式。
*
* File 类的实例是不可变的;也就是说,一旦创建,File 对象表示的抽象路径名将永不改变。
*
* 构造方法摘要:
* File(File parent, String child)
* 根据 parent 抽象路径名和 child 路径名字符串创建一个新 File 实例。
* File(String pathname)
* 通过将给定路径名字符串转换为抽象路径名来创建一个新 File 实例。
* File(String parent, String child)
* 根据 parent 路径名字符串和 child 路径名字符串创建一个新 File 实例。
*
*
* 常用方法:
* boolean exists()
* 测试此抽象路径名表示的文件或目录是否存在。
* boolean createNewFile()
* 创建一个新的空文件
*
* boolean isDirectory()
* 测试此抽象路径名表示的文件是否是一个目录。
* boolean isFile()
* 测试此抽象路径名表示的文件是否是一个标准文件。
*
* boolean mkdir()
* 创建此抽象路径名指定的目录。
* boolean mkdirs()
* 创建此抽象路径名指定的目录,包括所有必需但不存在的父目录。
*
* boolean canRead()
* 测试应用程序是否可以读取此抽象路径名表示的文件。
* boolean canWrite()
* 测试应用程序是否可以修改此抽象路径名表示的文件。
* boolean isHidden()
* 测试此抽象路径名指定的文件是否是一个隐藏文件。
*
* boolean delete()
* 删除此抽象路径名表示的文件或目录。
* void deleteOnExit()
* 在虚拟机终止时,请求删除此抽象路径名表示的文件或目录。
*
* String getName()
* 返回由此抽象路径名表示的文件或目录的名称。
* String getParent()
* 返回此抽象路径名父目录的路径名字符串;如果此路径名没有指定父目录,则返回 null。
* File getParentFile()
* 返回此抽象路径名父目录的抽象路径名;如果此路径名没有指定父目录,则返回 null。
*
* String getPath()
* 获取文件或文件夹的路径(相对路径)
* 如果new File传入的是绝对路径,获取到的也是绝对路径
* File getAbsoluteFile()
* 返回此抽象路径名的绝对路径名形式。
* String getAbsolutePath()
* 返回此抽象路径名的绝对路径名字符串。
*
* long lastModified()
* 返回此抽象路径名表示的文件最后一次被修改的时间。
* long length()
* 返回由此抽象路径名表示的文件的长度。
*
* boolean renameTo(File dest)
* 剪切拷贝文件并可以重命名文件
*
* String[] list()
* 获取文件夹下的所有文件或子文件夹的名字。
* File[] listFiles()
* 获取文件夹下的所有文件或子文件夹。
*
*
* String[] list(FilenameFilter filter)
* 返回一个字符串数组,这些字符串指定此抽象路径名表示的目录中满足指定过滤器的文件和目录。
* File[] listFiles(FileFilter filter)
* 返回抽象路径名数组,这些路径名表示此抽象路径名表示的目录中满足指定过滤器的文件和目录。
* File[] listFiles(FilenameFilter filter)
* 返回抽象路径名数组,这些路径名表示此抽象路径名表示的目录中满足指定过滤器的文件和目录。
*/
public class FileDemo01 {
public static void main(String[] args) throws IOException {
// test01();
// test02();
// test03();
// test04();
// test05();
// test06();
// test07();
test08();
}
/**
* 过滤器 FilenameFilter
*/
private static void test08() {
File file = new File("D://a");
/*
* 过滤出txt文件
*/
File[] files = file.listFiles(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
return name.endsWith(".txt");
}
});
for (File file1 : files) {
System.out.println(file1);
}
}
/**
* 过滤器 FileFilter
*/
private static void test07() {
File file = new File("D://a");
/*
* 过滤出txt文件
*/
File[] files = file.listFiles(new FileFilter() {
/*
* 这个就是过滤方法
* accept() 返回true表示满足条件,也就是可以接受
*/
@Override
public boolean accept(File pathname) {
// 获取文件名称
String name = pathname.getName();
return name.endsWith(".txt");
}
});
for (File file1 : files) {
System.out.println(file1);
}
}
private static void test06() {
File file = new File("D://a");
/*
* listFiles() 返回的是文件夹下的文件或子文件夹对应的File对象
*/
File[] files = file.listFiles();
for (File file1 : files) {
System.out.println(file1);
}
System.out.println("-----------------------");
/*
* list() 返回的是文件夹下的文件或子文件夹对应的名字
*/
String[] list = file.list();
for (String s : list) {
System.out.println(s);
}
}
private static void test05() {
File file = new File("D://aa.txt");
// 剪切拷贝文件并可以重命名文件
boolean b = file.renameTo(new File("D://a.txt"));
System.out.println(b);
}
/**
* 绝对路径: 使用路径本身就能定位到资源
* File类中绝对路径就是以系统盘符或者是根路径开头的路径
* 比如: D://a.txt
* 相对路径: 路径本身无法定位资源,还需要使用参照路径
* File类中相对路径就是不是以系统盘符或者是根路径开头的路径
* 比如: a.txt
*
* 参照路径就是:File所在类的工程路径
* 该类的路径是 D:\course\JavaProjects\01_JavaSE\
*/
private static void test04() throws IOException {
// 相对路径
// 该文件的绝对路径=参照路径+相对路径 ===》 D:\course\JavaProjects\01_JavaSE\day18\a.txt
File file = new File("day18/a.txt");
// 获取相对路径
System.out.println(file.getPath());
// 获取绝对路径
System.out.println(file.getAbsolutePath());
/*
* 返回文件的内容长度(单位字节)
*/
long length = file.length();
System.out.println(length);
// 文件最后修改时间,返回的是毫秒值
System.out.println(file.lastModified());
}
private static void test03() {
File file = new File("D://a/b/c/");
// 获取文件或文件夹的名字
System.out.println(file.getName()); // c
// 获取文件或文件夹的父路径名称
System.out.println(file.getParent()); // D:\a\b
/*
* 注意: 通过以上两个代码我们得出结论:
* File的路径 = getParent() + getName()
*
* 所有创建对象的时候有了以下的构造函数:
* File(String parent, String child)
* File(File parent, String child)
*/
}
private static void test02() {
File file = new File("D://a.txt");
// canRead() 测试文件是否可读
System.out.println(file.canRead());
/*
* canWrite() 测试文件是否可写
* 返回false,就表示文件或文件夹不能写数据
*/
System.out.println(file.canWrite());
// 删除文件或文件夹
boolean delete = file.delete();
System.out.println(delete);
File file01 = new File("D://b.txt");
/*
* deleteOnExit()表示虚拟机退出的时候删除指定的文件或文件夹
*/
file01.deleteOnExit();
for (int i = 0; i < 20; i++) {
if(i == 10){
// 退出虚拟机
System.exit(0);
}
try {
// 模拟一个延时
Thread.sleep(1000); // 循环1次睡眠1s
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
private static void test01() throws IOException{
// 创建对象
/*
* 根据传入的参数创建一个File对象。
* 此时File对象就表示参数中的文件或者目录
*/
File file = new File("D://xx/yy/");
// 判断指定的文件或目录是否存在
boolean exists = file.exists();
System.out.println(exists);
if(!exists){
// 如果是文件就创建文件
if(file.isFile()){
// 创建文件
file.createNewFile();
}else{
// 创建文件夹
/*
* mkdir() 只能创建一级文件夹
* mkdirs() 创建多级文件夹
*/
file.mkdirs();
}
}
}
}
Math类
/**
* Math: 数学工具类,提供了关于数学操作的一些方法和属性
* Math类全部是静态的方法和字段
*
* 字段:
* static double PI
* 比任何其他值都更接近 pi(即圆的周长与直径之比)的 double 值。
*
*方法摘要:
* static double abs(double a)
* 返回 double 值的绝对值。
* static float abs(float a)
* 返回 float 值的绝对值。
* static int abs(int a)
* 返回 int 值的绝对值。
* static long abs(long a)
* 返回 long 值的绝对值。
* static double ceil(double a)
* ceil是天花板的意思。所以ceil表示向上取整
* static double floor(double a)
* floor是地板的意思。所以floor表示向下取整
*
* static double max(double a, double b)
* 返回两个 double 值中较大的一个。
* static float max(float a, float b)
* 返回两个 float 值中较大的一个。
* static int max(int a, int b)
* 返回两个 int 值中较大的一个。
* static long max(long a, long b)
* 返回两个 long 值中较大的一个。
*
* static double min(double a, double b)
* 返回两个 double 值中较小的一个。
* static float min(float a, float b)
* 返回两个 float 值中较小的一个。
* static int min(int a, int b)
* 返回两个 int 值中较小的一个。
* static long min(long a, long b)
* 返回两个 long 值中较小的一个
*
* static double pow(double a, double b)
* 返回第一个参数的第二个参数次幂的值。
*
* static double random()
* 返回带正号的 double 值,该值大于等于 0.0 且小于 1.0。
*
* static long round(double a)
* 返回最接近参数的 long。(四舍五入)
* static int round(float a)
* 返回最接近参数的 int。(四舍五入)
*
*/
public class MathDemo01 {
public static void main(String[] args) {
// 圆周率,是一个常量
System.out.println(Math.PI);
// 绝对值
System.out.println(Math.abs(-100));
// 立方根
System.out.println(Math.cbrt(27));
/*
* ceil表示向上取整,如果参数就是整数,返回数据本身
* 只有参数是浮点数才会向上取整
*/
System.out.println(Math.ceil(200)); // 200.0
System.out.println(Math.ceil(200.99));// 201.0
/*
* floor表示向下取整,如果参数就是整数,返回数据本身
* 只有参数是浮点数才会向下取整
*/
System.out.println(Math.floor(200)); // 200.0
System.out.println(Math.floor(200.99));// 200.0
// max 和 min
System.out.println(Math.max(10,5)); // 10
System.out.println(Math.min(10,5)); // 5
// 求出 10 3 5的最大值
// int max = Math.max(10, 3);
// System.out.println(Math.max(max,5));
System.out.println(Math.max(Math.max(10, 3),5)); // 10
// 计算3的2次方
System.out.println(Math.pow(3,2)); // 9.0
// 获取1-10的随机数
// [0,1) --> [0,10) ---> [1,11)
int r = (int) (Math.random() * 10 + 1);
System.out.println(r);
/*
* round() 四舍五入
* =====> (long)Math.floor(a + 0.5d)
*/
System.out.println(Math.round(3.45)); // 3
System.out.println(Math.round(3.55)); // 4
System.out.println(Math.round(-3.45)); // -3
System.out.println(Math.round(-3.55)); // -4
}
}
递归
就是方法体中直接或间接地调用自身。
使用递归:
- 必须创建方法;
- 防止死递归 – 有结束条件(出口 / 递归头);
- 死递归会造成栈溢出错误:StackOverflowError
- 构造方法不能使用递归。
public class RecursionDemo {
public static void main(String[] args) {
// 这个不是递归
// int max = Math.max(Math.max(3, 2), 1);
// System.out.println(max);
// m01();
m02();
}
/**
* 死递归,会栈溢出---》StackOverflowError
*/
// public static void m01(){
// System.out.println("hello");
// m01();
// }
static int count = 0;
public static void m02(){
count++;
System.out.println("hello");
if(count < 3){
m02();
}
}
}递归的思想:将一个大的问题拆分成几个小问题,小问题解决了,大问题也就的到解决了。
注意:可以使用循环的一定可以使用递归,反之不一定。
递归和循环的选择:
- 如果循环嵌套层次过多才能解决问题,可以使用递归。
/* 需求: 求阶乘:
5!= 5 * 4 * 3 * 2 * 1 -- 大问题
5!= 5 * 4! ---- 小问题,由求5的阶乘变成了求4的阶乘
4!= 4 * 3!; ---- 小问题,由求4的阶乘变成了求3的阶乘
3!= 3 * 2!; ---- 小问题,由求3的阶乘变成了求2的阶乘
2!= 2 * 1!; ---- 小问题,由求2的阶乘变成了求1的阶乘
1!= 1; ---- 小问题,由求1的阶乘
以上是将大问题查分成多个小问题,小问题的结果需要汇总回来,最终大问题得到解决。
*/
/**
* 阶乘
* 需求: n!;
*/
public class FactorialDemo {
public static void main(String[] args) {
System.out.println(factorial01(5));
System.out.println(factorial02(5));
}
/**
* 使用递归求阶乘
* 1. 递: 将大问题分成小问题
* n! = n * (n-1)!
* 2. 归: 汇总小问题的结果
* 3. 必须有结束条件
*/
public static int factorial02(int n){
// 负数没有阶乘
if(n < 0){
throw new RuntimeException("负数没有阶乘");
}
// 必须有结束条件
if(n == 1 || n == 0){
return 1;
}
/*
* n * factorial02(n-1) --> 递: 将大问题分成小问题
*
* return 归: 汇总小问题的结果
* 递归中有return返回结果,这种属于明显的汇总结果 --> 明显的结束条件
* 有时候使用的递归有return返回结果,这种属于不明显的汇总结果--> 不明显的结束条件
*/
return n * factorial02(n-1);
}
/**
* 使用循环计算阶乘
*/
public static int factorial01(int n){
int res = 1;
for (int i = 1; i <= n; i++) {
res *= i;
}
return res;
}
}
eg1:
/**
* 不死神兔:
* 假如有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第三个月后每个月又生一对兔子,
* 假如兔子都不死,请问第n个月后的兔子有多少对?
*
* 1 1 2 3 5 8 13 21 34 ... 斐波拉契数列
*
* 月份越大,对数越多 ---> 月份往上是无边界的
* 分解:
* 从第三个数开始,将数分解成前两个数据之和
* 从第三个数据开始,后面的数据是前面两个数据之和,前面的数据又可以用更前面的两个数据之和得到
* 所以数据可以一致往前分解,直到什么时候停止分解?
* 就是n=1或者n=2
*
* 使用递归:
* 1. 定义方法
* 2. 分解
* 3. 结束条件
*
*/
public class RecursionDemo01 {
public static void main(String[] args) {
System.out.println(getRabbitNum(4));
}
public static int getRabbitNum(int n){
if(n <= 0){
throw new RuntimeException("没有这个月份");
}
if(n == 1 || n == 2){
return 1;
}
return getRabbitNum(n-2) + getRabbitNum(n - 1);
}
}
eg2:
import java.io.File;
/**
* 遍历盘符下所有的目录和文件
*
* 分析:
* 1. 获取目录下的所有内容
* 2. 判断目录下中的内容
* 是文件: 直接输出
* 是文件夹: 回到1
*
* 所以以上的步骤是重复的代码,所以可以使用递归
*
* 使用递归:
* 1. 创建方法
*/
public class Demo01 {
public static void main(String[] args) {
File file = new File("D://a");
// printFile(file);
printFile(file,0);
}
public static void printFile(File file){
// 1. 获取目录下的所有内容
File[] files = file.listFiles();
for (File file1 : files) {
// 2. 判断目录下中的内容
if(file1.isFile()){
// 是文件: 直接输出
System.out.println(file1);
}else{
System.out.println(file1);
// 是文件夹: 回到1
printFile(file1);
}
}
}
/**
* 分析:
* 1. 输出file
* 2. 如果file是文件夹,就获取文件夹中的所有内容
* 回到1
*
*/
public static void printFile(File file,int level){
for (int i = 0; i < level; i++) {
System.out.print("-");
}
System.out.println(file.getPath());
if(file.isDirectory()){
File[] files = file.listFiles();
for (File file1 : files) {
printFile(file1,level + 1);
}
}
}
}
eg3:
import java.io.File;
/**
* 删除多级文件夹
*
* 注意: 删除文件夹,只能删除空文件夹
* 所以删除多级文件夹必须从里向外删除
*
* 分析:
* 因为参数接受的是File,File表示文件或文件夹,所以
* 要判断File的类型
* 1. 判断是文件还是文件夹
* 2. 是文件直接删除
* 3. 是文件夹,获取文件夹下的所有内容
* 回到1
* 文件删除完后删除文件夹
*
*/
public class DeleteFloderDemo {
public static void main(String[] args) {
File file = new File("D://a");
deleteFloder(file);
}
public static void deleteFloder(File file){
// 增加代码的健壮性
if(file == null || !file.exists()){
return;
}
// 1. 判断是文件还是文件夹
if(file.isFile()){
// 2. 是文件直接删除
file.delete();
}else{
// 3. 是文件夹,获取文件夹下的所有内容
File[] files = file.listFiles();
for (File file1 : files) {
deleteFloder(file1);
}
// 当以上的for循环执行完成,就表示目录中的所有文件删除,此时目录就是空的,可以删除了
file.delete();
}
}
}
DAY19
集合_Collection根接口
集合的继承体系:
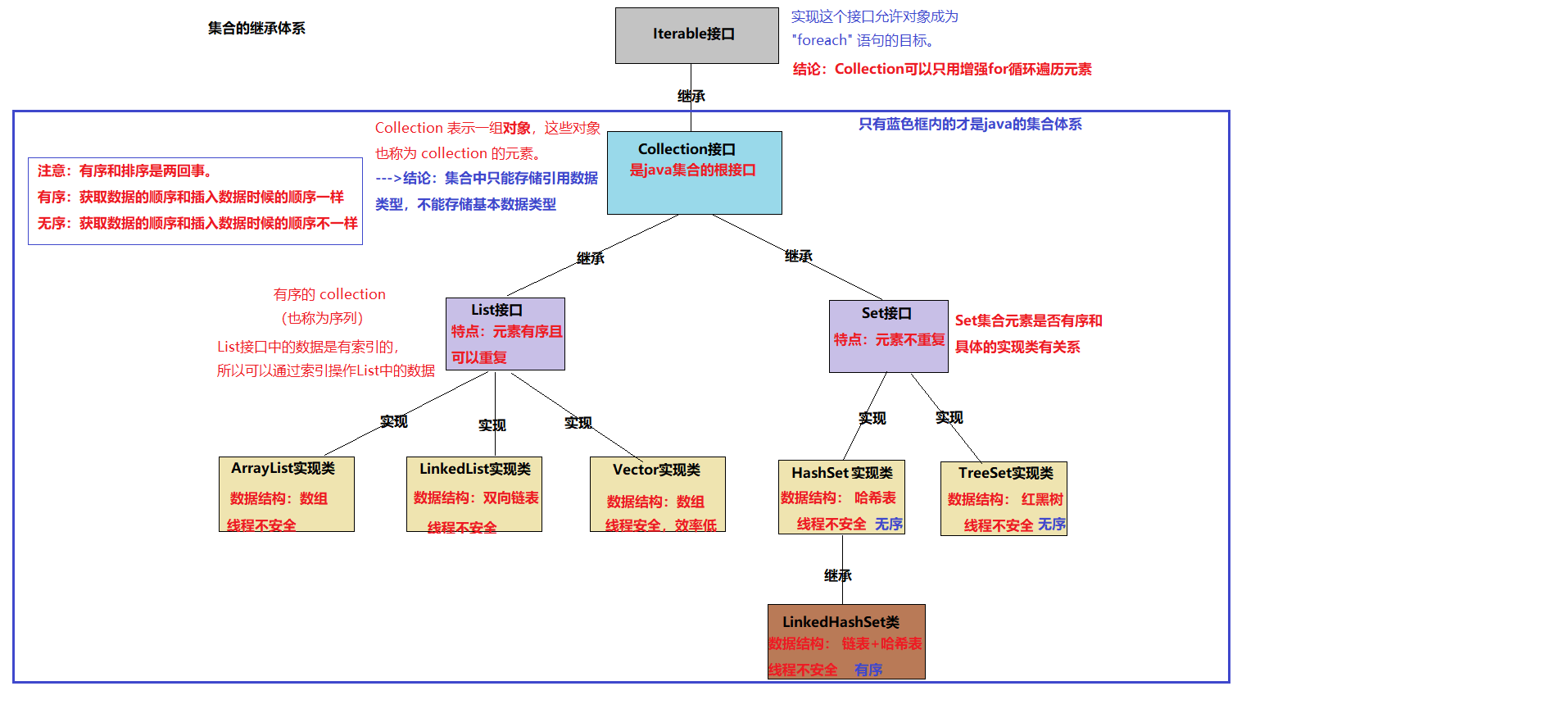
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.List;
/**
* 集合的引入:
*
* 电商案例:
* 我们现在在jd上购买了一些商品,这些商品数据需要在后台程序中存储。我们应该怎么存储?
* 存储多个数据需要使用容器对象,目前我们学过的容器对象是 数组。
* 那么以上的案例中使用数组存储有没有什么不好的地方呢?
* 不是很好,数组使用前必须设置长度,长度一旦设置后就固定不能改变了,但是在电商案例中我们是不知道
* 用户的到底会购买多少商品的,也就是数组的长度无法确定,怎么办??
* 我们需要先初始一个数组的长度,然后长度不够后再进行扩容。但是数组扩容比较麻烦,需要重新创建一个新数组,
* 然后将旧数组的值赋值到新数组,最后往新数组中添加新的数据。
*
* java是面向对象的语言:
* 面向对象: 就是不停的创建对象,使用对象完成功能
*
* 所以面对以上出现的问题时候,我们要看看有没有现成的对象可以帮助我们完成数据存储和自动扩容的功能,如果有就直接使用;
* 没有才直接创建。
*
* 当然java已经好了这样的类: 集合
*
* java中的集合在java.util包中
*
*
* Collection接口:
* 学习集合,掌握增删查改的方法 + 其它方法
*
* 方法摘要
* 增:
* boolean add(Object e)
* 确保此 collection 包含指定的元素(可选操作)。
* boolean addAll(Collection c)
* 将指定 collection 中的所有元素都添加到此 collection 中(可选操作)。
*
* 删:
* void clear()
* 移除此 collection 中的所有元素(可选操作)。
* boolean remove(Object o)
* 从此 collection 中移除指定元素的单个实例,如果存在的话(可选操作)。
* boolean removeAll(Collection<?> c)
* 移除此 collection 中那些也包含在指定 collection 中的所有元素(可选操作)。
*
*
* 查:
* boolean contains(Object o)
* 如果此 collection 包含指定的元素,则返回 true。
* boolean containsAll(Collection<?> c)
* 如果此 collection 包含指定 collection 中的所有元素,则返回 true。
* Iterator<E> iterator()
* 返回在此 collection 的元素上进行迭代的迭代器。
*
* 其它方法:
* boolean isEmpty()
* 如果此 collection 不包含元素,则返回 true。
* boolean retainAll(Collection<?> c)
* 仅保留此 collection 中那些也包含在指定 collection 的元素(可选操作)。
* int size()
* 返回此 collection 中的元素数。
* Object[] toArray()
* 返回包含此 collection 中所有元素的数组。
*
* Arrays类:
* static <T> List<T> asList(T... a)
* 返回一个受指定数组支持的固定大小的列表。
* 该方法得到的集合不能做元素的增加和删除
*
*/
public class Demo01 {
public static void main(String[] args) {
// test01();
// test02();
// test03();
test04();
}
private static void test04() {
Collection collection = new ArrayList();
collection.add(1);
collection.add(2);
collection.add("a");
collection.add("b");
// collection.clear();
/*
* boolean isEmpty(): 判断集合是否为空(没有任何元素)
*/
System.out.println(collection.isEmpty());
/*
* boolean retainAll(Collection<?> c): 求两个集合的交集,将交集的结果存储在此collection
*
* 返回值:
* 此collection元素发生变化就是true; 否则就是false
*/
Collection collection1 = new ArrayList();
collection1.add(11);
collection1.add(21);
collection1.add("b1");
collection1.add("c1");
System.out.println("求交集前collection:" + collection);
System.out.println("求交集前collection1:" + collection1);
boolean b = collection.retainAll(collection1);
System.out.println(b);
System.out.println("求交集后collection:" + collection);
System.out.println("求交集后collection1:" + collection1);
/*
* int size(): 返回此 collection 中的元素数
*/
System.out.println(collection.size());
System.out.println(collection1.size());
System.out.println("-----------toArray----------------");
/*
* Object[] toArray()
* 返回包含此 collection 中所有元素的数组。
*/
Object[] objects = collection1.toArray();
System.out.println(Arrays.toString(objects));
System.out.println("-----------Arrays类的asList----------------");
/*
* Arrays.asList 得到的集合不能做元素的增加和删除
*/
List ints = Arrays.asList(1,2,3,4,5);
System.out.println(ints);
// java.lang.UnsupportedOperationException
// ints.add(100);
// ints.remove(2);
System.out.println(ints.contains(2));
System.out.println(ints);
}
// 查
private static void test03() {
/*
* contains(Object o): 查询指定元素是否在集合中
*
* 如何判断元素是否存在,contains底层也是调用对象的eqauls()方法判断内容
*/
Collection collection = new ArrayList();
collection.add(1);
collection.add(2);
collection.add("a");
collection.add("b");
collection.add(new Student("张三"));
System.out.println(collection.contains("a"));
System.out.println(collection.contains(new Student("张三")));
/*
* containsAll(Collection<?> c)
* 如果此 collection 包含指定 collection 中的所有元素,则返回 true。
*
* containsAll底层的实现逻辑:
* 1. 遍历参数的元素
* 2. 调用contains()
*/
Collection collection1 = new ArrayList();
collection1.add(1);
collection1.add(2);
collection1.add("a");
System.out.println(collection.containsAll(collection1));
}
// 删
private static void test02() {
Collection collection = new ArrayList();
collection.add(1);
collection.add(2);
collection.add(2);
collection.add(2);
collection.add("a");
collection.add("b");
collection.add(new Student("张三"));
/*
* remove(Object o)
* 从此 collection 中移除指定元素的单个实例,如果存在的话
* 也就说如果存在多个相同的元素,只能删除一个
*
* 集合中存储的是对象,删除元素的时候是如何判断元素相同的?
* 使用equals()判断,所以自定义的对象作为元素,建议覆写equals()
* 对象的判断有两种方式:
* 1. == 比较的是地址值
* 2. equals() 默认比较是地址值,但是可以覆写方法变成比较内容
*/
System.out.println("删除前:" + collection);
// collection.remove(2);
// collection.remove(new Integer(2));
collection.remove(new Student("张三"));
System.out.println("删除后:" + collection);
System.out.println("-----------removeAll-------------");
/*
* removeAll(Collection c)
* 移除此 collection 中那些也包含在指定 collection 中的所有元素。
*
* 注意: remove(Object e) 删除指定元素,只会删除一个
* removeAll(Collection c) 删除集合中包含在参数集合中的所有元素。这里删除的匹配的所有元素。
*
*/
Collection collection1 = new ArrayList();
collection1.add(1);
collection1.add(2);
collection1.add(200);
System.out.println("删除前:" + collection);
collection.removeAll(collection1);
System.out.println("删除后:" + collection);
System.out.println("-----------clear---------------");
/*
* clear(): 移除此 collection 中的所有元素
*/
System.out.println("清空前:" + collection);
collection.clear();
System.out.println("清空后:" + collection);
}
// 增
private static void test01() {
// 创建对象
/*
* 现在代码有警告,也就是代码使用不规范,这是因为没有指定泛型
* 暂时不用管这个警告
*/
Collection collection = new ArrayList();
// 让对象干活
// 增加数据 -- 往集合中添加数据
/*
* 1. 集合中不能添加基本数据类型,这里的10已经发生自动装箱了
* 2. add(Object e) 是将元素添加到集合的尾部
*/
collection.add(10);
collection.add("java");
System.out.println(collection);
/*
* addAll(Collection c)
* 将指定 collection 中的所有元素都添加到此collection 中
*/
Collection collection01 = new ArrayList();
collection01.add(200);
collection01.add(300);
// 将collection01中的所有元素添加到collection中
// collection.addAll(collection01); // [10, java, 200, 300]
// 以下的代码是将collection01整体作为一个元素添加到collection
collection.add(collection01);
System.out.println(collection);// [10, java,[200, 300]]
}
}
Student类
import java.util.Objects;
public class Student {
private String name;
public Student() {
}
public Student(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return Objects.equals(name, student.name);
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
'}';
}
}
iterator迭代器接口
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
* Iterator<E> iterator()
* 返回在此 collection 的元素上进行迭代的迭代器。
*
* Iterator迭代器接口:
* 对 collection 进行迭代的迭代器。
*
* 方法摘要
* boolean hasNext()
* 如果仍有元素可以迭代,则返回 true。
* E next()
* 返回迭代的下一个元素。
* void remove()
* 从迭代器指向的 collection 中移除迭代器返回的最后一个元素(可选操作)。
*/
public class Demo02 {
public static void main(String[] args) {
Collection collection = new ArrayList();
collection.add(1);
collection.add(2);
collection.add(3);
collection.add(4);
// 获取集合的迭代器
/*
* 以下的代码是多态
* 左边是Iterator接口的引用
* 右边一定是Iterator接口的实现类对象
* 说明集合子类的iterator() 实现了Iterator接口,并实现了Iterator接口的方法
*/
Iterator iterator = collection.iterator();
while(iterator.hasNext()){
Object obj = iterator.next();
System.out.println(obj);
iterator.remove(); // 迭代器删除元素
}
System.out.println(collection);
System.out.println("------------------foreach----------------------");
/*
* 集合中的foreach底层代码还是迭代器
*
* foreach是java的一种语法糖,简化了迭代器的代码
*/
Collection collection1 = new ArrayList();
collection1.add(1);
collection1.add(2);
collection1.add(3);
collection1.add(4);
for (Object o : collection1) {
System.out.println(o);
}
}
}
使用迭代器的好处:

list接口
import java.util.ArrayList;
import java.util.List;
/**
* List接口
* List接口继承Collection接口,所以Collection接口的方法List接口都有
*
* 所以我们要学习List接口特有的方法。
*
* List集合的特点:
* 1、元素可以重复
* 2、元素有序
* 3、可以使用索引操作元素
*
* 方法摘要
*
* 增:
* void add(int index, E element)
* 在列表的指定位置插入指定元素(可选操作)。
* boolean addAll(int index, Collection<? extends E> c)
* 将指定 collection 中的所有元素都插入到列表中的指定位置(可选操作)。
*
* 查:
* E get(int index)
* 返回列表中指定位置的元素。
* int indexOf(Object o)
* 返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1。
* int lastIndexOf(Object o)
* 返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1。
* ListIterator<E> listIterator()
* 返回此列表元素的列表迭代器(按适当顺序)。
* ListIterator<E> listIterator(int index)
* 返回列表中元素的列表迭代器(按适当顺序),从列表的指定位置开始。
*
* 删:
* E remove(int index)
* 移除列表中指定位置的元素(可选操作)。
* boolean remove(Object o)
* 从此列表中移除第一次出现的指定元素(如果存在)(可选操作)。
* 改:
* E set(int index, E element)
* 用指定元素替换列表中指定位置的元素(可选操作)。
*
* 其它方法:
* List<E> subList(int fromIndex, int toIndex)
* 返回列表中指定的 fromIndex(包括 )和 toIndex(不包括)之间的部分视图。
*/
public class ListDemo01 {
public static void main(String[] args) {
// test01();
// test02();
// test03();
// test04();
test05();
}
// 其它方法
private static void test05() {
List list = new ArrayList();
list.add(200);
list.add(88);
list.add(199);
list.add(100);
/*
* List<E> subList(int fromIndex, int toIndex)
* 返回列表中指定的 fromIndex(包括 )和 toIndex(不包括)之间的部分视图。
*/
List list1 = list.subList(1, 3);
System.out.println(list1); // [88,199]
}
// 改
private static void test04() {
List list = new ArrayList();
list.add(200);
list.add(88);
list.add(199);
list.add(100);
/*
* Object set(int index, E element)
* 用指定元素替换列表中指定位置的元素。
* 返回旧元素(被替换的元素)
*/
System.out.println("修改前:" + list);
Object obj = list.set(2, 999);
System.out.println("被替换的元素:" + obj);
System.out.println("修改后:" + list);
/*
* 下来完成: List元素冒泡排序
*/
}
// 删
private static void test03() {
List list = new ArrayList();
list.add(2);
list.add(88);
list.add(99);
list.add(100);
list.add(99);
// 删除指定索引位置的元素,返回被删除的元素
System.out.println("删除前:" + list);
Object obj = list.remove(2);
System.out.println("被删除的元素:" + obj);
System.out.println("删除后:" + list);
System.out.println("----------------------------");
System.out.println("删除前:" + list);
// 删除元素2
boolean b = list.remove(new Integer(2));
System.out.println(b);
System.out.println("删除后:" + list);
}
// 查
private static void test02() {
List list = new ArrayList();
list.add(88);
list.add(99);
list.add(100);
list.add(99);
/*
* Object get(int index) 返回列表中指定位置的元素。
* 要求: index < size 否则抛出IndexOutOfBoundsException
*/
System.out.println(list.get(0));
System.out.println("---------------------");
// 使用普通for循环遍历list
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
System.out.println("---------------indexOf-----------------");
/*
* int indexOf(Object o)
* 返回此列表中第一次出现的指定元素的索引;如果元素不存在,则返回 -1。
* int lastIndexOf(Object o)
* 返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1。
*/
System.out.println(list.indexOf(1000)); // -1
System.out.println(list.indexOf(99)); // 1
System.out.println(list.lastIndexOf(99)); // 3
}
// 增
private static void test01() {
List list = new ArrayList();
list.add(88);
list.add(99);
/*
* add(int index, E element): 在指定索引位置添加元素
* 要求:index <= size 否则抛出IndexOutOfBoundsException
*/
list.add(0,100);
System.out.println(list); // [100,88,99]
List list1 = new ArrayList();
list1.add(3);
list1.add(5);
list.addAll(1,list1);
System.out.println(list); // [100,3,5,88,99]
}
}
List元素冒泡排序
listIterator迭代器接口
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;
/**
* ListIterator<E> listIterator()
* 返回此列表元素的列表迭代器(按适当顺序)。
* ListIterator<E> listIterator(int index)
* 返回列表中元素的列表迭代器(按适当顺序),从列表的指定位置开始。
*
* ListIterator接口:
* public interface ListIterator<E> extends Iterator<E>
* 列表迭代器,允许程序员按任一方向遍历列表、迭代期间修改列表,并获得迭代器在列表中的当前位置。
*
* 方法摘要:
* void add(E e)
* 将指定的元素插入列表(可选操作)。
* boolean hasNext()
* 以正向遍历列表时,如果列表迭代器有多个元素,则返回 true(换句话说,如果 next 返回一个元素而不是抛出异常,则返回 true)。
* boolean hasPrevious()
* 如果以逆向遍历列表,列表迭代器有多个元素,则返回 true。
* E next()
* 返回列表中的下一个元素。
* E previous()
* 返回列表中的前一个元素。
* void remove()
* 从列表中移除由 next 或 previous 返回的最后一个元素(可选操作)。
*/
public class ListDemo02 {
public static void main(String[] args) {
// test01();
test02();
}
private static void test02() {
List list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
ListIterator it = list.listIterator(list.size());
while(it.hasPrevious()){
Object obj = it.previous();
System.out.println(obj);
}
}
private static void test01() {
List list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
ListIterator it = list.listIterator();
while(it.hasNext()){
Object obj = it.next();
if(obj.equals(3)){
// it.add(99);
it.remove();
}
}
System.out.println(list);
}
}
研究迭代器的注意细节【ConcurrentModificationException 并发修改异常】
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;
/**
* 研究迭代器的注意细节:
*
*/
public class IteratorDemo {
public static void main(String[] args) {
// test01();
test02();
}
private static void test02() {
List list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
ListIterator it = list.listIterator();
for (int i = 0; i < list.size(); i++) {
Object obj = list.get(i);
if(obj.equals(3)){
//此时迭代器指向的是第一个元素
it.add(99); //被添加到迭代器之前(离头近的地方) 即用next()是访问不到的,要用previous才能访问的到
//输出结果:[99,1,2,3,4,5]
break;
}
}
System.out.println(list);
}
private static void test01() {
List list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
ListIterator it = list.listIterator();
while(it.hasNext()){
/*
* java.util.ConcurrentModificationException 并发修改异常
* 这个异常大家需要记住异常原因。但是重点是你们要看懂我是如何去查找异常原因的。
* 出现该异常的原因:
* 【next()方法】会调用checkCoModifaction()方法检测modCount和expectedModCount的值是否一样,
* 如果值不一样就会抛出ConcurrentModificationException 并发修改异常。
*
* 集合中元素添加和删除modCount的值都会++,但是expectedModCount只会在创建迭代器的时间初始化一次,值为modCount的值;
* 以下的代码在迭代的过程中使用集合添加了元素,modCount的变化了;但是expectedModCount还是原来的值,所以两个值不相等,抛出异常
*
* 所以:
* 使用迭代器遍历元素的时候,不能使用集合添加和删除元素;但是可以使用迭代器添加和删除元素
* 使用foreach遍历元素的时候,不能使用集合添加和删除元素。[因为foreach也是迭代器]
*/
Object obj = it.next();
if(obj.equals(3)){
// list.add(99);
it.add(99);
}
}
System.out.println(list);
}
}

Arraylist接口
import java.util.ArrayList;
import java.util.Arrays;
/**
* 数据接口: 就是数据存储的方式
*
* ArrayList类特点:
* 1. List接口的实现类
* 2. 底层的数据结构是:动态数组
* 数组的特点:
* a. 数组在内存是一段地址连续的空间
* b. 长度固定,改变长度需要新建数组
* 3. 增加和删除数据效率低,查询和修改的效率高
* 4. 线程不安全,安全性低,效率高
*
*
* 构造方法摘要
* ArrayList()
* 构造一个初始容量为 10 的空列表。
* ArrayList(Collection c)
* 构造一个包含指定 collection 的元素的列表,这些元素是按照该 collection 的迭代器返回它们的顺序排列的。
* 可以将其它集合转成List
* ArrayList(int initialCapacity)
* 构造一个具有指定初始容量的空列表。
*
*
* ArrayList类没有独有的方法需要掌握,都是使用List和Collection中的方法。
*
* ArrayList的扩容机制:
* int newCapacity = oldCapacity + (oldCapacity >> 1);
* 新容量 = 旧容量的1.5倍
*
* 以上扩容机制的弊端:
* 每次扩容的是旧容量的1.5倍,可能会造成空间的浪费
* 比如:
* 旧容量=10,存储11个元素,扩容=15,有4个浪费
*
*
* ArrayList也不能无限扩容,最大容量= Integer.MAX_VALUE - 8
*
*/
public class ArrayListDemo {
public static void main(String[] args) {
// 构造一个初始容量为 10 的空列表。
// 也就是ArrayList底层数组的长度是10
ArrayList list = new ArrayList();
/*
* size()是集合中元素的个数;不是底层数组的长度
*/
System.out.println(list.size());
// 当元素个数超过底层数组的长度,此时ArrayList会自动扩容
for (int i = 0; i < 10; i++) {
list.add(i);
}
list.add(100);
System.out.println(list);
System.out.println(list.size());
}
}
DAY20
LinkedList类
import java.util.Iterator;
import java.util.LinkedList;
/**
*
* LinkedList类:
* 1. List接口的实现类;同时还实现了Deque(双端队列)接口
* 2. 底层数据结构是: 双向链表
* 3. 增加和删除效率高,查询和修改效率低
* 4. 线程不安全,安全性低,效率高
*
* 注意: LinkedList集合需要扩容么? 不需要扩容
*
* 之前在ArrayList中讲过,ArrayList的弊端,可能会浪费空间。
* 就是增加的元素只比旧容量多几个数据,此时就会浪费空间,这种情况下怎么处理呢?
* 1. 如果可以事先预估元素的多少,那么可以使用 new ArrayList(自定义的容量)
* 2. 如果不能预估元素的多少,可以使用LinkedList来解决空间浪费
*
* 今天我们只需要掌握 List接口和Collection接口中的方法
*
*/
public class LinkedListDemo {
public static void main(String[] args) {
LinkedList list = new LinkedList();
list.add(1);
list.add(2);
list.add(3);
System.out.println(list);
System.out.println("---------foreach-------");
// 遍历list -- foreach
for (Object o : list) {
System.out.println(o);
}
System.out.println("---------迭代器-------");
// 遍历list -- 迭代器
Iterator it = list.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
System.out.println("---------使用索引-------");
// 遍历list -- 迭代器
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
}
数据结构之链表
- 链表是由节点链接而成的
- 链表在内存中不是一段连续的内存空间,添加一个节点就在内存中新开一个空间存储Node节点
Vector类
import java.util.Vector;
/**
* Vector类:
* 向量类
* 1. List接口的实现类
* 2. 底层数据结构:动态数组
* 3. 增加和删除效率低;查询和修改效率高
* 4. 线程安全的,安全性高,效率低
* 在开发中需要线程安全的集合时,我们基本上也不会使用Vector,而是使用其它方式将集合变成线程安全的。
* 目前在开发中Vector用的越来越少了,就是因为其效率不高。
*
* 构造方法摘要
* Vector()
* 构造一个空向量,使其内部数据数组的大小为 10,其标准容量增量为零。
* Vector(Collection c)
* 构造一个包含指定 collection 中的元素的向量,这些元素按其 collection 的迭代器返回元素的顺序排列。
* Vector(int initialCapacity)
* 使用指定的初始容量和等于零的容量增量构造一个空向量。
* Vector(int initialCapacity, int capacityIncrement)
* 使用指定的初始容量和容量增量构造一个空的向量。
*
* capacityIncrement就是容量的增量
*
* Vector的扩容机制:
* int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity);
* 1. 如果容量的增量capacityIncrement不大于0,新容量 = oldCapacity的2倍
* 2. 如果容量的增量capacityIncrement>0 ,新容量 = oldCapacity + capacityIncrement
*
*
* 也不能无限制的扩容,最大限制是Integer.MAX_VALUE - 8
*/
public class VectorDemo {
public static void main(String[] args) {
// 构造一个空向量,使其内部数据数组的大小为 10,其标准容量增量为零。
Vector vector = new Vector();
for (int i = 0; i < 10; i++) {
vector.add(i);
}
vector.add(100);
System.out.println(vector);
}
}
泛型——genericity
- 注意: 只有引用数据类型才能作为泛型。
- 泛型的作用:约束集合中元素的数据类型,将元素类型的检测从运行时提升到编译时。
- 当成添加的元素不满足泛型约束的类型,代码编译报错。
import java.util.ArrayList;
/**
* 泛型(genericity):
* 泛型: 又叫参数化类型,就是将引用数据类型作为参数了。所以泛型也有形参和实参。
* 泛型的形参:仅仅表示这是一个泛型,没有具体的数据类型
* 可以用任意的标识符表示,一般使用T E K V
* 泛型的实参:就是一种具体的引用数据类型,作用是给泛型的形参赋值
*
*
* 泛型的语法格式:<泛型形参>
* 泛型类:class 类名<泛型>{}
*
*/
public class Demo01 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("java");
list.add("hello");
list.add(100);
list.add(true);
// 将集合中的元素转成大写
for (Object o : list) {
/*
* 泛型的引入:
*
* 因为集合中元素的类型是Object类型,所以将Object转成String
* 但是集合中元素除了String外,还有其它的数据类型,所以此时代码在
* 运行的时候抛出类转换异常:ClassCastException
* 这样就降低了代码的健壮性。
*
* 因为ClassCastException是运行时异常,也就是说我们的代码要运行起来之后,我们才能发现问题。
* 那么为了提高代码的健壮性,我们能不能将问题在代码编译的时候就暴露出来,编译时出现问题,代码是
* 编译不通过,我们立马就可以发现问题,这样就不用等到代码写完了都开始运行了才出现问题。
*
*
* 所以java提供了泛型机制,泛型就可以约束元素的数据类型了。
*
*/
String str = (String) o;
String upperCase = str.toUpperCase();
System.out.println(upperCase);
}
}
}
子类继承泛型类
可以指定泛型父类中泛型的具体类型 – 不推荐
public class MyArryList extends MyList<Integer>这种方式有弊端:子类的元素类型固定死了,不灵活。
子类也是泛型类 – 推荐
public class MyArryList<E> extends MyList<E>泛型类中的泛型什么时候有具体的数据类型?也就是这个泛型形参什么时候有泛型实参?
创建该类对象的时候;
public class MyListDemo { public static void main(String[] args) { /* * 这里就是创建MyList泛型类的对象,所以此时可以指定泛型的实参 * MyList<Integer> 中的Integer就是一种具体的数据类型,是泛型的实参 * 所以此时MyList中元素就只能是Integer类型了 */ MyList<Integer> list = new MyList<>(); // 钻石语法 list.add(100); // 添加String类型的元素,代码编译就会报错 // list.add("java"); } }子类继承泛型类的时候 – 但是不推荐
public class MyArryList extends MyList<Integer> //这种方法有弊端:就是子类的元素类型固定死了,不灵活语法:
//泛型类:class 类名<泛型形参>{} public class MyList<E> { E e; public void add(E e){ System.out.println("e=== " + e); } } /* MyList<E> 这里的E就是泛型的形参 就意味着MyList中可以是任意的引用数据类型 */
泛型接口
- 注意: interface CustomList
这里的String只是一个泛型形参的名字,和T,E是一样,不是String类。
泛型接口中的泛型形参什么时候有具体的数据类型?
实现类实现泛型接口的时候,可以写泛型实参 – 不推荐
public class MyCustomList implements CustomList<Integer> //弊端: 实现类中元素的类型固定死了,不灵活实现类是泛型类,创建实现类对象的时候指定具体的数据类型
public class MyCustomList<E> implements CustomList<E> MyCustomList<String> list = new MyCustomList<>();
/**
* 泛型接口:
* interface 接口名<泛型形参>
*/
public interface CustomList<E> {
void add (E e);
}
eg:
public class MyCustomListDemo { public static void main(String[] args) { MyCustomList<String> list = new MyCustomList<>(); list.add("hava"); // 匿名内部类 new CustomList<Integer>(){ @Override public void add(Integer integer) { } }; } }
泛型方法
泛型方法:就是方法的定义上一定有 <泛型的形参> 的方法才是泛型方法。
泛型在定义的时候都是形参,给泛型赋值的时候就是实参。
泛型方法的语法格式:
修饰符 <泛型> 返回值类型 方法名(参数列表){}泛型方法中泛型什么时候有具体的数据类型?
- 调用方法的时候通过实参的数据类型来决定具体的数据类型
注意:静态方法使用泛型,那么该方法必须是泛型方法。
eg:
public class Demo01<E> {
public static void main(String[] args) {
Demo01<Integer> demo01 = new Demo01<>();
// 这里传入String,所以泛型方法中的T就是String
demo01.add("java");
// 这里传入Integer,所以泛型方法中的T就是Integer
demo01.add(100);
/*
* div中的泛型受方法中泛型的约束,和泛型类中的泛型无关
*/
demo01.div("java");
demo01.multi(100);
}
public <T> void add(T t){
System.out.println("t== " + t);
}
/**
* 泛型方法中的泛型名称和泛型类或泛型接口中的泛型名称同名,使用就近原则
* 也就是泛型泛型方法中用的是方法中定义的泛型
*/
public <E> void div(E e){
System.out.println("div---e== " +e);
}
/**
* 这不是泛型方法,所以E就是泛型类中的泛型
*/
public void multi(E e){
System.out.println("multi---e== " +e);
}
/**
* 静态方法使用泛型,那么该方法必须是泛型方法
*/
public static <E> void method(E e){
System.out.println("e= "+ e);
}
}
泛型通配符
泛型通配符 ?
- <?> 这里的?就是泛型通配符
泛型通配符?:表示所有的泛型实参,就是说?可以表示泛型所有的具体类型
这里的E表示的是泛型的形参 泛型通配符主要配合泛型的限定来使用
注意: 如果创建泛型类对象的时候,泛型的实参使用的是?,那么只能调用没有使用泛型类中泛型的方法
eg:
public class Demo01 { public static void main(String[] args) { // 这里的?表示所有的实参,不是具体的某一个,而是全部 MySet<?> set = new MySet<>(); set.show(); /* * capture of ? 类型捕获,因为?不是具体的某一个,而是全部的具体类型 * 所以使用add(E e )的时候 e的类型是无法捕获的,所以不能传入具体的值。 * 所以此时add方法无法调用 * 注意: 如果创建泛型类对象的时候,泛型的实参使用的是?,那么只能调用没有使用泛型类中泛型的方法 */ // set.add(100); } } class MySet<E> { public void show(){ System.out.println("hello,java"); } public void add(E e){ System.out.println("e== " + e); } }
泛型的限定:
上限: <? extends T> 表示?只能是T类及其子类 下限: <? super T> 表示?只能是T类及其父类泛型限定的演示:
import java.util.ArrayList; import java.util.List; class Fu{ } class Zi extends Fu{ } /** * 演示泛型的限定: * * 泛型的限定: * 上限: * <? extends T> 表示?只能是T类及其子类 * 下限: * <? super T> 表示?只能是T类及其父类 */ public class Demo02 { public static void main(String[] args) { Demo02 demo02 = new Demo02(); List<String> list = new ArrayList<>(); list.add("a"); list.add("b"); demo02.method01(list); List<Integer> list01 = new ArrayList<>(); list01.add(100); list01.add(200); demo02.method02(list); demo02.method02(list01); List<Fu> list02 = new ArrayList<>(); list02.add(new Fu()); List<Zi> list03 = new ArrayList<>(); list03.add(new Zi()); List<Object> list04 = new ArrayList<>(); list04.add(new Object()); // 上限 // demo02.method03(list); // error demo02.method03(list02); demo02.method03(list03); // demo02.method03(list04);// error // 下限 // demo02.method04(list);// error demo02.method04(list02); // demo02.method04(list03);// error demo02.method04(list04); } public void method01(List<String> list){ for (String s : list) { System.out.println(s); } } public void method02(List<?> list){ for (Object s : list) { System.out.println(s); } } /** * 上限 * list参数只能接受元素类型是Fu及其子类的 */ public void method03(List<? extends Fu> list){ for (Fu s : list) { System.out.println(s); } } /** * 下限 * list参数只能接受元素类型是Fu及其父类的 */ public void method04(List<? super Fu> list){ for (Object s : list) { System.out.println(s); } } }
泛型擦除——Generic erasure
源代码中使用的泛型,在经过编译后,代码中就看不到泛型,也就是所谓的泛型擦除
泛型擦除不是泛型丢失了,而是在编译后的字节码文件中使用单独的标识来存储泛型了。
java代码编译前会代码进行校验,代码能够通过校验说明,代码语法是没有问题的,所以编译的时候可以擦除泛型。
eg:
ArrayList<String> list = new ArrayList<>(); list.add("java"); list.add("hello"); 以上代码可以校验通过,说明集合中的元素一定是符合泛型的类型的,所以此时编译擦除泛型不受影响 ArrayList list = new ArrayList(); list.add("java"); list.add("hello");
eg:
import java.util.ArrayList;
/**
* 泛型擦除(Generic erasure):
*
* 为什么会出现泛型擦除,主要是为了编译器的兼容性。
* 在jdk5之前是没有泛型的,jdk5之后出现了泛型,为了编译器的兼容性,在编译代码的时候就
* 将泛型擦除了,这样就和之前没有泛型的时候编译一样了。
*
*/
public class Demo01 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("java");
list.add("hello");
System.out.println(list);
}
}
自定义的ArrayList
import java.util.Arrays;
/**
* 自定义的ArrayList
* - 底层使用数组
*/
public class ArrayList<E> implements List<E> {
/**
* ArrayList底层的数据结构,用来存储元素
*/
private Object[] elements;
/**
* 用来保存元素的数量
*/
private int size;
// 默认的数组容量
private final int DEFAUALT_CAPACITY = 10;
public ArrayList() {
elements = new Object[DEFAUALT_CAPACITY];
}
/**
* 指定数组的初始容量
*/
public ArrayList(int initCapacity) {
elements = new Object[initCapacity];
}
@Override
public boolean add(E e) {
/**
* size是数组中已经存在的数据
* 所以我们只需要判断下一个元素的空间是否足够即可
*/
ensureCapacity(size + 1);
/**
* size是从0开始的,数组的索引也是从0开始的
* 所以往集合的末尾添加数据就可以使用size作为索引
*/
elements[size++] = e;
return true;
}
@Override
public void add(int index, E element) {
checkIndexRangeForAdd(index);
/**
* 添加数据到指定位置,数组中原有的数据需要移动位置,那么数据需要移动呢?
* 从索引index到size -1 的数据都需要往后移动
*
* 移动数据应该从最后一个开始移动,所以循环条件如下
*/
for (int i = size - 1; i >= index; i--) {
elements[i + 1] = elements[i];
}
elements[index] = element;
size++;
}
@Override
public void clear() {
/**
* 以下的循环是为了GC
*/
for (int i = 0; i < size; i++) {
elements[i] = null;
}
/**
* 只需要size=0, 集合中的元素就获取不到了
*/
size = 0;
}
@Override
public boolean contains(Object o) {
return indexOf(o) != -1;
}
@Override
public E get(int index) {
checkIndexRange(index);
return (E) elements[index];
}
@Override
public int indexOf(Object o) {
if(o == null){
for (int i = 0; i < size; i++) {
if (elements[i] == null) {
return i;
}
}
}else{
for (int i = 0; i < size; i++) {
if (o.equals(elements[i])) {
return i;
}
}
}
return -1;
}
@Override
public boolean isEmpty() {
return size == 0;
}
@Override
public E remove(int index) {
checkIndexRange(index);
E old = (E) elements[index];
/**
* 删除指定位置的元素,就是将指定位置后面的元素向前移动一位,就可以
* 就需要删除的元素覆盖
*/
for (int i = index + 1; i <= size - 1; i++) {
elements[i - 1] = elements[i];
}
elements[--size] = null;
return old;
}
/**
* 大家下来后自己完成
*/
@Override
public boolean remove(Object o) {
return false;
}
@Override
public E set(int index, E element) {
checkIndexRange(index);
E old = (E) elements[index];
elements[index] = element;
return old;
}
@Override
public int size() {
return size;
}
/**
* 扩容方法
* @param minCapacity 需要的最小容量
*/
public void ensureCapacity(int minCapacity){
int oldCapacity = elements.length;
/**
* 当需要的最小容量大于旧容量时,就需要扩容
*/
if(minCapacity > oldCapacity){
// 新容量
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 创建新数组
Object[] newElements = new Object[newCapacity];
// 将旧数组中的值复制到新数组中
for (int i = 0; i < elements.length; i++) {
newElements[i] = elements[i];
}
/*
* 我们新建的数组,但是在ArrayList中操作的数组是成员变量elements
* 这个数组,所以需要将新数组赋值给elements
*/
elements = newElements;
}
}
/**
* 检查索引的范围
* @param index 索引
*/
private void checkIndexRange(int index){
if(index < 0 || index >= size){
throw new IndexOutOfBoundsException("index:"+ index+",size:"+ size);
}
}
/**
* 检查add方法索引的范围
* @param index 索引
*/
private void checkIndexRangeForAdd(int index){
if(index < 0 || index > size){
throw new IndexOutOfBoundsException("index:"+ index+",size:"+ size);
}
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append("[");
/**
* 遍历数组的元素时,只获取存入的元素,所以范围是size
*/
for (int i = 0; i < size; i++) {
if (i == 0) {
sb.append(elements[i]);
} else {
sb.append("," + elements[i]);
}
}
sb.append("]");
return sb.toString();
}
}
eg:
public class ArrayListDemo { public static void main(String[] args) { ArrayList<Integer> list = new ArrayList<>(); list.add(10); list.add(8); list.add(2); list.add(33); list.add(null); // list.add(5,100); int i = list.indexOf(null); System.out.println(i); System.out.println(list); // [10,8,100,2,33] } }
自定义的LinkedList
/**
* 自定义LinkedList
* - 底层是双向链表
*
* 注意: 编写链表的实现一定要主要边界的检查
*/
public class LinkedList<E> implements List<E>{
// 元素的个数
private int size;
// 头节点
private Node<E> first;
// 尾节点
private Node<E> last;
public LinkedList() {
}
@Override
public boolean add(E e) {
add(size,e);
return true;
}
@Override
public void add(int index, E element) {
checkIndexRangeForAdd(index);
// 往末尾添加
if(index == size){
// 获取原来末尾的旧节点
Node<E> oldLast = last;
// 创建添加元素的节点
Node<E> node = new Node<>(element,oldLast,null);
if(oldLast == null){ // index = size = 0
first = last = node;
}else{
oldLast.next = node;
}
last = node;
}else{
// 查找到index索引处原来的节点
Node<E> oldNode = node(index);
Node<E> prev = oldNode.prev;
// 创建添加元素的节点
Node<E> node = new Node<>(element,prev,oldNode);
if(prev == null){
first = node;
}else{
prev.next = node;
}
oldNode.prev = node;
}
size++;
}
@Override
public void clear() {
first = last = null;
size = 0;
}
@Override
public boolean contains(Object o) {
return indexOf(o) != -1;
}
@Override
public E get(int index) {
checkIndexRange(index);
return node(index).element;
}
@Override
public int indexOf(Object o) {
if(o == null){
for (int i = 0; i < size; i++) {
Node<E> node = node(i);
if(node.element == null){
return i;
}
}
}else{
for (int i = 0; i < size; i++) {
Node<E> node = node(i);
if(o.equals(node.element)){
return i;
}
}
}
return -1;
}
@Override
public boolean isEmpty() {
return size == 0;
}
// 自己下来完成
@Override
public E remove(int index) {
return null;
}
@Override
public boolean remove(Object o) {
return false;
}
@Override
public E set(int index, E element) {
checkIndexRange(index);
Node<E> node = node(index);
E old = node.element;
node.element = element;
return old;
}
@Override
public int size() {
return size;
}
/**
* 检查索引的范围
* @param index 索引
*/
private void checkIndexRange(int index){
if(index < 0 || index >= size){
throw new IndexOutOfBoundsException("index:"+ index+",size:"+ size);
}
}
/**
* 检查add方法索引的范围
* @param index 索引
*/
private void checkIndexRangeForAdd(int index){
if(index < 0 || index > size){
throw new IndexOutOfBoundsException("index:"+ index+",size:"+ size);
}
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append("[");
for (int i = 0; i < size; i++) {
Node<E> node = node(i);
if(i == 0){
sb.append(node.element);
}else{
sb.append(","+ node.element);
}
}
sb.append("]");
return sb.toString();
}
/**
* 查找指定位置的节点
* @param index 指定位置
* @return 返回Node
*/
private Node<E> node(int index){
Node<E> node;
if(index < (size >> 1)){
node = first;
/**
* 循环表示向下查找几次
*/
for (int i = 0; i < index; i++) {
node = node.next;
}
}else{
node = last;
/**
* 循环表示向前查找几次
*/
for (int i = size - 1 ; i > index; i--) {
node = node.prev;
}
}
return node;
}
/**
* 双向链表的节点
* @param <E> 节点中元素的数据类型
*/
private static class Node<E>{
// 节点中的数据
private E element;
// 前一个节点的地址
private Node<E> prev;
// 下一个节点的地址
private Node<E> next;
public Node(E element, Node<E> prev, Node<E> next) {
this.element = element;
this.prev = prev;
this.next = next;
}
}
}
eg:
public class LinkedListDemo { public static void main(String[] args) { LinkedList<Integer> list = new LinkedList<>(); list.add(10); list.add(11); list.add(1,120); System.out.println(list.get(2)); System.out.println(list); } }
自定义的list接口
/**
* 自定义的List接口
*/
public interface List<E> {
/**
* 向列表的尾部添加指定的元素
* @param e 添加的元素
* @return true
*/
boolean add(E e);
/**
* 在列表的指定位置插入指定元素
* @param index 指定位置
* @param element 指定元素
*/
void add(int index, E element);
/**
* 从列表中移除所有元素
*/
void clear();
/**
* 如果列表包含指定的元素,则返回 true。
* @param o 指定的元素
* @return true-包含,false-不包含
*/
boolean contains(Object o);
/**
* 返回列表中指定位置的元素
* @param index 指定位置
* @return 返回的元素
*/
E get(int index);
/**
* 返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1。
* @param o 指定元素
* @return 返回的索引,不存在就是-1
*/
int indexOf(Object o);
/**
* 如果列表不包含元素,则返回 true。
* @return 有元素就是false;没有元素就true
*/
boolean isEmpty();
/**
* 移除列表中指定位置的元素
* @param index 指定位置
* @return 被删除的元素
*/
E remove(int index);
/**
* 从此列表中移除第一次出现的指定元素
* @param o 指定元素
* @return true
*/
boolean remove(Object o);
/**
* 用指定元素替换列表中指定位置的元素
* @param index 指定位置
* @param element 指定元素
* @return 被替换的元素
*/
E set(int index, E element);
/**
* 返回列表中的元素数。
* @return 元素的数量
*/
int size();
}
队列——Queue:先进先出(FIFO)
队列结构可以使用数组或链表来实现
双端队列:deque 是 “double ended queue (双端队列) “ 的缩写。
双端队列中入口也是出口,出口也是入口。
java中LinkedList就是Deque的实现类。
public class Queue {}
栈
特点:后进先出(LIFO),先进后出(FILO)– First In Last Out
栈结构可以使用数组或链表来实现。
eg:
public class Stack<E> { private LinkedList<E> list; public Stack() { list = new LinkedList<>(); } /** * 入栈,在头部添加元素 * */ public void push(E e){ list.add(0,e); } /** * 出栈,返回头部元素,并且从栈中删除 * @return 返回头部元素 */ public E pop(){ return list.remove(0); } /** * peek 瞟一眼,只会查看栈头部元素,不会删除 * @return 返回头部元素 */ public E peek(){ return list.get(0); } }
eg:
package com.powernode.p8; public class StackDemo { public static void main(String[] args) { Stack<Integer> stack = new Stack<>(); stack.push(10); stack.push(20); stack.push(30); stack.push(40); System.out.println(stack.peek()); System.out.println(stack.peek()); System.out.println(stack.peek()); System.out.println(stack.pop()); System.out.println(stack.pop()); System.out.println(stack.pop()); } }
DAY21
Set接口——HashSet类
import java.util.HashSet;
/**
* Set接口
* 是Collection接口的子接口
* 特点: 元素不能重复;元素是否有序和实现类有关
*
* HashSet类:
* HashSet是Set接口的实现类。
* 特点:
* 1. 元素不能重复
* 2. 元素无序的,特别是它不保证该顺序恒久不变
* 3. 底层的数据结构是HashMap<K,V>,HashMap的底层是哈希表
* HashSet中的元素作为了HashMap的key
* 4. 线程不安全,安全性低,效率高
*
* 哈希表:散列表(Hash table,也叫哈希表),是根据关键码值(Key)而直接进行访问的数据结构。
* 也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
*
* 哈希表是一个数组
*
* 哈希表中的数据会产生哈希冲突(碰撞)。
* 哈希冲突(碰撞):
* 1. 不同的key,hashCode值一样;hashCode值一样在哈希表中的索引就一样,这就是哈希冲突。
* 2. 不同的key,hashCode值不一样,也可能计算出来的索引值一样,这就是哈希冲突。
*
* 所以我们要尽可能的减少hash冲突。所以我们在覆写hashCode函数的时候,都要做到尽可能的减少hashCode值一样。
*
* 哈希表增删查改效率都高。
*
*/
public class HashSetDemo01 {
public static void main(String[] args) {
HashSet<Integer> set1 = new HashSet<>();
set1.add(10);
set1.add(20);
set1.add(30);
// System.out.println(set1);
/*
* hashCode()值是int类型
*
* Integer的hashCode值就是数据本身
* Long的hashCode计算公式: (int)(value ^ (value >>> 32));
*/
System.out.println(new Integer(10).hashCode());
System.out.println(new Long(10).hashCode());
System.out.println(new Float(3.14f).hashCode());
System.out.println(new Double(3.14).hashCode());
/**
* 1314 = 1 * 10 ^ 3 + 3 * 10 ^ 2 + 1 * 10 ^ 1 + 4 * 10 ^ 0
* java = j * n ^ 3 + a * n ^ 2 + v * n ^ 1 + a * n ^ 0
* n 在计算机中使用31
* java = j * 31 ^ 3 + a * 31 ^ 2 + v * 31 ^ 1 + a * 31 ^ 0
* = (j * 31 ^ 2 + a * 31 + v )* 31 + a
* = ((j * 31 + a ) * 31 + v) * 31 + a
*/
System.out.println("java".hashCode());
// 自定义对象的hashCode,需要我们自己重写hashCode()
/*
* & 运算
* 需求:怎么将int数组得到0-9的值
* 1. 模运算
* 2. &运算,还能保证结果是正数
*
*/
System.out.println(-20 % 10);
System.out.println(-21 % 10);
System.out.println(-23 % 10);
System.out.println("---------------------");
System.out.println(-20 & (10-1));
System.out.println(-210 & (10-1));
System.out.println(-223 & (10-1));
/*
* 9 --- 00001001
* 11111111
* & 0000000 0000000 00000000 00001001
*
*/
}
}
HashSet是如何去重的?
import java.util.HashSet;
/**
* HashSet是如何去重的?
* 根据元素的hashCode值计算出对应的索引
* 索引值不同:也就意味着数据在hash表的不同位置上,此时直接存储
* 索引值相同:说明数据要在相同的位置上存储,此时需要调用equals()判断该位置上是否已经存在相同内容的元素
* equals结果为true: 覆盖数据
* equals结果为false: 直接存储
*/
public class HashSetDemo02 {
public static void main(String[] args) {
HashSet<Integer> set = new HashSet<>();
set.add(10);
set.add(20);
set.add(30);
set.add(10);
System.out.println(set.size()); // 3
System.out.println(set);
}
}
研究:自定义对象如何根据内容去重?
import java.util.HashSet;
/**
* 研究:自定义对象如何根据内容去重
*/
public class HashSetDemo03 {
public static void main(String[] args) {
HashSet<Student> set = new HashSet<>();
/**
* HashSet的去重原理:
* 根据hashCode计算索引位置
* 索引不同: 直接存储
* 索引相同:调用equals判断内容
* 内容相同:覆盖内容
* 内容不同:直接存储
*
* 以下代码会先根据元素Student对象的hashCode()计算索引
* 对象的hashCode()如果没有覆写,结果是对象的地址值转换得到,现在元素全部是new
* 的,所以地址值一定不一样,所以hashCode值一定不一样
*
* hashCode值不一样,索引有可能会一样,此时会调用equals函数。
* 对象的equals函数如果没有覆写,默认比较的是地址值。所以内容不同,直接存储
*
*
* HashSet中自定义对象如何根据内容去重?
* 覆写hashCode()和eqausls()
*
*
*/
set.add(new Student("张三",20));
set.add(new Student("李四",21));
set.add(new Student("王五",22));
set.add(new Student("张三",20));
System.out.println(set.size()); // 4
for (Student student : set) {
System.out.println(student);
}
}
}
LinkedHashSet
import java.util.LinkedHashSet;
/**
* LinkedHashSet类是HashSet的子类
* 底层是 链表+哈希表
* 特点: 元素唯一且有序;线程不安全
*/
public class LinkedHashSetDemo {
public static void main(String[] args) {
LinkedHashSet<Integer> set = new LinkedHashSet<>();
set.add(10);
set.add(20);
set.add(30);
set.add(50);
for (Integer integer : set) {
System.out.println(integer);
}
}
}
覆写HashCode的原则
/**
* 覆写hashCode的原则:尽可能降低hash冲突
*
* 降低hash冲突就会减少equals的比较次数
*/
@Override
public int hashCode() {
/**
* 对象的hashCode值根据内容得到
*/
return age * 31 + name.hashCode();
}TreeSet类
TreeSet类:
- TreeSet类是Set接口的实现类
- TreeSet元素不重复
- TreeSet底层数据结构是TreeMap;TreeMap的底层是红黑树
- 红黑树是一种自平衡的二叉树,左右子树的高度不能高过2。
- TeeSet的作用:是对元素进行排序。
import java.util.TreeSet;
/**
* http://www.cs.usfca.edu/~galles/visualization/Algorithms.html
*/
public class TreeSetDemo01 {
public static void main(String[] args) {
test01();
}
// 自然顺序进行排序
private static void test01() {
// 自然顺序进行排序。
TreeSet<Integer> set = new TreeSet<>();
set.add(20);
set.add(12);
set.add(8);
set.add(4);
/*
* java中的包装类和String都已经实现了自然排序接口Comparable
*/
System.out.println(set);
}
}
TreeSet排序的方式有两种
使用自然排序接口(Comparable)实现排序
/* 自然排序接口Comparable<T>: * int compareTo(T o) 比较方法 * 返回值 * 0:表示相等 * 负数:表示小于 * 正数: 表示大小 */ /* * 自然排序的弊端: * 1. 自然排序和元素类耦合在一起,排序规则变化就需要修改元素类的源码 * 这违背了面向对象的开发原则:OCP原则 * OCP原则: 对扩展开放;对修改关闭 * * 2. 由于代码耦合,所以当出现多种排序要求的时候,Comparable接口就不好处理的。 * 所以Comparable排序只适合做只有一种排序要求的情况。 */使用比较器排序接口(Comparator)实现排序
/*比较器排序Comparator: * Comparator<T>接口: * int compare(T o1, T o2) : 比较方法 * 返回值 * 0:表示相等 * 负数:表示小于 * 正数: 表示大小 * Comparator<T>接口的比较方法中有两个对象,这两个对象就是需要比较的对象。 * 既然两个对象在参数中已经有了,所以不需要用元素类实现Comparator接口,所以 * Comparator接口做到了和元素类的解耦。 */比较器排序的优点:
/* * 1. 和需要比较的元素类是解耦的 * 2. 满足OCP原则 * 3. 可以做多种排序需求;一种排序需求就创建一个对应的Comparator的实现类(策略设计模式) */
使用哪一种排序具体取决于使用的构造方法。
TreeSet存储自定义对象——按照员工的年龄升序【自然排序】
import java.util.TreeSet;
/**
* 实现自然排序
*/
class Worker implements Comparable<Worker> {
private int id;
private String name;
private int age;
public Worker() {
}
public Worker(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Worker{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
/**
* 比较方法
* 比较对象一个是this,一个是参数
*/
@Override
public int compareTo(Worker o) {
/*
* 编写比较规则,注意主要条件和辅助条件
* 主要条件就是需求中给出来的条件,这里就是 按照员工的年龄升序
* 辅助条件需要自己找,怎么找?
* 辅助条件的作用是用来区分不同的对象,所以找能够区分不同对象的字段所谓辅助条件
* 这里id应该就是唯一的,所以可以用来做辅助条件。
*
* 注意: 如果一个字段不能区分唯一性,可以使用多个字段来区分
*
* 所以编写比较规则的时候,先比较主要条件,当主要条件的结果是0的时候,再次比较辅助条件。
*
*/
// 先比较主要条件
int a = this.age - o.age;
// 当主要条件的结果是0的时候,再次比较辅助条件。
if(a == 0){
return this.id - o.id;
}
return a;
}
}
/**
* TreeSet存储自定义对象
*
* 需求: 按照员工的年龄升序
*/
public class TreeSetDemo02 {
public static void main(String[] args) {
TreeSet<Worker> set = new TreeSet<>();
/*
* java.lang.ClassCastException: com.powernode.p2.Worker cannot be cast to java.lang.Comparable
* 出现类转换异常的原因:
* TreeSet的作用是对元素进行排序,这里使用的是TreeSet无参构造,也就是使用自然排序Comparable接口排序,
* 但是Worker没有实现Comparable接口,所以抛出以上的错误。
*
* 元素没有实现Comparable接口,也就是没有告诉TreeSet,元素按照什么规则排序。
* 所以我们需要实现Comparable接口,覆写比较方法,实现比较规则
*
*
*/
set.add(new Worker(1001,"张三",25));
set.add(new Worker(1002,"李四",27));
set.add(new Worker(1003,"王五",23));
set.add(new Worker(1004,"韩梅梅",23));
System.out.println(set.size());
for (Worker worker : set) {
System.out.println(worker);
}
}
}
使用比较器排序接口(Comparator)实现排序
import java.util.TreeSet;
import java.util.Comparator;
/**
* 演示:使用比较器排序接口(Comparator)实现排序
* 需求: 1 按照年龄升序 -- 创建ComparatorForAsc比较器
* 2 按照年龄降序 -- 创建ComparatorForDesc比较器
*/
/**
* 年龄升序的比较器
*/
class ComparatorForAsc implements Comparator<Cat> {
@Override
public int compare(Cat o1, Cat o2) {
// 主要条件: 年龄升序
int age = o1.getAge() - o2.getAge();
// 辅助条件: 判断name是否相同
if(age == 0){
return o1.getName().compareTo(o2.getName());
}
return age;
}
}
/**
* 按照年龄降序的比较器
*/
class ComparatorForDesc implements Comparator<Cat> {
@Override
public int compare(Cat o1, Cat o2) {
// 主要条件: 年龄升序
int age = o2.getAge() - o1.getAge();
// 辅助条件: 判断name是否相同
if(age == 0){
return o1.getName().compareTo(o2.getName());
}
return age;
}
}
class Cat {
private String name;
private int age;
public Cat() {
}
public Cat(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Cat{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public class TreeSetDemo03 {
public static void main(String[] args) {
// 通过构造函数使用比较器排序接口
// TreeSet<Cat> set = new TreeSet<>(new ComparatorForAsc());
TreeSet<Cat> set = new TreeSet<>(new ComparatorForDesc());
set.add(new Cat("黑猫警长",3));
set.add(new Cat("波斯猫",2));
set.add(new Cat("狸花猫",3));
System.out.println(set.size());
for (Cat cat : set) {
System.out.println(cat);
}
}
}
HashMap类
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* HashMap类
* 1. HashMap是Map接口的实现类
* 2. 底层是哈希表的数据结构
* 3. 线程不安全的,安全性低,效率高
* 4. 允许使用 null 值和 null 键
*
* java中的hash表是一个元素是链表的数组。
* 问题1:hash表中的数组初始容量是多少?
* hash表中的数组初始容量是 16
* hash表的容量必须是2的幂次方(MUST be a power of two.)。为什么?
* 因为jdk中HashMap计算hash表的索引是使用的 &(len-1)。如果不是2的幂次方,就会出现空间的浪费。
*
* 问题2:hash表中的数组怎么扩容?
* newCap = oldCap << 1
* 新容量 = 旧容量的2倍
* 容量必须满足:<= 2的30次方
*
* 问题3: 什么时候会扩容?
* HashMap中有一个默认的负载因子是0.75;负载因子的作用是Map集合的一个阈值。
* 也就说当Map中的元素达到 容量*0.75的时候就会扩容了
* 比如: 16 * 0.75 = 12的时候就会扩容了。
* 负载因子是一个时间和空间上的都相对比较好的值。
* 负载因子太小,浪费空间
* 负载因子太大,会增加哈希冲突的风险,操作数据的效率会受影响
*
*/
/**
* 实现自然排序
*/
class Worker implements Comparable<Worker> {
private int id;
private String name;
private int age;
public Worker() {
}
public Worker(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Worker{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
/**
* 比较方法
* 比较对象一个是this,一个是参数
*/
@Override
public int compareTo(Worker o) {
/*
* 编写比较规则,注意主要条件和辅助条件
* 主要条件就是需求中给出来的条件,这里就是 按照员工的年龄升序
* 辅助条件需要自己找,怎么找?
* 辅助条件的作用是用来区分不同的对象,所以找能够区分不同对象的字段所谓辅助条件
* 这里id应该就是唯一的,所以可以用来做辅助条件。
*
* 注意: 如果一个字段不能区分唯一性,可以使用多个字段来区分
*
* 所以编写比较规则的时候,先比较主要条件,当主要条件的结果是0的时候,再次比较辅助条件。
*
*/
// 先比较主要条件
int a = this.age - o.age;
// 当主要条件的结果是0的时候,再次比较辅助条件。
if(a == 0){
return this.id - o.id;
}
return a;
}
}
public class HashMapDemo {
public static void main(String[] args) {
HashMap<String, Worker> map = new HashMap<>();
map.put("第一名",new Worker(1001,"zhansgan",20));
map.put("第二名",new Worker(1002,"李四",21));
Set<Map.Entry<String, Worker>> entries = map.entrySet();
for (Map.Entry<String, Worker> entry : entries) {
System.out.println(entry);
}
}
}
Hashtable和HashMap比较
- 两者的数据结构都是哈希表
- HashMap可以使用null作为键或值,Hashtable不能
- HashMap线程不安全,效率高;Hashtable线程安全,效率低。
eg:
import java.util.Hashtable;
public class HashtableDemo {
public static void main(String[] args) {
Hashtable<String,Integer> hashtable = new Hashtable<>();
// Hashtable不能使用null作为键或值
hashtable.put(null,100);
hashtable.put("a",null);
System.out.println(hashtable);
}
}LinkedHashMap——底层是链表+哈希表
保证key的有序性和唯一性
import java.util.LinkedHashMap; public class LinkedHashMapDemo { public static void main(String[] args) { LinkedHashMap<String,String> map = new LinkedHashMap<>(); map.put("a","java"); map.put("c","c"); map.put("b","go"); System.out.println(map); } }
Map接口
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* Map接口
* 1. Map接口中的数据是KV格式
* 2. Map中Key是唯一的;Value可以重复
* 说明Map接口中的数据结构只对Key有效。
*
*
* 方法摘要
* 增:
* V put(K key, V value)
* 将指定的值与此映射中的指定键关联(可选操作)。
* void putAll(Map<? extends K,? extends V> m)
* 从指定映射中将所有映射关系复制到此映射中(可选操作)。
* 删:
* V remove(Object key)
* 如果存在一个键的映射关系,则将其从此映射中移除(可选操作)。
* void clear()
* 从此映射中移除所有映射关系(可选操作)。
* 查:
* boolean containsKey(Object key)
* 如果此映射包含指定键的映射关系,则返回 true。
* boolean containsValue(Object value)
* 如果此映射将一个或多个键映射到指定值,则返回 true。
* Set<Map.Entry<K,V>> entrySet()
* 返回此映射中包含的映射关系的 Set 视图。
* V get(Object key)
* 返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null。
* Set<K> keySet()
* 返回此映射中包含的键的 Set 视图
* Collection<V> values()
* 返回此映射中包含的值的 Collection 视图。
*
* 改:
* V put(K key, V value)
* 将指定的值与此映射中的指定键关联(可选操作)
* V replace(K key, V value)
* 将指定的值与此映射中的指定键关联
* 其它方法:
* boolean isEmpty()
* 如果此映射未包含键-值映射关系,则返回 true。
* int size()
* 返回此映射中的键-值映射关系数。
*
*
*
* 嵌套接口:
* static interface Map.Entry<K,V>
* 映射项(键-值对)。
* Entry接口:
* 映射项(键-值对)。
* 方法摘要 :
* K getKey()
* 返回与此项对应的键。
* V getValue()
* 返回与此项对应的值。
* V setValue(V value)
* 用指定的值替换与此项对应的值(可选操作)。
*
*/
public class MapDemo {
public static void main(String[] args) {
// test01();
// test02();
// test03();
// test04();
test05();
}
// 其它方法
private static void test05() {
Map<Integer,String> map = new HashMap<>();
map.put(1,"hello");
map.put(2,"c++");
map.put(3,"java");
System.out.println(map.size());
System.out.println(map.isEmpty());
}
// 改
private static void test04() {
Map<Integer,String> map = new HashMap<>();
map.put(1,"hello");
map.put(2,"c++");
map.put(3,"java");
// 将key为2的数据修改成php
map.put(2,"php");
System.out.println(map);
map.replace(2,"go"); // 底层是put
System.out.println(map);
}
// 查
private static void test03() {
Map<Integer,String> map = new HashMap<>();
map.put(1,"hello");
map.put(2,"c++");
map.put(3,"java");
// containsKey(Object key): 查询key是否存在
boolean b = map.containsKey(3);
System.out.println(b);
// containsValue(Object value): 查询value是否存在
boolean bool = map.containsValue("java");
System.out.println(bool);
/*
* V get(Object key): 根据指定的key获取value
*/
String s = map.get(2);
System.out.println(s);
System.out.println("-----------keySet----------");
/*
* Set<K> keySet(): 获取所有的key
*/
Set<Integer> keys = map.keySet();
for (Integer key : keys) {
System.out.println(key +"-->"+ map.get(key));
}
/*
* Collection<V> values(): 获取所有的values
*/
System.out.println("-----------values----------");
Collection<String> values = map.values();
for (String value : values) {
System.out.println(value);
}
System.out.println("-----------entrySet------------");
/*
* Entry叫做映射项,就是kv键值对,map中将kv键值对封装成了Entry对象
* 所以获取到Entry对象就可以拿到k和v
* Set<Map.Entry<K,V>> entrySet(): 获取所有的Entry对象
*
*/
Set<Map.Entry<Integer, String>> entries = map.entrySet();
for (Map.Entry<Integer, String> entry : entries) {
// System.out.println(entry);
// System.out.println(entry.getKey() + "--->" + entry.getValue());
Integer key = entry.getKey();
if(key.equals(2)){
entry.setValue("测试数据");
}
}
System.out.println(map);
}
// 删
private static void test02() {
Map<Integer,String> map = new HashMap<>();
map.put(1,"hello");
map.put(2,"c++");
map.put(3,"java");
System.out.println("删除前:" + map);
String v = map.remove(2);
System.out.println("删除的元素是:" + v);
System.out.println("删除后:" + map);
map.clear(); // 清空数据
System.out.println(map); // {}
}
// 增
private static void test01() {
Map<Integer,String> map = new HashMap<>();
String s = map.put(1, "java"); // 返回被覆盖的值
s = map.put(1, "c++"); // key相同就会覆盖原来的值
System.out.println(s); // java
System.out.println(map);// {1=c++}
}
}
Collections类——集合的工具类
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
/**
* Collections类: 集合的工具类
*
* 常用方法:
* static <T> boolean addAll(Collection<? super T> c, T... elements)
* 将所有指定元素添加到指定 collection 中。
*
* static <T> int binarySearch(List<? extends Comparable<? super T>> list, T key)
* 使用二分搜索法搜索指定列表,以获得指定对象。
*
* static <T> void fill(List<? super T> list, T obj)
* 使用指定元素替换指定列表中的所有元素。
*
* static void reverse(List<?> list)
* 反转指定列表中元素的顺序。
*
* static void shuffle(List<?> list) : 洗牌,就是将集合中的元素打乱
*
* static <T extends Comparable<? super T>> void sort(List<T> list)
* 根据元素的自然顺序 对指定列表按升序进行排序。
*
* static <T> void sort(List<T> list, Comparator<? super T> c)
* 根据指定比较器产生的顺序对指定列表进行排序。
*
* static void swap(List<?> list, int i, int j)
* 在指定列表的指定位置处交换元素。
*/
public class CollectionsDemo {
public static void main(String[] args) {
// addAll(Collection<? super T> c, T... elements)
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list,1,2,3,4,5);
System.out.println(list);
// binarySearch(List<? extends Comparable<? super T>> list, T key)
int index = Collections.binarySearch(list, 3);
System.out.println(index);
// fill(List<? super T> list, T obj)
// Collections.fill(list,100);
// System.out.println(list);
// reverse(List<?> list)
Collections.reverse(list);
System.out.println(list);
// shuffle(List<?> list)
Collections.shuffle(list);
System.out.println(list);
// 将list的元素降序
Collections.sort(list, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
System.out.println(list);
// swap(List<?> list, int i, int j)
System.out.println("交换前:" + list);
Collections.swap(list,0,3);
System.out.println("交换后:" + list);
}
}
TreeMap类
TreeMap是Map接口的实现类
TreeMap底层是红黑树
红黑树的数据结构是约束key的
TreeMap的作用:可以对Map中的Key排序
排序方式两种:
- 自然比较排序(Comparable接口)
- 比较器排序(Comparator接口)
注意:使用什么排序,具体取决于使用的构造方法。
eg:
import java.util.Comparator; import java.util.TreeMap; class Dog implements Comparable<Dog>{ private String name; private int age; public Dog() { } public Dog(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Dog{" + "name='" + name + '\'' + ", age=" + age + '}'; } /** * 按照年龄升序 */ @Override public int compareTo(Dog o) { int a = this.age - o.age; if(a == 0){ return this.name.compareTo(o.name); } return a; } } public class TreeeMapDemo { public static void main(String[] args) { // 自然比较排序: 对key排序 TreeMap<Integer,String> map = new TreeMap<>(); map.put(100,"a"); map.put(20,"b"); map.put(90,"c"); System.out.println(map); /** * 自然比较排序(Comparable接口) * 使用无参构造的TreeMap,那么Key值必须实现Comparable接口 */ TreeMap<Dog,String> map1 = new TreeMap<>(); map1.put(new Dog("阿黄",10),"土狗"); map1.put(new Dog("旺财",8),"土狗"); map1.put(new Dog("来福",5),"土狗"); System.out.println(map1); /* * 比较器排序(Comparator接口) * 按照年龄降序 */ TreeMap<Dog,String> map2 = new TreeMap<>(new Comparator<Dog>() { @Override public int compare(Dog o1, Dog o2) { int age = o2.getAge() - o1.getAge(); if(age == 0){ return o1.getName().compareTo(o2.getName()); } return age; } }); map2.put(new Dog("阿黄",10),"土狗"); map2.put(new Dog("旺财",8),"土狗"); map2.put(new Dog("来福",5),"土狗"); System.out.println(map2); } }
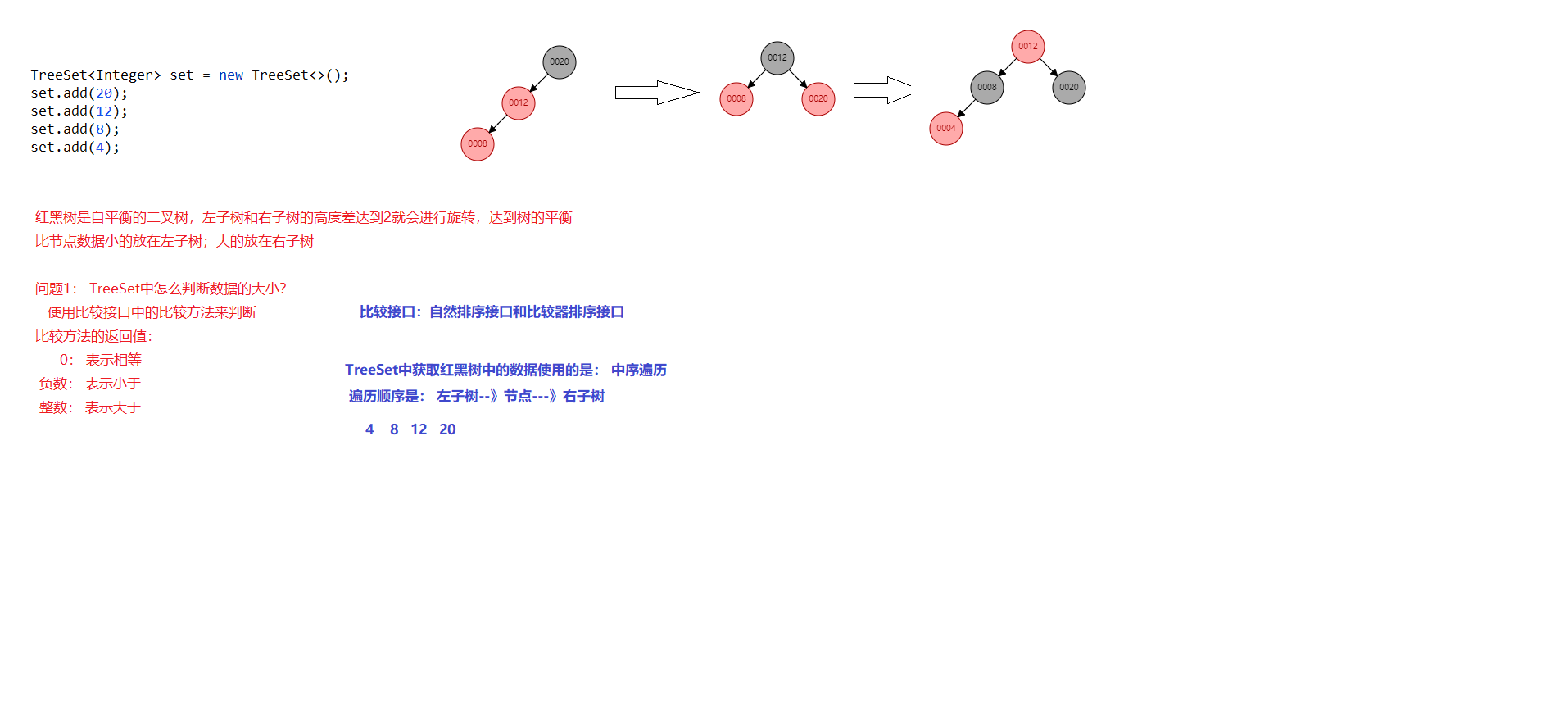
IO流的引入
/**
* 1. IO的引入:
* 目前我们的数据都在内存中存储的。程序一旦退出,数据就丢失了。所以我们需要将数据能持久化存储。
* 数据要持久化存储就需要将数据以文件的方式保存到硬盘上,这样数据才能持久化存储。
* 要将数据写入文件中;或者从文件中读取数据,就需要使用IO流。
*
* 我们平常使用的文件复制就需要使用IO流,复制过程就是文件数据的读写过程。
* 如果文件复制是网络之间的,那么这就是下载。
*
* 2. IO流:
* IO: Input和Output 输入和输出
* 流(Stream): 数据流。连续不断的数据。
*
*
* 3. IO流的分类
* 根据流向的不同分为:
* 输入流:读数据,将数据读取到程序中
* 输出流:写数据,将程序中的数据写到文件
*
* 根据操作数据的不同分为:
* 字节流:按照字节为单位读写数据
* 字符流:按照字符为单位读写数据
*
* 基于以上的分类,就可以得到java中的四大基本抽象流:
* 字节输入流(InputStream): 按照字节为单位读数据
* 字节输出流(OutputStream): 按照字节为单位写数据
* 字符输入流(Reader):按照字符为单位读数据
* 字符输出流(Writer):按照字符为单位写数据
*
*
* 刚学IO流大家会觉得有难度,这个难度并不是api很难;而是IO流的种类太多,大家不知道
* 该选择哪个流来使用。
* 怎么办? 所以要求大家学习IO流的时候,一定要自己总结。(推荐使用思维导图来总结),把每一种
* 流的功能和特点总结对比。这样你才能根据功能和特点结合实际业务需求进行选择。
*
*
*/
public class IODemo {
}
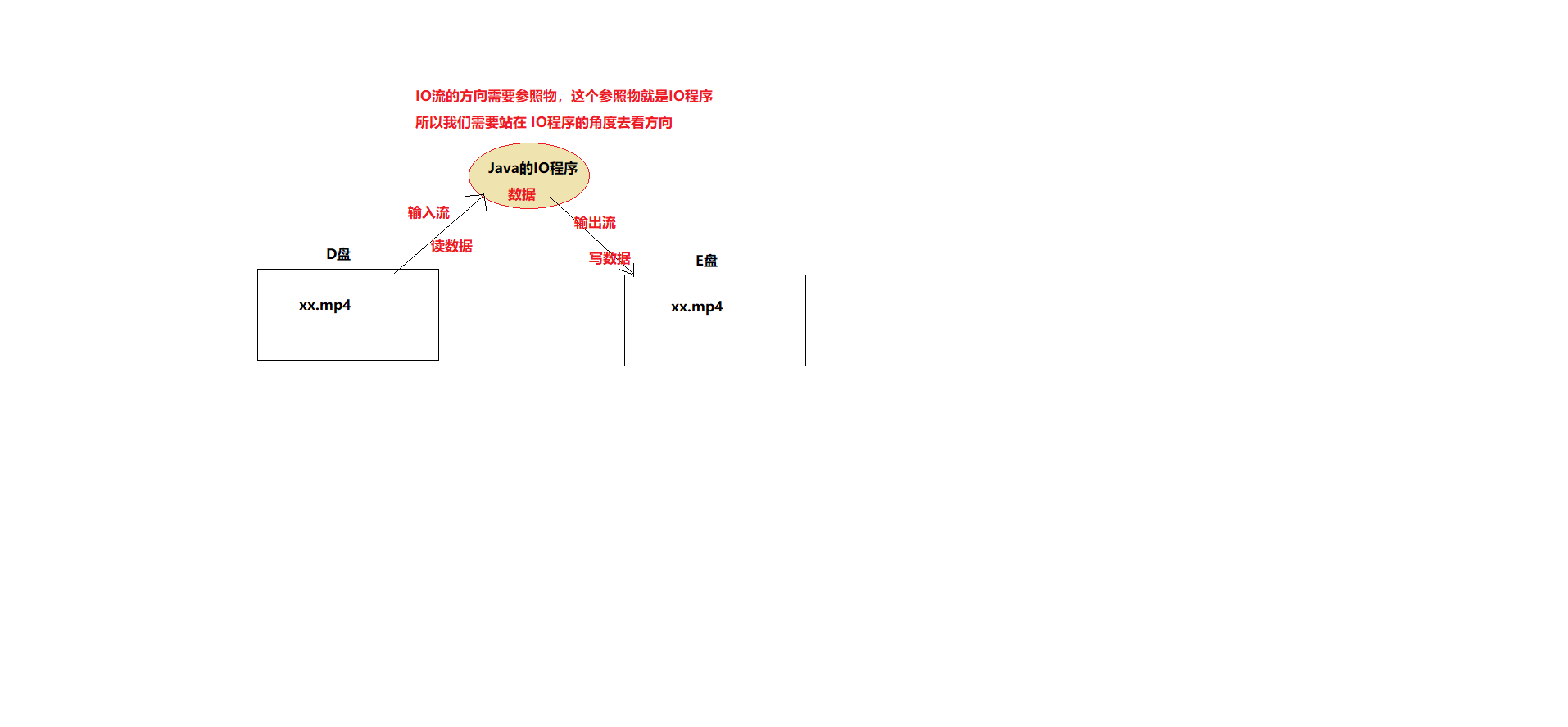
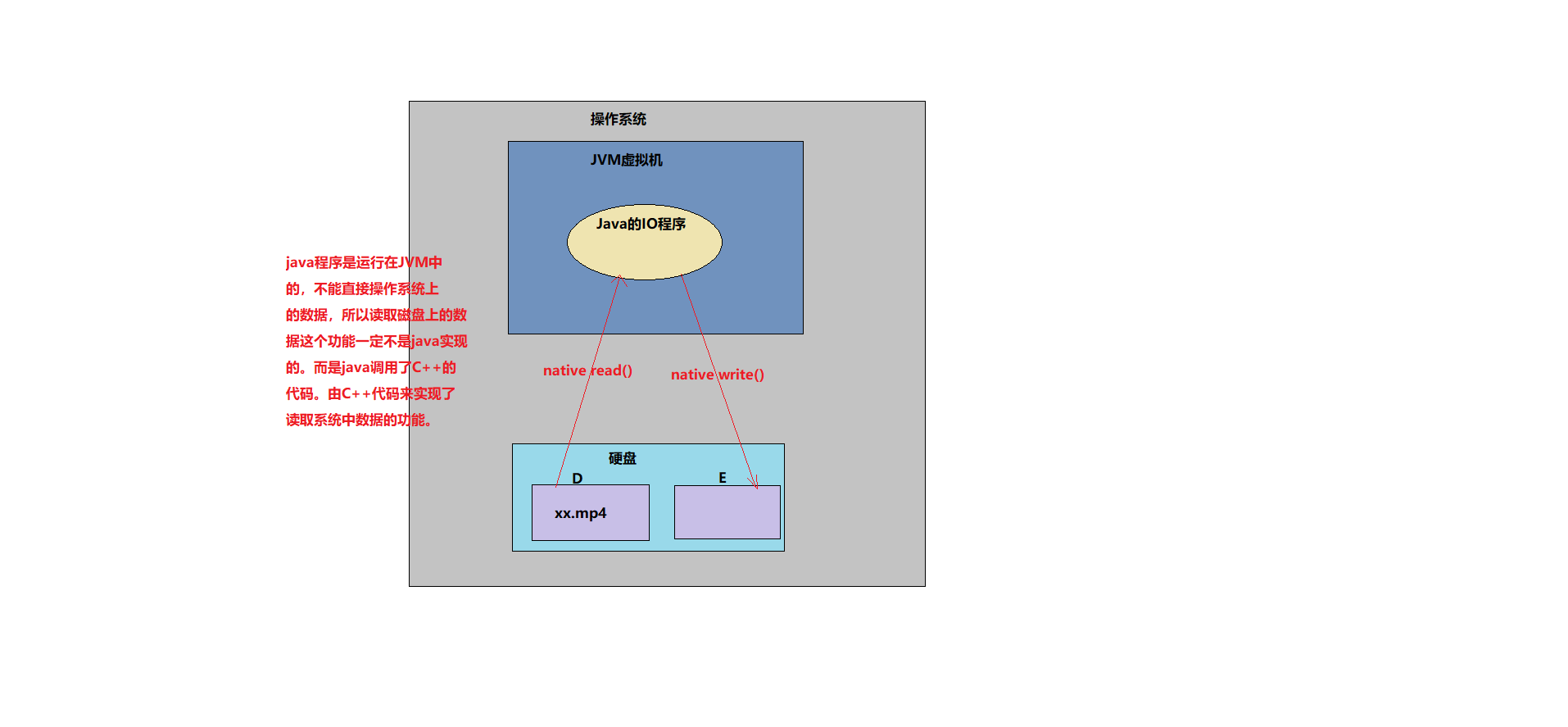
DAY22
OutputStream 字节输出流【FileOutputStream文件字节输出流】
- 表示输出字节流的所有类的超类。
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Arrays;
/**
* 方法摘要
* void close()
* 关闭此输出流并释放与此流有关的所有系统资源。
* void write(byte[] b)
* 将 b.length 个字节从指定的 byte 数组写入此输出流。
* void write(byte[] b, int off, int len)
* 将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流。
* void write(int b)
* 将指定的字节写入此输出流。
*
*
* FileOutputStream类 - 文件字节输出流
* 1. OutputStream的子类
* 2. 作用: 写数据到文件中(以字节为单位)
*
* 构造方法摘要
* FileOutputStream(File file)
* 创建一个向指定 File 对象表示的文件中写入数据的文件输出流。
* FileOutputStream(File file, boolean append)
* 创建一个向指定 File 对象表示的文件中写入数据的文件输出流。
* FileOutputStream(String name)
* 创建一个向具有指定名称的文件中写入数据的输出文件流。
* FileOutputStream(String name, boolean append)
* 创建一个向具有指定 name 的文件中写入数据的输出文件流。
*
*/
public class Demo01 {
public static void main(String[] args) {
FileOutputStream fos = null;
try {
// 1. 创建对象
/*
* 创建FileOutputStream对象的时候
* append为false: 无论文件是否已经存在,都会根据指定的文件路径创建文件。
* append为true: 如果文件存在,就在文件中追加;如果文件不存在,会根据指定的文件路径创建文件。
* 然后将输出流就可以操作该文件
*
* 注意细节:
* 1. FileOutputStream构造中传入的是文件路径,不能传入目录路径
* 2. 如果传入的文件路径中,目录不存在会抛出FileNotFoundException
*/
fos = new FileOutputStream(new File("D://a.txt"),true);
// 2. 让对象干活 -- 写数据
// 单字节写数据
fos.write(97);
/*
* 字节流是不会乱码的,这里的数据写入后,记事本打开后乱码了
* 是因为我们自己将中文的一个字节写入,而不是完整写入,造成的乱码
* 这是我们的问题,不是字节流的问题。
*/
// fos.write(-27);
// fos.write('a');
// 需求: 往文件中写入97这两个数字
// fos.write(57);
// fos.write(55);
} catch (FileNotFoundException exception) {
exception.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
// 3. 释放系统资源
if(fos != null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
FileOutputStream流,按照字节数组写数据
import java.io.FileOutputStream;
import java.io.IOException;
/**
* FileOutputStream流,按照字节数组写数据
*/
public class Demo02 {
public static void main(String[] args) {
FileOutputStream fos = null;
try {
// 1. 创建对象
fos = new FileOutputStream("D://b.txt");
// 2. 让对象干活 -- 写数据
byte[] bytes = "welcome to chengdu".getBytes();
// 按照字节数组写数据 -- 写入字节数组的所有数据
// fos.write(bytes);
// 按照字节数组写数据 -- 写入字节数组的一部分数据
/*
* write(byte b[], int off, int len)
* 第一个参数:写入的字节数组
* 第二个参数: 偏移量,数组的索引是从0开始的,偏移量也是从0开始的,所以可以理解成索引
* 也就是从哪个索引开始写数据
* 第三个参数: 写入的长度,也就是写多少个字节的数据
*/
fos.write(bytes,3,3); // com
} catch (IOException exception) {
exception.printStackTrace();
}finally {
// 3. 释放资源
if(fos != null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
fos = null; // 不是必需的
}
}
}
}
InputStream 字节输入流【FileInputStrem 文件字节输入流】
- 此抽象类是表示字节输入流的所有类的超类。
import java.io.FileInputStream;
import java.io.IOException;
/**
* 方法摘要
* int available()
* 返回此输入流下一个方法调用可以不受阻塞地从此输入流读取(或跳过)的估计字节数。
* void close()
* 关闭此输入流并释放与该流关联的所有系统资源。
* int read()
* 从输入流中读取数据的下一个字节。
* 返回值:读取到的数据字节;如果已到达文件末尾,则返回 -1。
* int read(byte[] b)
* 从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。
* 将数据先读取缓冲在字节数组b中。
* 返回:读入缓冲区的字节总数,如果因为已经到达文件末尾而没有更多的数据,则返回 -1。
* int read(byte[] b, int off, int len)
* 将输入流中最多 len 个数据字节读入 byte 数组。
*
* FileInputStream文件字节输入流
* 1. 是InputStream的子类
* 2. 作用: 读取文件中的数据(以字节为单位)
*
* 注意: 输入流和输出流是对应的
*/
public class Demo03 {
public static void main(String[] args) {
FileInputStream fis = null;
try {
// 1. 创建对象
fis = new FileInputStream("D://b.txt");
// 2. 让对象干活 -- 读数据
// 单字节读数据,返回的是读取到的是数据字节
// int b = fis.read();
// System.out.println(b);
// b = fis.read();
// System.out.println(b);
// b = fis.read();
// System.out.println(b);
// b = fis.read();
// System.out.println(b);
// b = fis.read();
// System.out.println(b);
// b = fis.read();
// System.out.println(b);
// while(true){
// int b = fis.read();
// if(b == -1){
// break;
// }
// System.out.println((char)b);
// }
int b; // 用来接受读取到的数据字节
while((b = fis.read()) != -1){
System.out.println((char)b);
}
} catch (IOException exception) {
exception.printStackTrace();
}finally {
// 3. 释放资源
if(fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
FileInputStream按照字节数组读数据
import java.io.FileInputStream;
import java.io.IOException;
/**
* 演示: FileInputStream按照字节数组读数据
*/
public class Demo04 {
public static void main(String[] args) {
FileInputStream fis = null;
try {
fis = new FileInputStream("D://b.txt");
/**
* 按照字节数组读取数据
* int read(byte b[]): 将数据读取缓存在字节数组b中
* 参数:就是我们自己定义的字节数组,用作缓冲区,缓存数据
* 返回值:读取到的字节总数
*
* 缓冲区的大小建议: 1024-8192
* 值推荐写 2的幂次方
*/
byte[] bs = new byte[1024];
int len; // 读取到的字节总数
while((len = fis.read(bs)) != -1){
System.out.print(new String(bs,0,len));
}
} catch (IOException exception) {
exception.printStackTrace();
}finally {
if(fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
使用文件字节流复制文件
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* 使用文件字节流复制文件
* 分析:
* 1. 创建文件字节输入流
* 2. 创建文件字节输出流
* 3. 读取源文件数据
* 4. 将读取到的数据写入目标文件
* 5. 释放资源
*/
public class CopyFileDemo {
public static void main(String[] args) {
String src = "D:\\video\\116.面向对象基础_匿名对象的概述.avi";
String dest = "E://aa.avi";
// copyFileByByte(src,dest);
copyFileByByteArray(src,dest);
}
/**
* 按照字节数组复制文件
* @param src 源文件路径
* @param dest 目标文件路径
*/
public static void copyFileByByteArray(String src,String dest){
FileInputStream fis = null;
FileOutputStream fos = null;
try {
// 1. 创建文件字节输入流
fis = new FileInputStream(src);
// 2. 创建文件字节输出流
fos = new FileOutputStream(dest);
// 3. 读取源文件数据
byte[] bs = new byte[1024];
int len;
long start = System.currentTimeMillis();
while((len = fis.read(bs)) != -1){
// 4. 将读取到的数据写入目标文件
fos.write(bs,0,len);
}
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start));
} catch (IOException exception) {
exception.printStackTrace();
}finally {
// 5. 释放资源, 后使用的先关闭
if(fos != null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 单字节方式复制文件
*/
public static void copyFileByByte(String src,String dest){
FileInputStream fis = null;
FileOutputStream fos = null;
try {
// 1. 创建文件字节输入流
fis = new FileInputStream(src);
// 2. 创建文件字节输出流
fos = new FileOutputStream(dest);
// 3. 读取源文件数据
int b;
long start = System.currentTimeMillis();
while((b = fis.read()) != -1){
// 4. 将读取到的数据写入目标文件
fos.write(b);
}
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start));
} catch (IOException exception) {
exception.printStackTrace();
}finally {
// 5. 释放资源, 后使用的先关闭
if(fos != null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
Writer——字符输出流的抽象类
/**
* 在计算机中所有的数据都是字节,所以读写数据的时候也是读写的字节数据
* 想要读写字符数据,就需要将字节数据转成字符。
* 所以:
* 字符流 = 字节流 + 字符编码;
*
* Writer类:
* 字符输出流的抽象类。
* 方法摘要
*
* void close()
* 关闭此流,但要先刷新它。
* void flush()
* 刷新该流的缓冲。
* void write(char[] cbuf)
* 写入字符数组。
* void write(char[] cbuf, int off, int len)
* 写入字符数组的某一部分。
* void write(int c)
* 写入单个字符。
* void write(String str)
* 写入字符串。
* void write(String str, int off, int len)
* 写入字符串的某一部分。
*/OutputStreamWriter — 转换流【字符流通向字节流的桥梁】
- 是Writer的子类
- 作用:按照字符写数据
/**
* 构造方法摘要
* OutputStreamWriter(OutputStream out)
* 创建使用默认字符编码的 OutputStreamWriter。
* OutputStreamWriter(OutputStream out, Charset cs)
* 创建使用给定字符集的 OutputStreamWriter。
* OutputStreamWriter(OutputStream out, CharsetEncoder enc)
* 创建使用给定字符集编码器的 OutputStreamWriter。
* OutputStreamWriter(OutputStream out, String charsetName)
* 创建使用指定字符集的 OutputStreamWriter。
*
*/eg:
import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStreamWriter; public class Demo01 { public static void main(String[] args) { OutputStreamWriter writer = null; try { // 字符流 = 字节流 + 字符编码; writer = new OutputStreamWriter(new FileOutputStream("D://word.txt",true)); // 单个字符写入 // 字符输出流的数据写到字符缓冲了 // writer.write('我'); // 按照字符数组写数据 // windows上的换行使用\r\n // writer.write("我爱北京天安门\r\n".toCharArray()); // 直接写字符串 writer.write("你说什么呢"); writer.flush(); // 将字符缓冲中的数据刷写出去 } catch (IOException exception) { exception.printStackTrace(); }finally { if(writer != null){ try { writer.close(); // 字符流关闭的时候也会刷写字符缓冲中的数据 } catch (IOException e) { e.printStackTrace(); } } } } }
Reader —— 字符输入流的抽象类
/**
* 方法摘要
* void close()
* 关闭该流并释放与之关联的所有资源。
* int read()
* 读取单个字符。
* int read(char[] cbuf)
* 将字符读入数组。
* int read(char[] cbuf, int off, int len)
* 将字符读入数组的某一部分。
*/InputStreamReader类 – 转换流【字节流通向字符流的桥梁】
- 是Reader的子类
- 作用:就是按照字符读数据
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
/**
* 构造方法摘要
* InputStreamReader(InputStream in)
* 创建一个使用默认字符集的 InputStreamReader。
* InputStreamReader(InputStream in, Charset cs)
* 创建使用给定字符集的 InputStreamReader。
* InputStreamReader(InputStream in, CharsetDecoder dec)
* 创建使用给定字符集解码器的 InputStreamReader。
* InputStreamReader(InputStream in, String charsetName)
* 创建使用指定字符集的 InputStreamReader。
*
*/
public class Demo02 {
public static void main(String[] args) {
InputStreamReader reader = null;
try {
/**
* 使用InputStreamReader读取数据的时候,编码格式要和文件的编码格式一致
* 否则中文乱码
*
* 这里没有指定字符编码,使用的是当前运行环境的默认编码
*/
reader = new InputStreamReader(new FileInputStream("D://word.txt"));
// 单字符读取
/*
int c;
while((c = reader.read()) != -1){
System.out.print((char)c);
}
*/
// 字符数组读取
int len; // 存储读取到的字符总数
/*
* 定义字符缓冲,大小推荐: 1024-8192
*/
char[] cs = new char[1024];
while((len = reader.read(cs)) != -1){
System.out.println(new String(cs,0,len));
}
} catch (IOException exception) {
exception.printStackTrace();
}finally {
if(reader != null){
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
设置字符流的编码格式
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.charset.Charset;
/**
* 演示: 设置字符流的编码格式
*
*/
public class Demo03 {
public static void main(String[] args) {
InputStreamReader reader = null;
try {
/**
* 使用InputStreamReader读取数据的时候,编码格式要和文件的编码格式一致
* 否则中文乱码
*
* 手动指定字符编码格式
*/
reader = new InputStreamReader(new FileInputStream("D://a.txt"), "GBK");
int len;
char[] cs = new char[1024];
while((len = reader.read(cs)) != -1){
System.out.println(new String(cs,0,len));
}
} catch (IOException exception) {
exception.printStackTrace();
}finally {
if(reader != null){
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}

字符流的便捷类:
一、FileReader类
/**
* FileReader类:
* public class FileReader extends InputStreamReader
* 用来读取字符文件的便捷类
*
*构造方法摘要
* FileReader(File file)
* 在给定从中读取数据的 File 的情况下创建一个新 FileReader。
* FileReader(String fileName)
* 在给定从中读取数据的文件名的情况下创建一个新 FileReader。
*/二、FileWriter类
/**
*FileWriter类:
* public class FileWriter extends OutputStreamWriter
* 用来写入字符文件的便捷类
*
* 构造方法摘要
* FileWriter(File file)
* 根据给定的 File 对象构造一个 FileWriter 对象。
* FileWriter(File file, boolean append)
* 根据给定的 File 对象构造一个 FileWriter 对象。
* FileWriter(String fileName)
* 根据给定的文件名构造一个 FileWriter 对象。
* FileWriter(String fileName, boolean append)
* 根据给定的文件名以及指示是否附加写入数据的 boolean 值来构造 FileWriter 对象。
*/三、字符流的便捷类的结论
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
/**
* 综上得到一个结论:
* 便捷类的便捷体现在:
* 1. 创建对象的时候不需要传入字节流了。便捷类会自动创建文件字节流
* 2. 创建对象的时候不需要传入字符编码了。便捷类会自动使用默认编码
*
* 便捷类的弊端:
* 就是不灵活了。无法手动指定其它类型的字节流;也无法指定其它字符编码
*
*/
public class Demo04 {
public static void main(String[] args) {
// test01();
test02();
}
private static void test02() {
FileReader reader = null;
try {
/**
* FileReader构造中会自动创建FileInputStream对象,无法更改
* 自动使用默认的字符编码,,无法更改
*
* 所以:FileReader只能用于文件编码和运行环境默认编码格式一样的情况下
*/
reader = new FileReader("D://a.txt");
int c = reader.read();
System.out.println((char)c);
} catch (IOException exception) {
exception.printStackTrace();
}finally {
if(reader != null){
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
private static void test01() {
FileWriter writer = null;
try {
/**
* FileWriter构造中自动创建了FileOutputStream对象,无法更改
* 自动使用默认的字符编码,无法更改
*/
writer = new FileWriter("D://w.txt");
writer.write("来了,老弟");
writer.flush();
} catch (IOException e) {
e.printStackTrace();
}finally {
if(writer != null){
try {
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
使用字符流复制文件,直接使用字符数组的方式读写数据
import java.io.*;
/**
* 使用字符流复制文件,直接使用字符数组的方式读写数据
*
* 结论:
* 因为计算中所有的数据都是字节,所以按照字节读取是没有问题的
* 1. 字节流是万能流,什么文件都可以操作
* 2. 字符流不是万能的,什么文件才能使用字符流操作?
* 如果文件使用操作系统的记事本打开后不乱码,就可以使用字符流操作。
*
*/
public class CopyFileByCharDemo {
public static void main(String[] args) {
InputStreamReader reader = null;
OutputStreamWriter writer = null;
try {
/**
* 字符流拷贝图片,图片会损坏
*/
reader = new InputStreamReader(new FileInputStream("D://mm.jpg"));
writer = new OutputStreamWriter(new FileOutputStream("E://meinv.jpg"));
int len;
char[] cs = new char[1024];
while((len = reader.read(cs)) != -1){
writer.write(cs,0,len);
}
writer.flush();
} catch (IOException exception) {
exception.printStackTrace();
}finally {
if(writer != null){
try {
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(reader != null){
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
根据功能的不同流分为
一、节点流 — 普通流:真正读写数据的流
二、处理流 — 包装流/包裹流
三、缓冲流 — 也是一种处理流,增加了缓冲区【BufferedOutputStream — 字节缓冲输出流】
import java.io.BufferedOutputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* 根据功能的不同流分为:
* 节点流(普通流):真正读写数据的流。 --- 真正干活的
* 处理流(包装流/包裹流):是对节点流的封装,也就是在节点流的基础上增加新的功能。但是读写数据还是使用节点流。
*
* 缓冲流:
* 缓冲流是一种处理流,在节点流的基础上增加了功能(增加了缓冲区)
*
*
* BufferedOutputStream: 字节缓冲输出流
* 该类实现缓冲的输出流。通过设置这种输出流,应用程序就可以将各个字节写入底层输出流中,而不必针对每次字节写入调用底层系统。
*
* 构造方法摘要:
* BufferedOutputStream(OutputStream out)
* 创建一个新的缓冲输出流,以将数据写入指定的底层输出流。
* BufferedOutputStream(OutputStream out, int size)
* 创建一个新的缓冲输出流,以将具有指定缓冲区大小的数据写入指定的底层输出流。
*/
public class Demo01 {
public static void main(String[] args) {
BufferedOutputStream bos = null;
try {
/**
* 字节缓冲流的构造函数中需要接收一个字节流(节点流)
* 所以缓冲流就会在接收的节点流上包装一个缓冲区
*
* 默认缓冲区的大小是8192字节
*/
bos = new BufferedOutputStream(new FileOutputStream("D://out.txt"),10);
// 单字节写数据 -- 数据写入缓冲区了
for (int i = 0; i < 11; i++) {
bos.write(97);
}
bos.flush(); // 刷写缓冲区中的数据
} catch (IOException exception) {
exception.printStackTrace();
}finally {
if(bos != null){
try {
/*
* 关闭缓冲流,也会刷写缓冲区中的数据
**/
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
- 字节缓冲输出流单字节写数据的原理
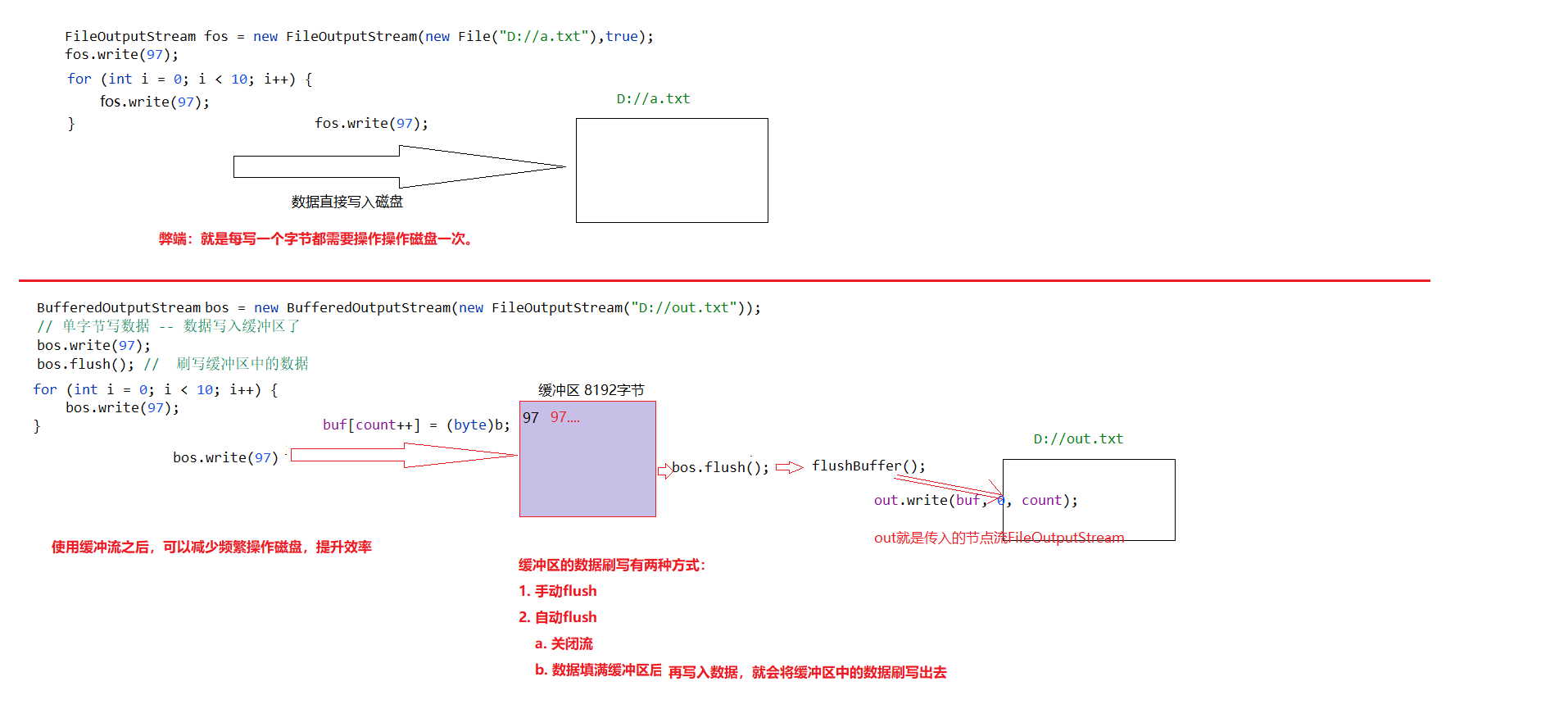
- 节点流和缓冲流的对比
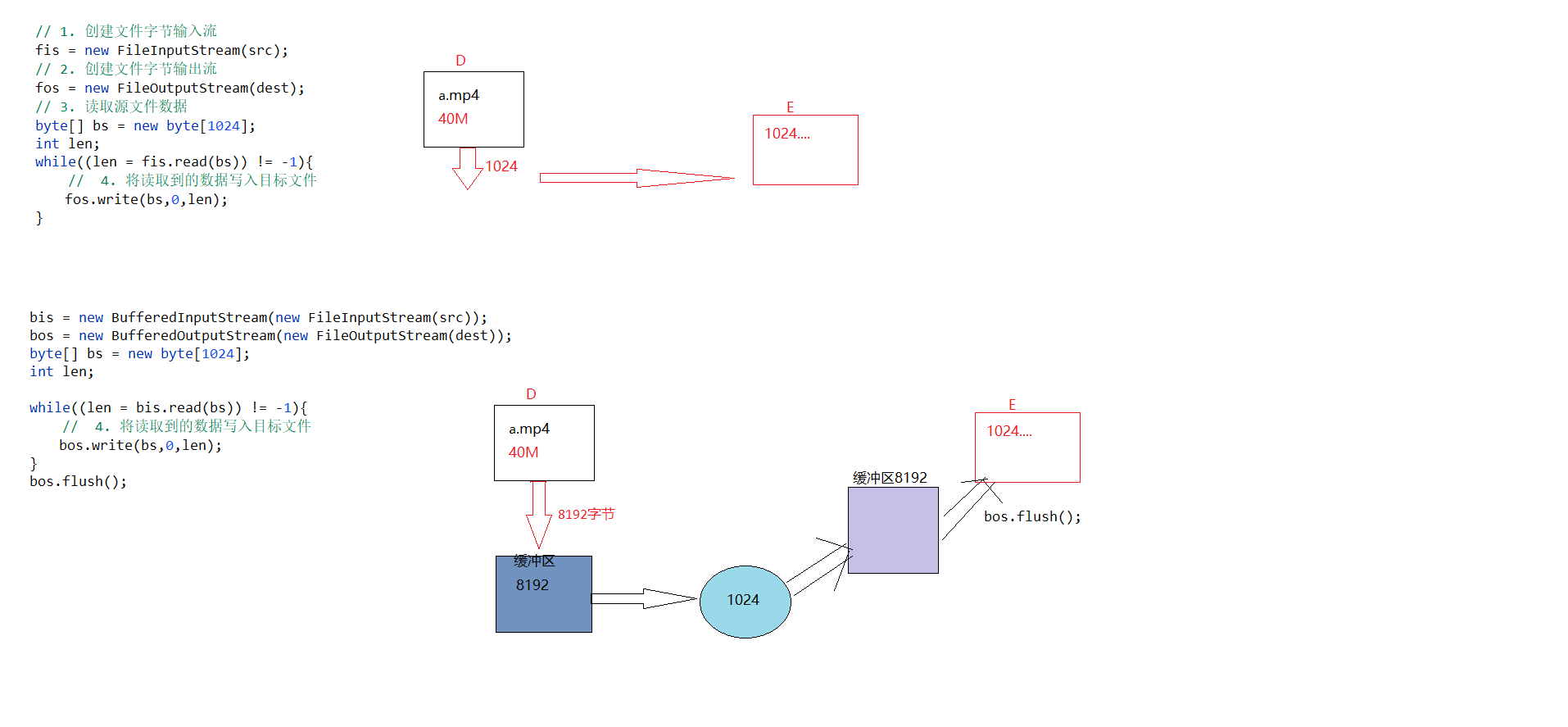
BufferedOutputStream按照字节数组写数据
import java.io.BufferedOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* 演示: BufferedOutputStream按照字节数组写数据
*/
public class Demo02 {
public static void main(String[] args) {
BufferedOutputStream bos = null;
try {
/**
* 字节缓冲流的构造函数中需要接收一个字节流(节点流)
* 所以缓冲流就会在接收的节点流上包装一个缓冲区
*
* 默认缓冲区的大小是8192字节
*/
bos = new BufferedOutputStream(new FileOutputStream("D://out.txt"),10);
// 按照字节数组写数据
byte[] bytes = "abcdeabcde".getBytes();
bos.write(bytes);
bos.flush(); // 刷写缓冲区中的数据
} catch (IOException exception) {
exception.printStackTrace();
}finally {
if(bos != null){
try {
/*
* 关闭缓冲流,也会刷写缓冲区中的数据
**/
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
- 字节缓冲输出流字节数组写数据的原理
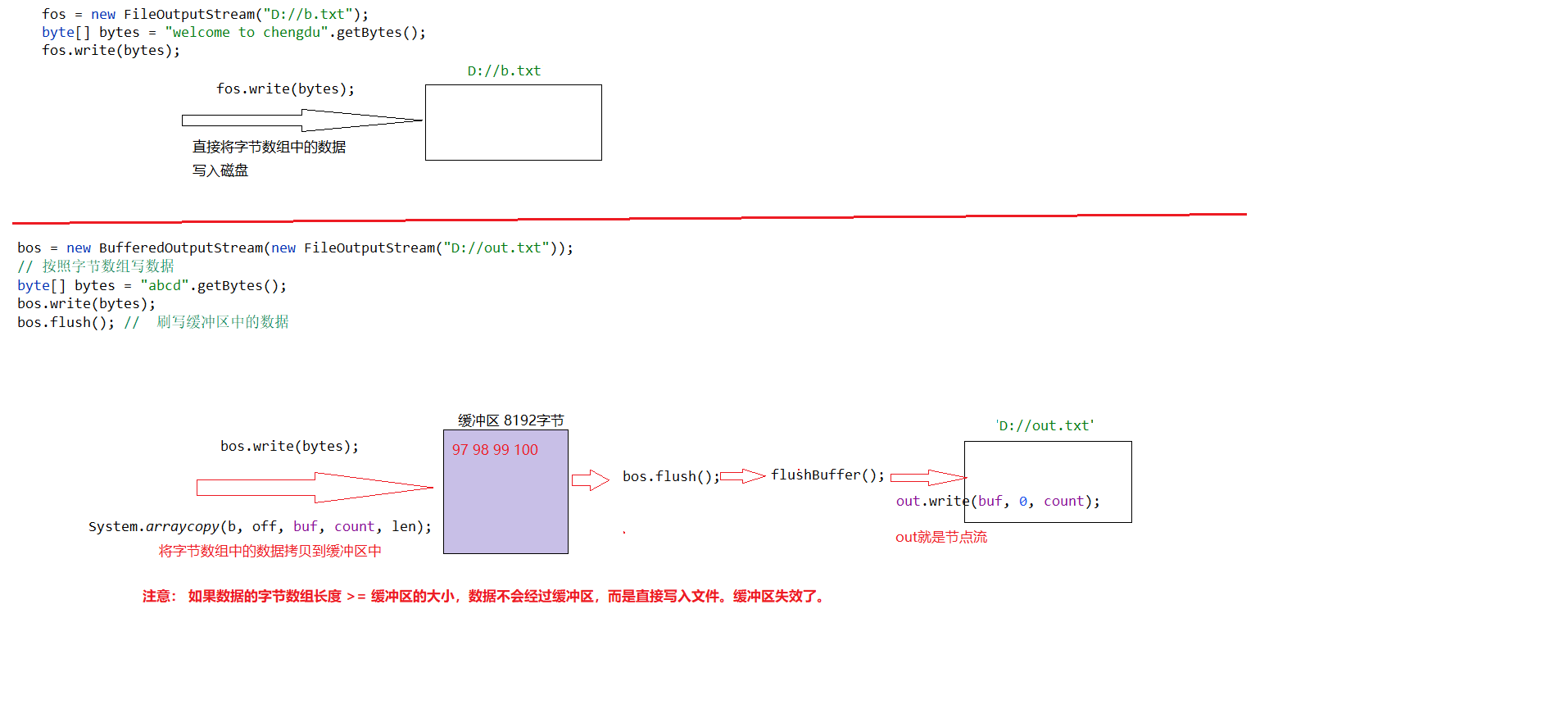
BufferedInputStream 字节缓冲输入流
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;
/**
* BufferedInputStream 字节缓冲输入流
* BufferedInputStream 为另一个输入流添加一些功能,即缓冲输入以及支持 mark 和 reset 方法的能力。
*
*/
public class Demo03 {
public static void main(String[] args) {
BufferedInputStream bis = null;
try {
bis = new BufferedInputStream(new FileInputStream("D://out.txt"));
// 单字节读
int b ;
/**
* BufferedInputStream单字节读数据的流程:
* 1. 现将数据读取最多8192个字节到缓冲区中
* 2. 然后从缓冲区中一个字节一个字节的获取出来
*
* 所以这里的单字节获取数据是从缓冲区中获取。
*/
while((b = bis.read()) != -1){
System.out.println(b);
}
} catch (IOException exception) {
exception.printStackTrace();
}finally {
if(bis != null){
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
字节缓冲输入流单字节读取数据

BufferedInputStream 按照字节数组读取数据
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;
/**
* BufferedInputStream 按照字节数据读取
*/
public class Demo04 {
public static void main(String[] args) {
BufferedInputStream bis = null;
try {
bis = new BufferedInputStream(new FileInputStream("D://out.txt"));
int len;
byte[] bs = new byte[1024];
/**
* BufferedInputStream按照字节数组读取数据的流程:
* 1. 读取最多8192个字节的数据到缓冲区中
* 2. 从缓冲区中通过数组拷贝的方式将数据拷贝到我们自定的字节数组bs
*/
while((len = bis.read(bs)) != -1){
System.out.println(new String(bs,0,len));
}
} catch (IOException exception) {
exception.printStackTrace();
}finally {
if(bis != null){
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
- 字节缓冲输入流字节数组读取数据
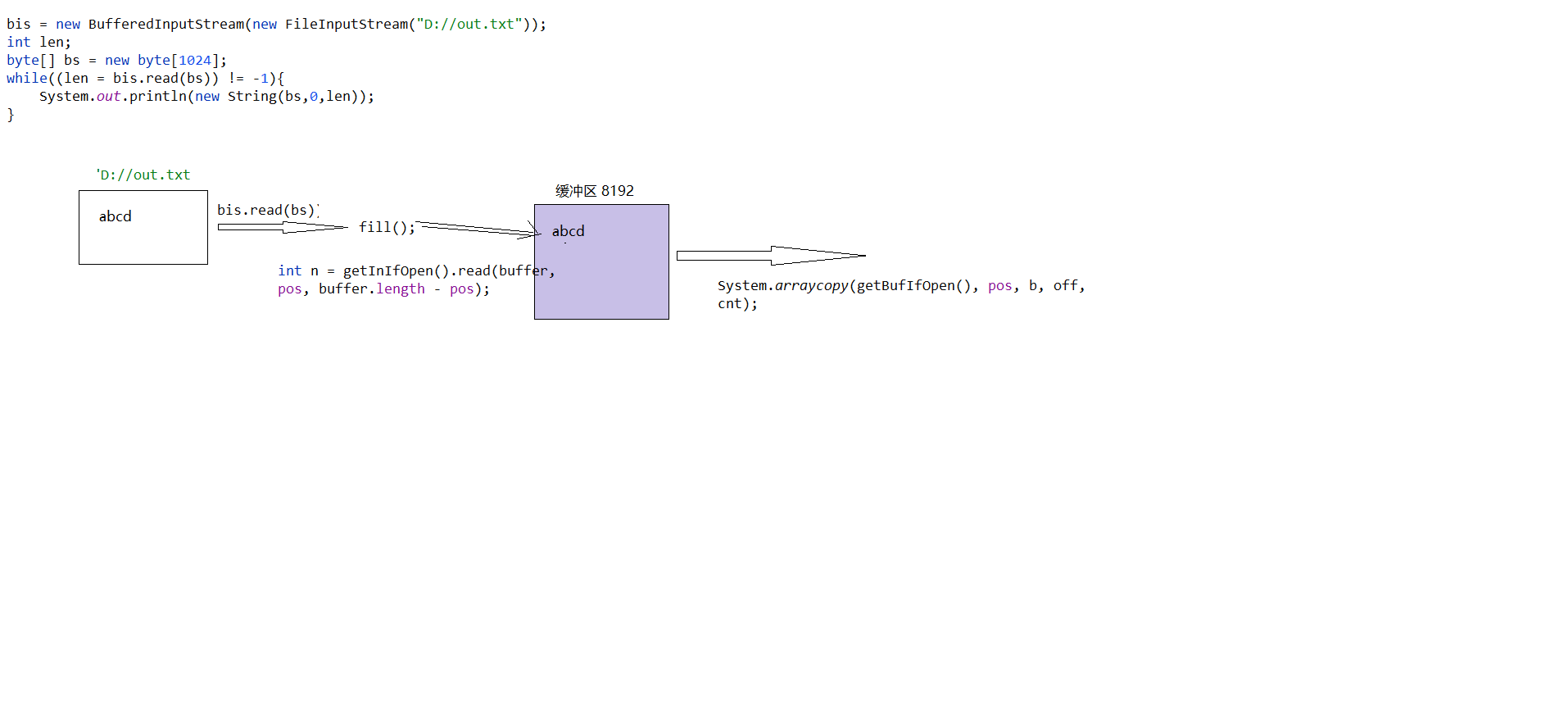
使用缓冲流的好处
import java.io.*;
/**
* 使用缓冲流的好处:
* 1. 减少对磁盘的操作,提升效率。(节点流也可以做到)
* 2. 站在代码的设计角度考虑,使用了装饰设计模式,降低代码的使用难度
* 3. 支持mark和reset方法 -- 了解
*
* 缓冲流的底层原理:大家目前了解即可
* 重点是读写数据操作
*/
public class CopyFileDemo {
public static void main(String[] args) {
String src = "D:\\video\\116.面向对象基础_匿名对象的概述.avi";
String dest = "E://aa.avi";
copyFileByByteArray(src,dest); // 耗时:42
// copyFileByBufferByteArray(src,dest);// 耗时:46
}
/**
* 字节缓冲流按照字节数组复制文件
* @param src 源文件路径
* @param dest 目标文件路径
*/
public static void copyFileByBufferByteArray(String src,String dest){
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
bis = new BufferedInputStream(new FileInputStream(src));
bos = new BufferedOutputStream(new FileOutputStream(dest));
byte[] bs = new byte[1024];
int len;
long start = System.currentTimeMillis();
while((len = bis.read(bs)) != -1){
// 4. 将读取到的数据写入目标文件
bos.write(bs,0,len);
}
bos.flush();
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start));
} catch (IOException exception) {
exception.printStackTrace();
}finally {
if(bos != null){
try {
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(bis != null){
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 节点流按照字节数组复制文件
* @param src 源文件路径
* @param dest 目标文件路径
*/
public static void copyFileByByteArray(String src,String dest){
FileInputStream fis = null;
FileOutputStream fos = null;
try {
// 1. 创建文件字节输入流
fis = new FileInputStream(src);
// 2. 创建文件字节输出流
fos = new FileOutputStream(dest);
// 3. 读取源文件数据
byte[] bs = new byte[8192];
int len;
long start = System.currentTimeMillis();
while((len = fis.read(bs)) != -1){
// 4. 将读取到的数据写入目标文件
fos.write(bs,0,len);
}
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start));
} catch (IOException exception) {
exception.printStackTrace();
}finally {
// 5. 释放资源, 后使用的先关闭
if(fos != null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
BufferedWrite类 — 字符缓冲输出流
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
/**
* BufferedWriter类 - 字符缓冲输出流
* 将文本写入字符输出流,缓冲各个字符,从而提供单个字符、数组和字符串的高效写入。
* 该类提供了 newLine() 方法,写入一个行分隔符。
*
*/
public class Demo01 {
public static void main(String[] args) {
BufferedWriter writer = null;
try {
writer = new BufferedWriter(new FileWriter("D://abc.txt"));
// 单字符写
writer.write('嗨');
writer.newLine(); // 写入一个换行符
// 字符数组写数据
writer.write("你来了!");
writer.newLine();
// 字符串写入
writer.write("那我下班了");
// 注意: 字符流和缓冲流必须flush
writer.flush();
} catch (IOException e) {
e.printStackTrace();
}finally {
if(writer != null){
try {
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
BufferedReader类 — 字符缓冲输入流
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
/**
* BufferedReader类 -- 字符缓冲输入流
* 从字符输入流中读取文本,缓冲各个字符,从而实现字符、数组和行的高效读取。
* String readLine(): 读取一个文本行。
* 包含该行内容的字符串,不包含任何行终止符,如果已到达流末尾,则返回 null
*/
public class Demo02 {
public static void main(String[] args) {
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader("D://abc.txt"));
// 单个字符读取
/*
int b;
while((b = reader.read()) != -1){
System.out.print((char)b);
}
*/
// 字符数组读取
/*
int len;
char[] cs = new char[1024];
while((len = reader.read(cs)) != -1){
System.out.print(new String(cs,0,len));
}
*/
// 按行读取
String line;
while((line = reader.readLine()) != null){
System.out.println(line);
}
} catch (IOException exception) {
exception.printStackTrace();
}finally {
if(reader != null){
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
打印流
一、PrintStream — 字节打印流
二、PrintWrite — 字符打印流
import java.io.*;
/**
* 打印流:
* 打印流只有输出流,没有输入流;也分为字节打印流和字符打印流
* 打印流也是一种包装流
*
* 1. PrintStream-字节打印流
* 构造方法摘要
* PrintStream(File file)
* 创建具有指定文件且不带自动行刷新的新打印流。
* PrintStream(OutputStream out)
* 创建新的打印流。
* PrintStream(OutputStream out, boolean autoFlush)
* 创建新的打印流。
* PrintStream(String fileName)
* 创建具有指定文件名称且不带自动行刷新的新打印流。
*
*
* 2. PrintWriter-字符打印流
* 构造方法摘要
* PrintWriter(File file)
* 使用指定文件创建不具有自动行刷新的新 PrintWriter。
* PrintWriter(OutputStream out)
* 根据现有的 OutputStream 创建不带自动行刷新的新 PrintWriter。
* PrintWriter(OutputStream out, boolean autoFlush)
* 通过现有的 OutputStream 创建新的 PrintWriter。
* PrintWriter(String fileName)
* 创建具有指定文件名称且不带自动行刷新的新 PrintWriter。
* PrintWriter(Writer out)
* 创建不带自动行刷新的新 PrintWriter。
* PrintWriter(Writer out, boolean autoFlush)
* 创建新 PrintWriter。
*
* 与 PrintStream 类不同,如果启用了自动刷新,则只有在调用 println、printf 或 format 的其中一个方法时才可能完成此操作。
*/
public class Deme01 {
public static void main(String[] args) {
// test01();
test02();
}
// PrintWriter
private static void test02() {
PrintWriter writer = null;
try {
// 如果启用了自动刷新,则只有在调用 println、printf 或 format 的其中一个方法时才可能完成此操作
writer = new PrintWriter(new FileWriter("D://out.txt"),true);
writer.print(988);
writer.write("haha");
writer.flush();
} catch (IOException e) {
e.printStackTrace();
}finally {
if(writer != null){
writer.close();
}
}
}
// PrintStream
private static void test01() {
PrintStream ps = null;
/**
* 如果传入的不是字节缓冲输出流,那么autoFlush参数没有意义
*/
try {
ps = new PrintStream(new FileOutputStream("D://ps.txt"));
ps.println(100); // 往文件中写入数据100
/*
* 注意: print打印数据,除了char[]是内容外,其它的所有数组都是地址值
*
*/
int[] nums = {1,2,3};
ps.println(nums);
char[] cs = {'a','1'};
ps.println(cs);
} catch (FileNotFoundException exception) {
exception.printStackTrace();
}finally {
if(ps != null){
ps.close();
}
}
}
}
标准输入&输出流
- 计算机中标准输入设备:键盘;
- 标准输出设备:屏幕。
- 标准输入流作用就是接收键盘输入的数据
- 标准输出流作用就是输出数据到屏幕
System类:
static PrintStream err
//“标准”错误输出流。
static InputStream in
//“标准”输入流。
static PrintStream out
//“标准”输出流。eg:
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; public class Demo02 { public static void main(String[] args) throws IOException { // 接收键盘输入的数据 /** * 使用 System.in 接收键盘输入的数据分析: * 1. System.in是字节流,字节流转中文对我们来说比较麻烦,涉及编码格式。 * 所以字符流操作字符串数据更方便。 * * 2. 字符流有节点流和缓冲流。字节流读取只能单个字符或字符数组读取;缓冲流可以按行读取 * 所以这里使用缓冲流更方便 */ InputStream in = System.in; BufferedReader reader = new BufferedReader(new InputStreamReader(in)); System.out.println("请输入数据:"); String str = reader.readLine(); System.err.println(str); } }
DataOutputStream — 数据输出流
- 数据流:只有字节流没有字符流。
import java.io.DataOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* 数据流: 只有字节流没有字符流
* DataOutputStream - 数据输出流
*
* 数据输出流允许应用程序以适当方式将基本 Java 数据类型写入输出流中。然后,应用程序可以使用数据输入流将数据读入。
*
* DataOutputStream 就数据转成字节(二进制)写入文件。
*
* 序列化: 就是将数据转字节的过程
* 反序列化:将字节转数据的过程
*
* 注意: 数据保存和传输是需要序列化的
*
* 方法摘要
* void writeBoolean(boolean v)
* 将一个 boolean 值以 1-byte 值形式写入基础输出流。
* void writeByte(int v)
* 将一个 byte 值以 1-byte 值形式写出到基础输出流中。
* void writeChar(int v)
* 将一个 char 值以 2-byte 值形式写入基础输出流中,先写入高字节。
* void writeDouble(double v)
* 使用 Double 类中的 doubleToLongBits 方法将 double 参数转换为一个 long 值,然后将该 long 值以 8-byte 值形式写入基础输出流中,先写入高字节。
* void writeFloat(float v)
* 使用 Float 类中的 floatToIntBits 方法将 float 参数转换为一个 int 值,然后将该 int 值以 4-byte 值形式写入基础输出流中,先写入高字节。
* void writeInt(int v)
* 将一个 int 值以 4-byte 值形式写入基础输出流中,先写入高字节。
* void writeLong(long v)
* 将一个 long 值以 8-byte 值形式写入基础输出流中,先写入高字节。
* void writeShort(int v)
* 将一个 short 值以 2-byte 值形式写入基础输出流中,先写入高字节。
* void writeUTF(String str)
* 以与机器无关方式使用 UTF-8 修改版编码将一个字符串写入基础输出流。
*/
public class Demo01 {
public static void main(String[] args) {
DataOutputStream dos = null;
try {
dos = new DataOutputStream(new FileOutputStream("D://data.txt"));
dos.writeByte(97);
dos.writeShort(98);
/**
* writeInt 将int数据按照每一个字节写入,int会写入四个字节
*/
dos.writeInt(99);
dos.writeLong(100);
dos.writeBoolean(true);
dos.writeChar('a');
dos.writeFloat(3.14f);
dos.writeDouble(13.14);
dos.writeUTF("你好啊");
} catch (IOException exception) {
exception.printStackTrace();
}finally {
if(dos != null){
try {
dos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
DataInputStream — 数据输入流
import java.io.DataInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/**
* DataIntputStream - 数据输入流
* 数据输入流允许应用程序以与机器无关方式(因为数据是字节)从底层输入流中读取基本 Java 数据类型。
* 应用程序可以使用数据输出流写入稍后由数据输入流读取的数据。
*
* 方法摘要
*
* boolean readBoolean()
* 参见 DataInput 的 readBoolean 方法的常规协定。
* byte readByte()
* 参见 DataInput 的 readByte 方法的常规协定。
* char readChar()
* 参见 DataInput 的 readChar 方法的常规协定。
* double readDouble()
* 参见 DataInput 的 readDouble 方法的常规协定。
* float readFloat()
* 参见 DataInput 的 readFloat 方法的常规协定。
* int readInt()
* 参见 DataInput 的 readInt 方法的常规协定。
* long readLong()
* 参见 DataInput 的 readLong 方法的常规协定。
* short readShort()
* 参见 DataInput 的 readShort 方法的常规协定。
* String readUTF()
* 参见 DataInput 的 readUTF 方法的常规协定。
*/
public class Demo02 {
public static void main(String[] args) {
DataInputStream dis = null;
try {
dis = new DataInputStream(new FileInputStream("D://data.txt"));
/**
* 注意: 读数据和写数据的顺序必须一致。否则数据就是错的
*/
System.out.println(dis.readByte());
System.out.println(dis.readShort());
System.out.println(dis.readInt());
System.out.println(dis.readLong());
System.out.println(dis.readBoolean());
System.out.println(dis.readChar());
System.out.println(dis.readFloat());
System.out.println(dis.readDouble());
System.out.println(dis.readUTF());
} catch (IOException exception) {
exception.printStackTrace();
}finally {
if(dis != null){
try {
dis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
DAY23
对象流
对象流只有字节流,没有字符流
import java.io.FileOutputStream; import java.io.IOException; import java.io.ObjectOutputStream; /** * 对象流 * 对象流只有字节流,没有字符流 * * 1. ObjectOutputStream类:-- 对象序列化流 * ObjectOutputStream 将 Java 对象的基本数据类型和图形写入 OutputStream。 * 可以使用 ObjectInputStream 读取(重构)对象。 * 通过在流中使用文件可以实现对象的持久存储。 * 如果流是网络套接字流,则可以在另一台主机上或另一个进程中重构对象。 * * 之前我们学习的数据流只能序列化基本数据类型和String。但是java中操作基本上是对象,所以需要将对象存储或传输。 * 对象持久存储和传输也是需要序列化的,对象要序列化就需要使用对象序列化流-ObjectOutputStream * * void writeObject(Object obj) * 将指定的对象写入 ObjectOutputStream。 * * ObjectOutputStream类只能将支持 java.io.Serializable 接口的对象写入流中。 * 每个 serializable 对象的类都被编码,编码内容包括类名和类签名、对象的字段值和数组值,以及从初始对象中引用的其他所有对象的字段。 * * 序列化:数据转字节存储或传输的过程 * 反序列化:将传输或存储的字节转数据的过程 * * 2. ObjectInputStream类:-- 对象反序列化流 * ObjectInputStream 对以前使用 ObjectOutputStream 写入的基本数据和对象进行反序列化。 * * Object readObject() * 从 ObjectInputStream 读取对象 * */ public class Demo01 { public static void main(String[] args) { ObjectOutputStream oos = null; try { Student student1 = new Student("张三", 20, "男"); Student student2 = new Student("lisi", 21, "女"); oos = new ObjectOutputStream(new FileOutputStream("D://student.dat")); // 将student对象持久化存储 -- 序列化 /* * java.io.NotSerializableException: com.powernode.p1.Student * 对象序列化必须实现序列化Serializable接口,否则抛出没有序列化的异常:NotSerializableException * */ oos.writeObject(student1); oos.writeObject(student2); } catch (IOException e) { e.printStackTrace(); }finally { if(oos != null){ try { oos.close(); } catch (IOException e) { e.printStackTrace(); } } } } }
ObjectInputStream类 — 对象反序列化流
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
/**
* 演示: ObjectInputStream类:-- 对象反序列化流
*
* 无效的类异常:
* java.io.InvalidClassException: com.powernode.p1.Student; local class incompatible:
* stream classdesc serialVersionUID = 6018961234229396208, local class serialVersionUID = -4306986026975680102
* 原因: 因为本地类序列化过后,修改了字段的修饰符,所以反序列化流中的UID和本地类的UID不一致,所以认为这不是同一个类,也就是类不兼容了。所以出错
* 解决方法:就是把serialVersionUID固定。无论类中的成员变量如何修改,serialVersionUID值都不发生变化就可以。
* 如何把serialVersionUID固定,就是在需要序列化的类中显式的添加一个serialVersionUID字段。
*
*
* 结论:
* 1. 对象序列化和反序列化的serialVersionUID必须一样
* 2. 实现Serializable接口的类,推荐显式的指定serialVersionUID字段的值
*
*/
public class Demo02 {
public static void main(String[] args) {
ObjectInputStream ois = null;
try {
ois = new ObjectInputStream(new FileInputStream("D://student.dat"));
// 对象反序列化
Object obj = ois.readObject();
System.out.println(obj);
Object obj1 = ois.readObject();
System.out.println(obj1);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}finally {
if(ois != null){
try {
ois.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
Serializable接口
- Serializable接口只有接口的定义,没有任何的成员。这样的接口叫做标记接口。
- 作用:仅仅用作标记
- Student类实现了Serializable接口,你就可以理解成Student类有了序列化的标记。其实是对象流在序列化的时候会判断类是不是属于Serializable类型,如果不是就会抛出java.io.NotSerializableException
- 如果类中某个字段不想被序列化,如何处理?
- 序列化的目的是持久存储或传输。那么如果一个字段不能被持久化,那么这个字段就不能序列化了。所以java提供了一个关键字:transient,表示短暂的,瞬间的。
- 被transient关键字修饰的字段,就是瞬态字段,不能被序列化。静态字段属于类,不属于对象,所以静态字段也不能序列化。
- eg:
import java.io.Serializable;
public class Student implements Serializable {
private static final long serialVersionUID = 6018961234229396208L;
private String name;
private transient int age;
static String sex;
public Student() {
}
public Student(String name, int age, String sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", sex='" + sex + '\'' +
'}';
}
}
内存流(字节数组流)
import java.io.ByteArrayOutputStream;
import java.io.IOException;
/**
* 内存流(字节数组流)
* ByteArrayOutputStream -- 熟悉
* ByteArrayInputStream -- 了解
*
* 前面我们学习的流的源和目的地是: 文件
* 内存流的源和目的地是:内存
*
* ByteArrayOutputStream:字节数组输出流
* 输出流是将程序的数据写到目的地,所以:
* ByteArrayOutputStream的作用:将数据写入内存中
* ByteArrayInputStream的作用: 读取内存中写入的数据
*
* ByteArrayOutputStream类:
* 此类实现了一个输出流,其中的数据被写入一个 byte 数组。缓冲区会随着数据的不断写入而自动增长。
* 可使用 toByteArray() 和 toString() 获取数据。
*
* 扩容最大限制:Integer.MAX_VALUE - 8 ; 最大2G的数据
*
* 关闭 ByteArrayOutputStream 无效。此类中的方法在关闭此流后仍可被调用,而不会产生任何 IOException。
*
* 构造方法摘要
* ByteArrayOutputStream()
* 创建一个新的 byte 数组输出流。
* ByteArrayOutputStream(int size)
* 创建一个新的 byte 数组输出流,它具有指定大小的缓冲区容量(以字节为单位)。
*/
public class Demo01 {
public static void main(String[] args) {
// ByteArrayOutputStream写数据的目的地是内存,所以没有路径一说
ByteArrayOutputStream baos = null;
baos = new ByteArrayOutputStream();
try {
// 写数据到内存中
baos.write("我爱你,中国".getBytes());
// 使用 toByteArray() 和 toString() 获取数据。
String str = baos.toString();
System.out.println(str);
} catch (IOException e) {
e.printStackTrace();
}
}
}
eg:将图片数据读取后存储到内存中,图片读取完成后获取出内存中的数据
import java.io.*;
import java.util.Arrays;
/**
* 需求: 就是将图片数据读取后存储到内存中,图片读取完成后获取出内存中的数据
*/
public class Demo02 {
public static void main(String[] args) {
BufferedInputStream bis = null;
ByteArrayOutputStream baos = null;
try {
bis = new BufferedInputStream(new FileInputStream("D://img.jpeg"));
baos = new ByteArrayOutputStream();
// 读数据
int len;
byte[] bs = new byte[1024];
while((len = bis.read(bs)) != -1){
// 将读取的数据写入内存 -- 使用内存流写入
baos.write(bs,0,len);
}
// 图片读取完成后获取出内存中的数据
byte[] imgBytes = baos.toByteArray();
System.out.println(Arrays.toString(imgBytes));
} catch (IOException exception) {
exception.printStackTrace();
}finally {
if(bis != null){
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
复制多级文件夹
import java.io.*;
/**
* 复制多级文件夹
* 步骤:
* 1. 判断是文件还是文件夹
* 文件: 直接复制
* 文件夹:
* a. 创建文件夹
* b. 获取并遍历文件夹下的内容
* c. 回到1
*
*/
public class CopyFloderDemo {
public static void main(String[] args) {
File src = new File("D://a");
File dest = new File("E://");
copyFloder(src,dest);
}
/**
* 复制多级文件夹
* @param src 源文件夹
* @param dest 目标文件夹
*/
public static void copyFloder(File src, File dest){
// 增加代码的健壮性
if(src == null || dest == null){
return;
}
if(!src.exists() || !dest.exists()){
return;
}
// 1. 判断是文件还是文件夹
// src = D://a.txt dest = E://
if(src.isFile()){
// 文件: 直接复制
// 要求目标文件的路径 = E://a.txt,所以需要重写创建File
// 获取源文件的名称
String fileName = src.getName();
// newFile = E://a.txt
File newFile = new File(dest,fileName);
copyFile(src,newFile);
}else{ // 文件夹
// src = D://a/ dest = E://
// a. 创建文件夹
// 获取源文件夹的名字
String floderName = src.getName();
// newFloder = E://a/
File newFloder = new File(dest,floderName);
// 创建文件夹
newFloder.mkdir();
// b. 获取并遍历文件夹下的内容
// src = D://a/ files就是D://a/下的内容
File[] files = src.listFiles();
for (File file : files) {
// file = D://a/a.txt -- 复制到 E://a/
copyFloder(file,newFloder);
}
}
}
/**
* 复制文件
* @param src 源文件
* @param dest 目标文件
*/
private static void copyFile(File src,File dest){
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
bis = new BufferedInputStream(new FileInputStream(src));
bos = new BufferedOutputStream(new FileOutputStream(dest));
int len;
byte[] bs = new byte[1024];
while((len = bis.read(bs)) != -1){
bos.write(bs,0,len);
}
bos.flush();
} catch (IOException exception) {
exception.printStackTrace();
}finally {
if(bos != null){
try {
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(bis != null){
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
Properties类
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Properties;
/**
* Properties类
* 1. Properties类是属于集合,叫做属性集
* 2. Properties类是Hashtable的子类,所以存储的数据也是kv格式
* 3. Properties类中的key和value只能是String类型
* 4. Properties 类是一个持久的属性集,Properties可保存在流中或从流中加载。
*
* 构造方法摘要
* Properties()
* 创建一个无默认值的空属性列表。
*
*
* 常用方法:
* 1. 操作属性:
* String getProperty(String key)
* 用指定的键在此属性列表中搜索属性。
* String getProperty(String key, String defaultValue)
* 用指定的键在属性列表中搜索属性。
* Object setProperty(String key, String value)
* 调用 Hashtable 的方法 put。
*
* 2. 持久化方法,将数据保存到文件中
* void store(OutputStream out, String comments)
* 以适合使用 load(InputStream) 方法加载到 Properties 表中的格式,将此 Properties 表中的属性列表(键和元素对)写入输出流。
* void store(Writer writer, String comments)
* 以适合使用 load(Reader) 方法的格式,将此 Properties 表中的属性列表(键和元素对)写入输出字符。
*
* 3. 读取持久化的数据
* void load(InputStream inStream)
* 从输入流中读取属性列表(键和元素对)。
* void load(Reader reader)
* 按简单的面向行的格式从输入字符流中读取属性列表(键和元素对)。
*/
public class Demo01 {
public static void main(String[] args) throws IOException {
// 创建属性集对象
Properties prop = new Properties();
// 设置属性
prop.setProperty("name","张三");
prop.setProperty("age","20");
prop.setProperty("sex","男");
/*
* 将属性集持久化:(Writer writer, String comments)
* 第二个参数是 文件的注释信息
* properties文件的注释格式是: # 注释文字
*
* 属性集有字节的文件格式,扩展名是 .properties
* 数据格式是 key=value
*
*/
prop.store(new FileWriter("day23/user.properties"),"用户的信息");
// 读取properties文件的数据
Properties prop01 = new Properties();
// 将文件数据加到到Properties属性集中
prop01.load(new FileReader("day23/user.properties"));
// 获取属性,如果属性不存在就返回null
// String name = prop01.getProperty("name");
/*
* getProperty(String key, String defaultValue)
* 如果属性存在就返回对应的值;如果属性不存在就返回默认值defaultValue
*/
String name = prop01.getProperty("name1","不存在");
System.out.println(name);
}
}
自己封装一个IO的工具类
import java.io.*;
/**
* 自己封装一个IO的工具类
* 1. 文件复制的方法
* 2. 文件夹复制的方法
* 3. 关闭资源的方法
*/
public class IOUtils {
private IOUtils(){
}
/**
* 复制多级文件夹
* @param src 源文件夹
* @param dest 目标文件夹
*/
public static void copyFloder(File src, File dest){
// 增加代码的健壮性
if(src == null || dest == null){
return;
}
if(!src.exists() || !dest.exists()){
return;
}
// 1. 判断是文件还是文件夹
// src = D://a.txt dest = E://
if(src.isFile()){
// 文件: 直接复制
// 要求目标文件的路径 = E://a.txt,所以需要重写创建File
// 获取源文件的名称
String fileName = src.getName();
// newFile = E://a.txt
File newFile = new File(dest,fileName);
copyFile(src,newFile);
}else{ // 文件夹
// src = D://a/ dest = E://
// a. 创建文件夹
// 获取源文件夹的名字
String floderName = src.getName();
// newFloder = E://a/
File newFloder = new File(dest,floderName);
// 创建文件夹
newFloder.mkdir();
// b. 获取并遍历文件夹下的内容
// src = D://a/ files就是D://a/下的内容
File[] files = src.listFiles();
for (File file : files) {
// file = D://a/a.txt -- 复制到 E://a/
copyFloder(file,newFloder);
}
}
}
/**
* 复制文件
* @param src 源文件
* @param dest 目标文件
*/
public static void copyFile(File src,File dest){
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
bis = new BufferedInputStream(new FileInputStream(src));
bos = new BufferedOutputStream(new FileOutputStream(dest));
int len;
byte[] bs = new byte[1024];
while((len = bis.read(bs)) != -1){
bos.write(bs,0,len);
}
bos.flush();
} catch (IOException exception) {
exception.printStackTrace();
}finally {
close(bos,bis);
}
}
/**
* 释放资源
* @param closeables 需要关闭的流
*/
public static void close(AutoCloseable ... closeables){
if(closeables != null){
for (AutoCloseable closeable : closeables) {
try {
closeable.close();
} catch (Exception exception) {
exception.printStackTrace();
}
}
}
}
}
线程引入
学习线程之前需要先掌握几个概念:
程序(Application):是计算机能识别和执行的指令。是一个静态的概念。
- 静态的意思就是:没有运行。
进程(Process):运行中的程序。是一个动态的概念。
- 程序运行后就是进程,进程是一个动态的概念;
- 一个程序至少要有一个进程;
- 程序运行后,需要将程序的指令交给CPU处理;数据需要加载到内存中;
- 程序中的指令是谁交给cpu处理的呢? — 就是线程
线程(Thread):线程就是进程的执行路径,作用就是将程序指令交给cpu执行。
- 一个进程至少需要一个线程。线程将指令交给cpu执行,是需要抢占到cpu的时间片才能执行的。
- cpu的一个核心执行一个线程。
线程和进程的区别
- 进程是运行中的程序,是计算机中分配资源的最小单位。
- 线程是进程的执行路径,线程是在进程中的。线程是程序执行的最小单位。
多线程
- 一个程序有多个执行路径,那么这个程序就是多线程的程序。
- eg:迅雷下载、QQ、LOL、等都是多线程的。
串行:多个线程排队执行,效果类似于单线程。
并发:多个线程交替执行,会竞争资源。
并行:同一时间点多个线程同时执行。一般并行中都带有并发。

单核cpu是没有并行的
- 假设我们现在的计算机是一个单核的cpu,现在运行了多个程序,比如QQ、迅雷、游戏,那么这些程序是同时在执行吗?
- –> 其实不是同时运行的,他们会抢占cpu的时间片资源,抢到了就执行。但是因为cpu的时间片切换是毫秒级的,这个毫秒值很少,人为是感知不到的,所以感觉是同时执行的。
- –> 微观:不是同时运行的。
- –> 宏观:同时运行的。
- 假设我们现在的计算机是一个单核的cpu,现在运行了多个程序,比如QQ、迅雷、游戏,那么这些程序是同时在执行吗?
eg:
public class Demo01 { public static void main(String[] args) { /** * 以下的代码执行顺序是: 现将第一个循环全部执行完成后才执行第二个循环 * * 现在需要实现 边听音乐边玩游戏。 目前这个需求做不到,要完成这个需求就必须使用多线程的技术。 * * 线程是: 代码的执行路径 * * 我们之前所写的所有代码都只有一个执行路径,是单线程的程序。 */ for (int i = 0; i < 10; i++) { System.out.println("正在听音乐....."+ i); } for (int i = 0; i < 10; i++) { System.out.println("正在玩游戏............." + i); } } }
创建线程的方式一【继承Thread】
/**
* 创建线程:
* java中使用Thread类表示线程。
* 注意: 只有Thread类及其子类才能叫做线程类
*
* 创建线程的方式一:
* 1. 创建Thread的子类
* 2. 子类重写run()方法
* 3. 创建子类对象并启动
*
*/
// 1. 创建Thread的子类
class MyThread extends Thread{
// 2. 子类重写run()方法
/**
* run()方法是线程启动后,系统自动调用的方法。不是程序员调用的。
* run()方法就是线程启动后,执行的方法,所以将需要交给线程执行的代码编写在这个方法中
*/
@Override
public void run() {
// 线程执行的代码
for (int i = 0; i < 10; i++) {
System.out.println("正在听音乐....."+ i);
}
}
}
public class Demo02 {
/**
* java程序的main()是主线程运行的,主线程就是main线程。
* main线程是系统自动创建。
*
* 如果在线程A中启动了线程B,线程B叫做线程A的子线程
*/
public static void main(String[] args) {
// 3. 创建子类对象并启动
MyThread myThread = new MyThread();
myThread.start(); // 启动线程,线程启动后会执行run()方法
// 主线程执行的
for (int i = 0; i < 10; i++) {
System.out.println("正在玩游戏............." + i);
}
}
}

创建线程的方式二【创建Runnable接口的实现类】
/**
* 创建线程的方式二:
* 1. 创建 Runnable 接口的实现类
* 2. 实现类重写 run() 方法
* 3. 创建Thread时将实现类对象作为参数传递,启动Thread
*
*
* 创建线程的方式一和方式二比较:
* 1. 方式一使用继承Thread的方式
* a. 如果类已经继承了其它类,就不能使用方式一,受java单继承的限制
* b. 方法使用Thread的方法
*
* 2. 方式二使用实现Runnable的方式
* a. 不受java单继承的限制
* b. 使用Thread的方法相对会麻烦一些
*
*
* 创建线程的方式三稍后再讲
*/
// 1. 创建 Runnable 接口的实现类
/**
* Runnable的实现类不是线程类。
* Runnable的实现类是线程的任务类,也就说Runnable中编写的是线程执行的代码
*/
class MyRunnable implements Runnable{
// 2. 实现类重写 run() 方法
/**
* run()是线程执行的方法,也就是说run()方法编写线程执行的代码
*/
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println("正在听歌曲....."+ i);
}
}
}
public class Demo03 {
public static void main(String[] args) {
// 3. 创建Thread时将实现类对象作为参数传递,启动Thread
MyRunnable myRunnable = new MyRunnable();
Thread t1 = new Thread(myRunnable);
t1.start();
}
}
Thread类
/**
* Thread类:
*
* 1.构造方法摘要
* Thread()
* 分配新的 Thread 对象。
* Thread(Runnable target)
* 分配新的 Thread 对象。
* Thread(Runnable target, String name)
* 分配新的 Thread 对象。
* Thread(String name)
* 分配新的 Thread 对象。
*
* 2. 常用方法:
* void start()
* 使该线程开始执行;Java 虚拟机调用该线程的 run 方法。
* 多次启动一个线程是非法的。特别是当线程已经结束执行后,不能再重新启动。
*
* String getName()
* 返回该线程的名称。
*
* void setName(String name)
* 改变线程名称,使之与参数 name 相同。
* 设置线程的名称有两种方式:一种通过构造函数;一种通过setName()
*
* static Thread currentThread()
* 返回对当前正在执行的线程对象的引用。
* 整个代码在哪个线程中调用,就会返回哪个线程
*
* long getId()
* 返回该线程的标识符。
*/
public class Demo04 {
public static void main(String[] args) {
// test01();
test02();
}
// getName(),getId()
private static void test02() {
// 设置线程的名称有两种方式:一种通过构造函数;一种通过setName()
/* Thread t1 = new Thread("线程1"){
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(getName()+"---" + i);
}
}
};*/
Thread t1 = new Thread(){
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(getName()+"---" + i);
}
}
};
t1.setName("线程a");
t1.start();
// 获取线程的id
System.out.println("t1线程的id= " + t1.getId());
// 获取主线程的名称
String name = Thread.currentThread().getName();
System.out.println("name== " + name);
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName()+"=========" + i);
}
}
// start()方法
private static void test01() {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println("线程开始执行......");
}
}
});
/**
* t1.start() 是启动一个新的线程,然后 run()中的代码在新的线程中执行的
* t1.run() 这是调用了t1对象的成员run()方法,不会启动线程;run()中的代码在主线程执行
*/
t1.start();
// t1.run();
for (int i = 0; i < 10; i++) {
System.out.println("main......");
}
}
}
Thread常用方法
/**
* Thread常用方法:
* 1. 线程睡眠:
* static void sleep(long millis)
* 在指定的毫秒数内让当前正在执行的线程休眠(暂停执行).
*
* 2. 加入线程
* void join()
* 等待该线程终止。
* void join(long millis)
* 等待该线程终止的时间最长为 millis 毫秒。
*
* 建议: join()放在start()后
*
* 3. 后台线程(守护线程)
* void setDaemon(boolean on)
* 将该线程标记为守护线程或用户线程。当正在运行的线程都是守护线程时,Java 虚拟机退出。
* 该方法必须在启动线程前调用。
* 创建出来的线程默认就是用户线程,通过setDaemon(true)就可以将用户线程变成守护线程
*
* boolean isDaemon()
* 测试该线程是否为守护线程。
*
* 4. 礼让线程 -- 开发中基本没有使用,面试中会见到
* static void yield()
* 给调度程序的一个提示,当前线程愿意让出当前的处理器的使用。调度程序可以自由地忽略这个提示。
* 作用: yield是一个启发式的尝试,以改善线程之间的相对进展,否则将过度使用一个中央处理器。
* 使用这种方法是不恰当的。它可能是有用的调试或测试的目的。
*
* 5. 线程优先级
* int getPriority()
* 返回线程的优先级
* void setPriority(int newPriority)
* 更改线程的优先级。
*
* 注意: 线程默认的优先级是5
* public final static int MIN_PRIORITY = 1;
* public final static int NORM_PRIORITY = 5;
* public final static int MAX_PRIORITY = 10;
*
* 在cpu资源充足的情况下,设置优先级没有效果;在资源不足的情况下,优先级高的线程获取到资源的几率大一点。
*/
public class Demo05 {
public static void main(String[] args) {
// test01();
// test02();
// test03();
// test04();
// test05();
test06();
}
// 线程优先级
private static void test06() {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 20; i++) {
System.out.println(Thread.currentThread().getName() + "---" + i);
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
},"线程1");
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 20; i++) {
System.out.println(Thread.currentThread().getName() + "===========" + i);
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
},"线程2");
// 更改线程的优先级
t1.setPriority(10);
t2.setPriority(1);
t1.start();
t2.start();
System.out.println("t1的优先级:"+ t1.getPriority());
System.out.println("t2的优先级:"+ t2.getPriority());
}
// 礼让线程
private static void test05() {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 20; i++) {
System.out.println(Thread.currentThread().getName() + "---" + i);
try {
Thread.sleep(200);
/*
* yield()
* 1. 表示愿意让出cpu资源,但是调度程序可以自由地忽略这个提示
* 2. 即使让出cpu资源,也会继续参与抢占,但是可以改善线程之间的相对进展,否则将过度使用一个中央处理器。
*
*/
Thread.yield();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
},"线程1");
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 20; i++) {
System.out.println(Thread.currentThread().getName() + "===========" + i);
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
},"线程2");
t1.start();
t2.start();
}
// 后台线程(守护线程)
private static void test04() {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 20; i++) {
System.out.println(Thread.currentThread().getName() + "---" + i);
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
},"线程1");
/*
* t1.setDaemon(true); 将t1线程设置成守护线程。
* 问题: 守护线程守护的是谁??
* 守护所有的用户线程
* 当程序中只剩下守护线程,jvm就会退出。
*
*/
t1.setDaemon(true);
t1.start();
// main线程是用户线程
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "===========" + i);
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
// 加入线程
private static void test03() {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "---" + i);
}
}
},"线程1");
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
try {
t1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "===============" + i);
}
}
},"线程2");
t1.start();
t2.start();
}
// 加入线程
/**
* 需求: t1线程执行完后再执行主线程的循环语句
*/
private static void test02() {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "---" + i);
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
},"线程1");
t1.start();
try {
/*
* join()方法编写在哪一个线程中,哪一个线程就有阻塞,直到调用join()方法
* 的线程执行完后,这个线程才能继续向下执行
*
* 所以:这里的join()方法编写在main线程中的,所以主线程会阻塞,直到t1线程执行完成后
* 主线程才会继续执行。
* 这里使用join达到了串行的效果。
*
* join() == join(0)
*/
// t1.join();
/*
* join(long millis): 等待该线程终止的时间最长为 millis 毫秒。
* t1.join(1)表示的意思是:
* 1. 到了指定的时间,t1还没有执行完成,主线程也不会阻塞了, 会继续向下执行
* 2. t1执行完成了,但是还没有到指定的时间,主线程也不会阻塞了, 会继续向下执行
*
*/
t1.join(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 主线程
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "========" + i);
}
}
// 线程睡眠
private static void test01() {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "--" + i);
/**
* sleep()在哪一个线程中调用,哪一个线程就睡眠
*/
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
t1.start();
}
}
线程的内存
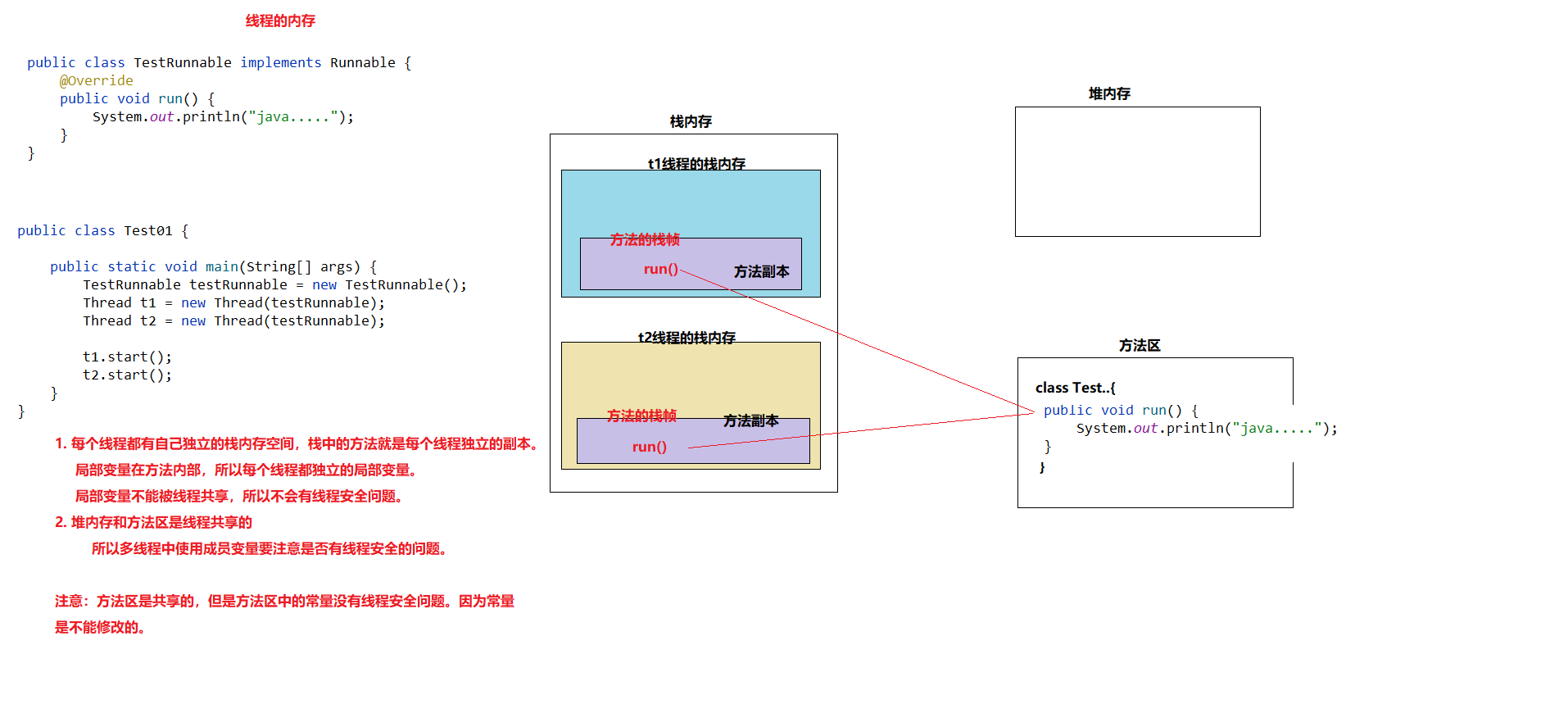
DAY24
中断线程
/**
* 中断线程
* void interrupt()
* 中断线程。
* 如果线程在调用 Object 类的 wait()、wait(long) 或 wait(long, int) 方法,
* 或者该类的 join()、join(long)、join(long, int)、sleep(long) 或 sleep(long, int) 方法过程中受阻,则其中断状态将被清除,
* 它还将收到一个 InterruptedException。
* 注意: interrupt()只是给线程设置了一个中断标记。不会中断线程。
* 如果需要中断线程,需要程序员获取到中断标记后,自己处理。
*
* static boolean interrupted()
* 测试当前线程是否已经中断。
* 测试当前线程是否已经中断。线程的中断状态 由该方法清除。换句话说,如果连续两次调用该方法,则第二次调用将返回 false(在第一次调用已清除了其中断状态之后,且第二次调用检验完中断状态前,当前线程再次中断的情况除外)。
* boolean isInterrupted()
* 测试线程是否已经中断。线程的中断状态 不受该方法的影响。
*
*
*/
/**
* 实现自然排序
*/
class Worker implements Comparable<Worker> {
private int id;
private String name;
private int age;
public Worker() {
}
public Worker(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Worker{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
/**
* 比较方法
* 比较对象一个是this,一个是参数
*/
@Override
public int compareTo(Worker o) {
/*
* 编写比较规则,注意主要条件和辅助条件
* 主要条件就是需求中给出来的条件,这里就是 按照员工的年龄升序
* 辅助条件需要自己找,怎么找?
* 辅助条件的作用是用来区分不同的对象,所以找能够区分不同对象的字段所谓辅助条件
* 这里id应该就是唯一的,所以可以用来做辅助条件。
*
* 注意: 如果一个字段不能区分唯一性,可以使用多个字段来区分
*
* 所以编写比较规则的时候,先比较主要条件,当主要条件的结果是0的时候,再次比较辅助条件。
*
*/
// 先比较主要条件
int a = this.age - o.age;
// 当主要条件的结果是0的时候,再次比较辅助条件。
if(a == 0){
return this.id - o.id;
}
return a;
}
}
public class Demo01 {
static boolean bool = true;
public static void main(String[] args) {
// test01();
test02();
}
private static void test02() {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
while(bool){ //这种采用bool来中断线程的方法不好,建议使用interrupt()
System.out.println(Thread.currentThread().getName()+"正在执行");
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
t1.setName("线程1");
t1.start();
// 主线程: 停止t1线程
for (int i = 0; i < 10; i++) {
if(i == 5){
// 停止t1线程
bool = false;
}
System.out.println(Thread.currentThread().getName() + "--==========-" + i);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
// interrupt() 中断线程
private static void test01() {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
while(true){
// 判断当前线程是否有中断状态
/* if(Thread.currentThread().isInterrupted()){
break;
}*/
if(Thread.interrupted()){
break;
}
System.out.println(Thread.currentThread().getName()+"正在执行");
try {
/*
* sleep(),wait(),join()方法会清除中断状态
*/
Thread.sleep(500);
} catch (InterruptedException e) {
/**
* 因为中断状态被清除了,所以这里再次设置线程中断的状态
*/
Thread.currentThread().interrupt();
e.printStackTrace();
}
}
}
});
t1.setName("线程1");
t1.start();
// 主线程: 停止t1线程
for (int i = 0; i < 10; i++) {
if(i == 5){
// 停止t1线程
t1.interrupt(); // 仅仅是给t1线程设置了一个中断标记
}
System.out.println(Thread.currentThread().getName() + "--==========-" + i);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
同步机制【synchronized】
/**
* 多线程程序会出现线程安全问题。
*
* 线程不安全:多线程执行代码的结果和单线程执行结果不一致。
*
* 线程不安全的前提条件:
* 1. 必须是多线程
* 2. 多线程必须共享数据
* 3. 多个线程对共享数据进行修改
*
* 线程不安全的原因:
* 一个线程操作共享数据的时候,共享数据还没有操作完成,就被其它线程抢过去操作共享数据;这就会造成线程不安全。
*
* 解决线程不安全的思路:
* 线程在操作共享数据代码的时候,不允许其它线程进来操作共享数据。
*
* java提供了同步机制synchronized解决线程不安全的问题:
* synchronized是java的关键字,表示同步。
*
* java的同步机制分为:
* 1. 同步代码块
* synchronized(对象锁){
* 操作共享数据的代码;
* }
*
* 同步代码块的对象锁是: 任意对象
* 但是要保证: 多个对象是同一个对象锁
*
* 2. 同步方法
* 修饰符 synchronized 返回值类型 方法名(参数列表){
* 操作共享数据的代码;
* }
* 同步方法
* * 1. 同步方法需要方法结束才能释放锁
* * 2. 建议 方法中的代码全部是操作共享数据的的,此时才推荐使用同步方法
* * 3. 同步方法的对象锁是:this
*
* 3. 同步静态方法
* 修饰符 static synchronized 返回值类型 方法名(参数列表){
* 操作共享数据的代码;
* }
*
* 同步静态方法的对象锁:字节码对象 (类名.class)
*
* 被synchronized修饰的代码就具备了原子性。
* 原子性:就是代码是一个整体,线程要么全部执行完成,要么一句都不执行;不能一个线程执行一部分,另一个线程又进来执行一部分。
*
* 同步:多个线程执行时,线程是阻塞的,需要得到前一个线程的结果,另一个线程才能执行。 效率低
* 异步:多个线程执行时,非阻塞的,不需要等到前面的结果。效率高
*
*/
/**
* 卖票的线程类
* 该类的功能: 卖10张票
*/
class SaleTicketThread extends Thread{ //一、采用继承Thread的方法
// 票的数量--多个对象共享
private static int ticketNum = 10;
private static Object obj = new Object();
// t1 t2
@Override
public void run() {
// 模拟窗口一直开着,只要有票就可以卖
while(true){
/**
* synchronized(对象锁)
* 对象锁: 就是用一个对象来作为锁
* 锁: 就相当于生活中的锁,现在给代码加锁
* 多个线程必须使用同一个锁
*/
// t1 获取锁 t2 获取锁失败
synchronized (obj){
// 有票才卖票
if(ticketNum > 0){
// t1 输出10 还没有做自减 t2抢到cpu t1抢到后继续执行 ticketNum = 9
System.out.println(Thread.currentThread().getName()+"卖第" + (ticketNum--) +"票");
}
} // 释放锁 t1 t2 t3可以获取锁
// 模拟卖票的延迟
/**
* 线程中使用睡眠,线程暂停,直到睡醒继续执行
* 多线程运行结果有问题,不是线程睡眠造成的
*/
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class TicketDemo {
public static void main(String[] args) {
// 创建三个窗口卖票线程
SaleTicketThread t1 = new SaleTicketThread();
SaleTicketThread t2 = new SaleTicketThread();
SaleTicketThread t3 = new SaleTicketThread();
t1.setName("窗口1");
t2.setName("窗口2");
t3.setName("窗口3");
t1.start();
t2.start();
t3.start();
}
}
采用实现Runnable接口的方法
/** * 窗口线程的任务类 * 任务: 卖票 */ class SaleTicketRunnable implements Runnable { //二、实现Runnable接口的方法 // 票的数量--多个对象共享 private /*static*/ int ticketNum = 10; @Override public void run() { while (true) { saleTicket(); // saleTicket01(); try { Thread.sleep(200); } catch (InterruptedException e) { e.printStackTrace(); } } } /** * 同步方法 * 1. 同步方法需要方法结束才能释放锁 * 2. 建议 方法中的代码全部是操作共享数据的的,此时才推荐使用同步方法 * 3. 同步方法的对象锁是:this */ public synchronized void saleTicket() { // 有票才卖票 if (ticketNum > 0) { System.out.println(Thread.currentThread().getName() + "卖第" + (ticketNum--) + "票"); } } // /** // * 同步静态方法的对象锁:字节码对象 (类名.class) // */ // public static synchronized void saleTicket01() { // // 有票才卖票 // if (ticketNum > 0) { // System.out.println(Thread.currentThread().getName() + "卖第" + (ticketNum--) + "票"); // } // } } public class Demo01 { public static void main(String[] args) { SaleTicketRunnable runnable = new SaleTicketRunnable(); Thread t1 = new Thread(runnable,"窗口1"); Thread t2 = new Thread(runnable,"窗口2"); Thread t3 = new Thread(runnable,"窗口3"); t1.start(); t2.start(); t3.start(); } }
synchronized特点
/**
* synchronized的特点:
* 1. synchronized是一个不公平锁
* 公平锁:按照进入阻塞队列的先后顺序获取锁
* 不公平锁:不管先后顺序,释放锁之后大家一起抢
*
* 2. synchronized是一个可重入锁
* 在使用synchronized时,当一个线程得到一个对象锁后(只要该线程还没有释放这个对象锁),
* 再次请求此对象锁时是可以再次得到该对象的锁的。
*
* 可重入锁也支持在父子类继承的环境中。当存在父子类继承关系时,
* 子类是完全可以通过“可重入锁”调用父类的同步方法。
*
* 3. 同步方法重写的要求
* 子类重写父类的同步方法,子类重写的方法可以为非同步方法。
*/
/**
* 演示:synchronized是一个可重入锁
*/
class MyRunnable implements Runnable{
@Override
public void run() {
method01();
}
// t1 获取this锁
private synchronized void method01() {
System.out.println("method01-------------");
method02();
} // 释放this锁
// t1 再次获取this锁
private synchronized void method02() {
System.out.println("method02-------------");
}// 释放再次获取的this锁
}
public class Demo01 {
public static void main(String[] args) {
Thread t1 = new Thread(new MyRunnable());
t1.start();
}
}
死锁
/**
* 死锁:多个线程相互持有彼此的锁,造成线程全部阻塞。
* 也就是: 当A线程等待B线程释放资源,而同时B又在等待A线程释放资源,这就形成了死锁。
*
*/
public class DieLockDemo {
static Object obj01 = new Object();
static Object obj02 = new Object();
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
/*
* t1线程执行,获取obj01
*/
synchronized (obj01){
System.out.println("t1开始执行。。。。。");
/*
* obj02被t2获取了还未释放
*/
synchronized (obj02){
System.out.println("t1得到obj02。。。。。");
}
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
/*
* t2线程执行,获取obj02
*/
synchronized (obj02){
System.out.println("t2开始执行。。。。。");
/*
* obj01被t1获取了还未释放
*/
synchronized (obj01){
System.out.println("t1得到obj01。。。。。");
}
}
}
});
t1.start();
t2.start();
}
}
线程间的通信“等待唤醒机制”
/**
* 线程间的通信:
* 线程间通信使用“等待唤醒”机制。
*
* 等待: wait()
* 唤醒: notify()/notifyAll()
*
* 问题1: wait()和notify()/notifyAll()方法是操作线程的,为什么没用定义在Thread类中;而是定义在Object类中?
* 因为 wait()和notify()/notifyAll()方法必须是 对象锁调用,而对象锁可以是任意对象。
* 所以当一个方法能够被任意对象调用,那么这个方法一定是Object类的方法。
*
* Object类:
* void wait()
* 在其他线程调用此对象的 notify() 方法或 notifyAll() 方法前,导致当前线程等待。
* void wait(long timeout)
* 在其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者超过指定的时间量前,导致当前线程等待。
* void notify()
* 唤醒在此对象监视器上等待的单个线程。
* void notifyAll()
* 唤醒在此对象监视器上等待的所有线程。
*
* 注意:
* 1. wait()和notify()/notifyAll()方法必须是对象锁调用
* 2. wait()和notify()/notifyAll()方法只能编写在synchronized代码中
* 3. wait() == wait(0) : 线程阻塞,直到线程被唤醒才能继续往下执行
* 4. wait(long timeout): 线程阻塞,当调用了唤醒后或者到了等待时间,线程会继续往下执行
* 5. wait方法会释放锁; notify()/notifyAll()方法不会释放锁
* 6. 唤醒线程和等待线程必须是同一个对象锁,否则无法唤醒
*
*/
public class Demo01 {
public static void main(String[] args) {
Object obj = new Object();
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
synchronized (obj){
System.out.println("t1开始执行......");
System.out.println("t1开始等待......");
try {
/*
* java.lang.IllegalMonitorStateException 非法监视器(对象锁)状态异常
* 出现以上异常的原因是:调用wait()方法的对象不是对象锁
*/
// 调用等待方法
/*
* wait() == wait(0) : 线程阻塞,直到线程被唤醒才能继续往下执行
* wait()方法会释放锁
*/
// obj.wait();
/*
* wait(long timeout): 线程阻塞,当调用了唤醒后或者到了等待时间,线程会继续往下执行
*/
obj.wait(2000);
System.out.println("t1等待结束......");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
synchronized (obj){
System.out.println("t2开始执行......");
}
}
});
t1.start();
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.start();
}
}
notify()/notifyAll()唤醒等待线程演示:
/** * 演示: notify()/notifyAll()唤醒等待线程 * * void notify() * 唤醒在此对象监视器上等待的单个线程。 * 唤醒在此对象监视器上等待的单个线程。如果所有线程都在此对象上等待,则会选择唤醒其中一个线程。选择是任意性的。 * void notifyAll() * 唤醒在此对象监视器上等待的所有线程。 */ public class Demo02 { public static void main(String[] args) { Object obj = new Object(); Thread t1 = new Thread(new Runnable() { @Override public void run() { synchronized (obj){ System.out.println("t1开始执行......"); System.out.println("t1开始等待......"); try { obj.wait(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("t1等待结束......"); } } }); Thread t2 = new Thread(new Runnable() { @Override public void run() { synchronized (obj){ System.out.println("t2开始执行......"); System.out.println("t2开始等待......"); try { obj.wait(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("t2等待结束......"); } } }); t1.start(); t2.start(); // 5s后在主线程中唤醒线程 try { Thread.sleep(5000); } catch (InterruptedException e) { e.printStackTrace(); } synchronized (obj){ /* * 唤醒在此对象监视器上等待的单个线程。 * 选择是任意性的。 */ // obj.notify(); // 唤醒在此对象监视器上等待的所有线程。 obj.notifyAll(); } } }
生产者与消费者
生产者线程的任务类
package com.powernode.p5; /** * 生产者线程的任务类 * 任务: 生产数据--> 存储到缓冲区 */ public class ProducerRunnable implements Runnable { private ProductStack stack ; public ProducerRunnable(ProductStack stack) { this.stack = stack; } private boolean bool = true; // 该变量的作用是: 控制两种产品交替生产 @Override public void run() { while (true){ if(bool){ stack.save("白色的","包子"); }else{ stack.save("黄色的","馒头"); } bool = !bool; } } }消费者线程的任务类
package com.powernode.p5; /** * 消费者线程的任务类 * 任务: 从缓冲区中获取数据 */ public class ConsumerRunnable implements Runnable{ private ProductStack stack; public ConsumerRunnable(ProductStack stack) { this.stack = stack; } @Override public void run() { while(true){ stack.get(); } } }生产者与消费者存取数据的缓冲区
package com.powernode.p5; /** * 生产者和消费者存取数据的缓冲区 * 缓冲的功能: * 1. 生产者--存储数据 * 2. 消费者--获取数据 */ public class ProductStack { // 缓冲区中的数据 private Product product = new Product(); private boolean isEmpty = true; // 用来标记缓冲区是否有数据 /** * 生产者调用的存储数据的方法 * * @param color 产品的颜色 * @param name 产品的名称 */ public synchronized void save(String color, String name) { // 缓冲区有数据,就等待 while(!isEmpty){ try { this.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } // 缓冲区没有数据就生产数据 product.setColor(color); try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } product.setName(name); System.out.println(Thread.currentThread().getName() +"-->"+ color + "," + name); // 生产数据完数据 isEmpty = false; this.notifyAll(); } /** * 消费者调用的获取数据的方法 * 这里消费数据就使用输出语句模拟一下 */ public synchronized void get() { // 缓冲区没有有数据,就等待 while(isEmpty){ try { this.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } // 缓冲区有数据,就消费 System.out.println(Thread.currentThread().getName() +"----->"+product.getColor() + "--" + product.getName()); try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } // 消费完数据 isEmpty = true; this.notifyAll(); } }生产者与消费者共同操作的数据
package com.powernode.p5; /** * 生产者和消费者共同操作的数据 */ public class Product { private String color; private String name; public Product() { } public Product(String color, String name) { this.color = color; this.name = name; } public String getColor() { return color; } public void setColor(String color) { this.color = color; } public String getName() { return name; } public void setName(String name) { this.name = name; } @Override public String toString() { return "Product{" + "color='" + color + '\'' + ", name='" + name + '\'' + '}'; } }生产者与消费者的测试类
package com.powernode.p5; /** * 生產者和消費者的測試類 */ public class Demo01 { public static void main(String[] args) { ProductStack stack = new ProductStack(); ProducerRunnable producerRunnable = new ProducerRunnable(stack); ConsumerRunnable consumerRunnable = new ConsumerRunnable(stack); // 创建生产者线程 Thread p1 = new Thread(producerRunnable, "生产者1"); Thread p2 = new Thread(producerRunnable, "生产者2"); Thread p3 = new Thread(producerRunnable, "生产者3"); // 创建消费者线程 Thread c1 = new Thread(consumerRunnable, "消费者1"); Thread c2 = new Thread(consumerRunnable, "消费者2"); Thread c3 = new Thread(consumerRunnable, "消费者3"); p1.start(); p2.start(); p3.start(); c1.start(); c2.start(); c3.start(); } }
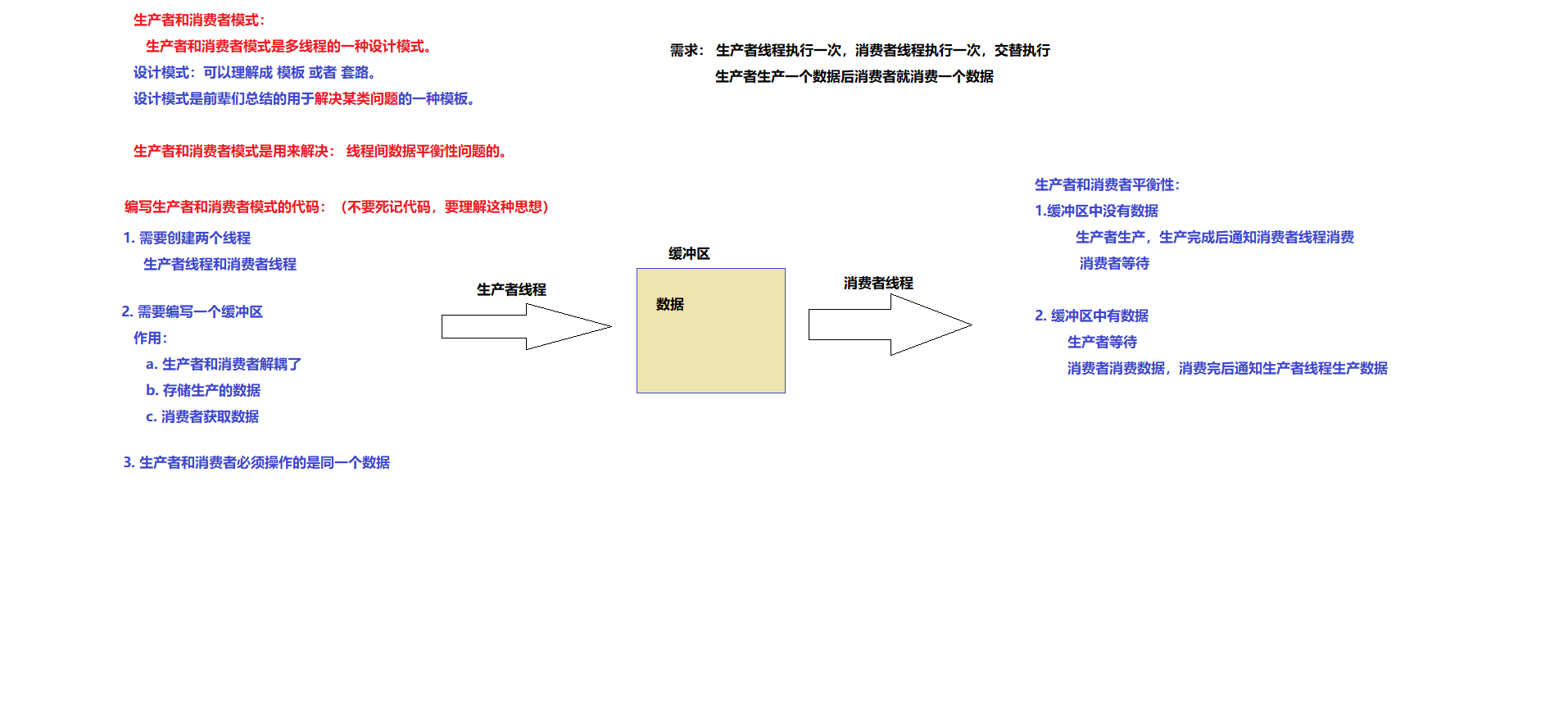
Lock锁
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* Lock锁:
* public interface Lock
* Lock 实现提供了比使用 synchronized 方法和语句可获得的更广泛的锁定操作。此实现允许更灵活的结构,可以具有差别很大的属性,可以支持多个相关的 Condition 对象。
*
* 1. synchronized是关键字,我们不能修改。
* 2. Lock的接口,接口中就是方法,接口的方法可以重写,还可以接收参数,所以比synchronized更加灵活。
*
* 方法摘要
* void lock()
* 获取锁。
* Condition newCondition()
* 返回绑定到此 Lock 实例的新 Condition 实例。
* void unlock()
* 释放锁。
*
* 实现类:ReentrantLock
* 一个可重入的互斥锁 Lock,它具有与使用 synchronized 方法和语句所访问的隐式监视器锁相同的一些基本行为和语义,但功能更强大。
*
*
* Condition接口:
* Condition 将 Object 监视器方法(wait、notify 和 notifyAll)分解成截然不同的对象,以便通过将这些对象与任意 Lock 实现组合使用,
* 为每个对象提供多个等待 set(wait-set)。其中,Lock 替代了 synchronized 方法和语句的使用,Condition 替代了 Object 监视器方法的使用。
*
* 方法摘要
* void await()
* 造成当前线程在接到信号或被中断之前一直处于等待状态。
* boolean await(long time, TimeUnit unit)
* 造成当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。
* void signal()
* 唤醒一个等待线程。
* void signalAll()
* 唤醒所有等待线程。
*/
public class Demo01 {
// 无参构造创建的是不公平锁
static Lock lock = new ReentrantLock();
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
// 获取锁
lock.lock();
try {
for (int i = 0; i < 10; i++) {
System.out.println("i===" + i);
}
} finally {
// 释放锁
lock.unlock();
}
}
});
t1.start();
}
}
Condition接口的等待唤醒机制
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* 演示: Condition接口的等待唤醒机制
*
* 注意:
* 1. notify()/notifyAll() 只能在配合synchronized使用
* 2. Condition接口的等待唤醒只能配合Lock使用
* 3. Condition接口的await/signal方法也必须编写在lock()和unlock()之间
*
*/
public class Demo02 {
static Lock lock = new ReentrantLock();
/**
* 两个线程使用不同的Condition对象,那么唤醒线程的时候可以通过Condition对象唤醒对应的线程
*/
static Condition condition01 = lock.newCondition();
static Condition condition02 = lock.newCondition();
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
lock.lock();
try {
System.out.println("t1---开始执行------");
System.out.println("t1---开始等待------");
condition01.await(); // 线程等待
System.out.println("t1---结束等待------");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
lock.lock();
try {
System.out.println("t2---开始执行------");
System.out.println("t2---开始等待------");
condition02.await(); // 线程等待
System.out.println("t2---结束等待------");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
});
t1.start();
t2.start();
// 主线程5s后唤醒t1线程
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock.lock();
// 唤醒线程1
condition01.signal();
// 唤醒线程2
condition02.signal();
lock.unlock();
}
}
单例设计模式
import java.io.IOException;
/**
* 单例设计模式:
* java中有23中设计模式,是java前辈总结的解决某类问题的套路。
*
* 单例设计模式:用来解决一个类只用一个对象的问题。
*/
public class Demo01 {
public static void main(String[] args) {
// Student s1 = Student.getStudent();
// Student s2 = Student.getStudent();
// Student s3 = Student.getStudent();
//
//
// System.out.println(s1);
// System.out.println(s2);
// System.out.println(s3);
for (int i = 0; i < 5; i++) {
new Thread(new Runnable() {
@Override
public void run() {
Student s = Student.getStudent();
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(s);
}
}).start();
}
}
}
单例设计模式——饿汉式
/**
* 需求: 将该类做成单例的;也就是该类只有创建一个对象
*
* 单例设计模式---饿汉式
* 线程安全的
*
* 1. 构造函数私有
* 2. 创建一个私有的静态的本类对象
* 3. 提供一个静态的公共方法,返回本类对象
*/
public class Student {
// final 非必需
private static final Student STUDENT = new Student();
private Student(){}
public static Student getStudent(){
return STUDENT;
}
}
DAY25
单例设计模式——懒汉式
/**
* 单例设计模式(Singleton)-懒汉式
*/
public class Demo01 {
public static void main(String[] args) {
// Student student1 = Student.getStudent();
// Student student2 = Student.getStudent();
// Student student3 = Student.getStudent();
//
// System.out.println(student1);
// System.out.println(student2);
// System.out.println(student3);
for (int i = 0; i < 5; i++) {
new Thread(new Runnable() {
@Override
public void run() {
Student student = Student.getStudent();
System.out.println(student);
}
}).start();
}
}
}
懒汉式双重检测
/**
* 需求: 该类设计成一个单例类
* 懒汉式:
* 用的时候才创建对象
* 什么时候才叫用呢? 调用getStudent()方式时
*
* 懒汉式有线程安全问题。
*
*/
public class Student {
/*
* volatile 解决指令重排
*/
private static volatile Student student;
private Student(){
}
/**
* 以下的代码有效率问题:
* 就是每个线程进入的时候,无论对象是否已经创建
* 都会获取锁,释放锁
*
* 我们想一下: 什么时候获取锁?
* 对象是null时候,线程获取锁进入,创建线程,释放锁
* 后面的线程如果对象已经创建,应该直接返回对象即可,不需要再次获取锁
* 因为同步代码中的 if(student == null)不会成立,所以没有必要进入锁了。
*
*/
// t1 - null t2 -- student
// public static Student getStudent(){
// /*
// * 使用同步代码的目的是为了保证多线程环境下的线程安全
// */
// // t1 -- 获取锁 t2 获取锁
// synchronized (Student.class){
// // 单例: 只能new一次
// /*
// * 这里的if条件是用来判断对象为null时才创建对象
// */
// if(student == null){
// student = new Student();
// }
// } // t1 - student 释放锁
// return student;
// }
/**
* 懒汉式的双重检测
*/
public static Student getStudent(){
/*
* 外层的if(student == null)作用是减少线程获取锁,提升效率
*/
if(student == null) {
/*
* 使用同步代码的目的是为了保证多线程环境下的线程安全
*/
synchronized (Student.class) {
/*
* 单例: 只能new一次
* 这里的if条件是用来判断对象为null时才创建对象
*/
if (student == null) {
student = new Student();
}
}
}
return student;
}
}
在主线程中汇总两个线程之和
/**
* 需求: 线程1计算1-5之和,线程2计算1-3之和,要求在主线程中汇总两个线程之和。
*/
public class Demo01 {
static int sum01 = 0;
static int sum02 = 0;
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 5; i++) {
sum01 += i;
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 3; i++) {
sum02 += i;
}
}
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 主线程中汇总两个线程之和
System.out.println("main==汇总的和是:" + (sum01 + sum02));
}
}
创建线程方式三:实现Callable接口
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* 创建线程方式三:实现Callable接口
*
* 接口Callable<V>
* 类型参数:V - call 方法的结果类型
* public interface Callable<V>
* 返回结果并且可能抛出异常的任务。实现者定义了一个不带任何参数的叫做 call 的方法。
* Callable 接口类似于 Runnable,两者线程的任务类。但是 Runnable 不会返回结果,并且无法抛出经过检查的异常。
* 方法摘要
* V call()
* 计算结果,如果无法计算结果,则抛出一个异常。
*
* FutureTask<V>类
* 可取消的异步计算。
* 可使用 FutureTask 包装 Callable 或 Runnable 对象。因为 FutureTask 实现了 Runnable,所以可将 FutureTask 提交给线程池执行。
*
* 构造方法摘要
* FutureTask(Callable<V> callable)
* 创建一个 FutureTask,一旦运行就执行给定的 Callable。
*
* V get()
* 如有必要,等待计算完成,然后获取其结果。
*
* 需求: 线程1计算1-5之和,线程2计算1-3之和,要求在主线程中汇总两个线程之和。
*
*/
/**
* 任务类1:计算1-5之和
*/
class MyCallable01 implements Callable<Integer>{
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 1; i <= 5; i++) {
sum += i;
}
return sum;
}
}
/**
* 任务类2:计算1-3之和
*/
class MyCallable02 implements Callable<Integer>{
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 1; i <= 3; i++) {
sum += i;
}
return sum;
}
}
public class Demo02 {
public static void main(String[] args) {
// 线程的任务类对象
MyCallable01 myCallable01 = new MyCallable01();
MyCallable02 myCallable02 = new MyCallable02();
/*
* 创建两个线程
* new Thread()要么无参,要么传入Runnable对象
* 但是Callable接口跟Runnable接口没有关系,无法直接传入。
* 所以现在我们要想办法将 Callable接口 和 Runnable接口 建立上 关系
*/
FutureTask<Integer> futureTask01 = new FutureTask<>(myCallable01);
FutureTask<Integer> futureTask02 = new FutureTask<>(myCallable02);
Thread t1 = new Thread(futureTask01);
Thread t2 = new Thread(futureTask02);
t1.start();
t2.start();
// 主线程中汇总两个线程之和
try {
/*
* get(): 会阻塞。等待计算结果
*/
System.out.println("main==汇总的和是:" + (futureTask01.get() + futureTask02.get()));
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
演示线程的生命周期
import java.io.IOException;
import java.io.InputStream;
/**
*演示:线程的生命周期
*
*public Thread.State getState()
* 返回该线程的状态。
*
*线程状态。线程可以处于下列状态之一:
*
* NEW
* 至今尚未启动的线程处于这种状态。
* RUNNABLE
* 正在 Java 虚拟机中执行的线程处于这种状态。
* BLOCKED
* 受阻塞并等待某个监视器锁的线程处于这种状态。
* WAITING
* 无限期地等待另一个线程来执行某一特定操作的线程处于这种状态。
* TIMED_WAITING
* 等待另一个线程来执行取决于指定等待时间的操作的线程处于这种状态。
* TERMINATED
* 已退出的线程处于这种状态。
*
* 在给定时间点上,一个线程只能处于一种状态。这些状态是虚拟机状态,它们并没有反映所有操作系统线程状态。
*
*/
public class Demo03 {
public static void main(String[] args) {
Object obj = new Object();
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
synchronized (obj){
for (;;){}
}
}
});
t2.start();
Thread t3 = new Thread(new Runnable() {
@Override
public void run() {
/*
* 使用IO java中线程的状态是RUNNABLE,不会进入阻塞状态
*/
InputStream in = System.in;
System.out.println("请输入数据:");
try {
System.out.println(in.read());
} catch (IOException e) {
e.printStackTrace();
}
}
});
t3.start();
Thread t4 = new Thread(new Runnable() {
@Override
public void run() {
synchronized (obj){
for (;;){}
}
}
});
t4.start();
Thread t5 = new Thread(new Runnable() {
@Override
public void run() {
synchronized (this){
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
t5.start();
Thread t6 = new Thread(new Runnable() {
@Override
public void run() {
// synchronized (this){
// try {
// this.wait(5000);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
// }
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t6.start();
Thread t7 = new Thread(new Runnable() {
@Override
public void run() {
}
});
t7.start();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t1的状态: " + t1.getState()); // NEW
System.out.println("t2的状态: " + t2.getState()); // RUNNABLE
System.out.println("t3的状态: " + t3.getState()); // RUNNABLE
System.out.println("t4的状态: " + t4.getState()); // BLOCKED
System.out.println("t5的状态: " + t5.getState()); // WAITING
System.out.println("t6的状态: " + t6.getState()); // TIMED_WAITING
System.out.println("t7的状态: " + t7.getState()); // TERMINATED
}
}
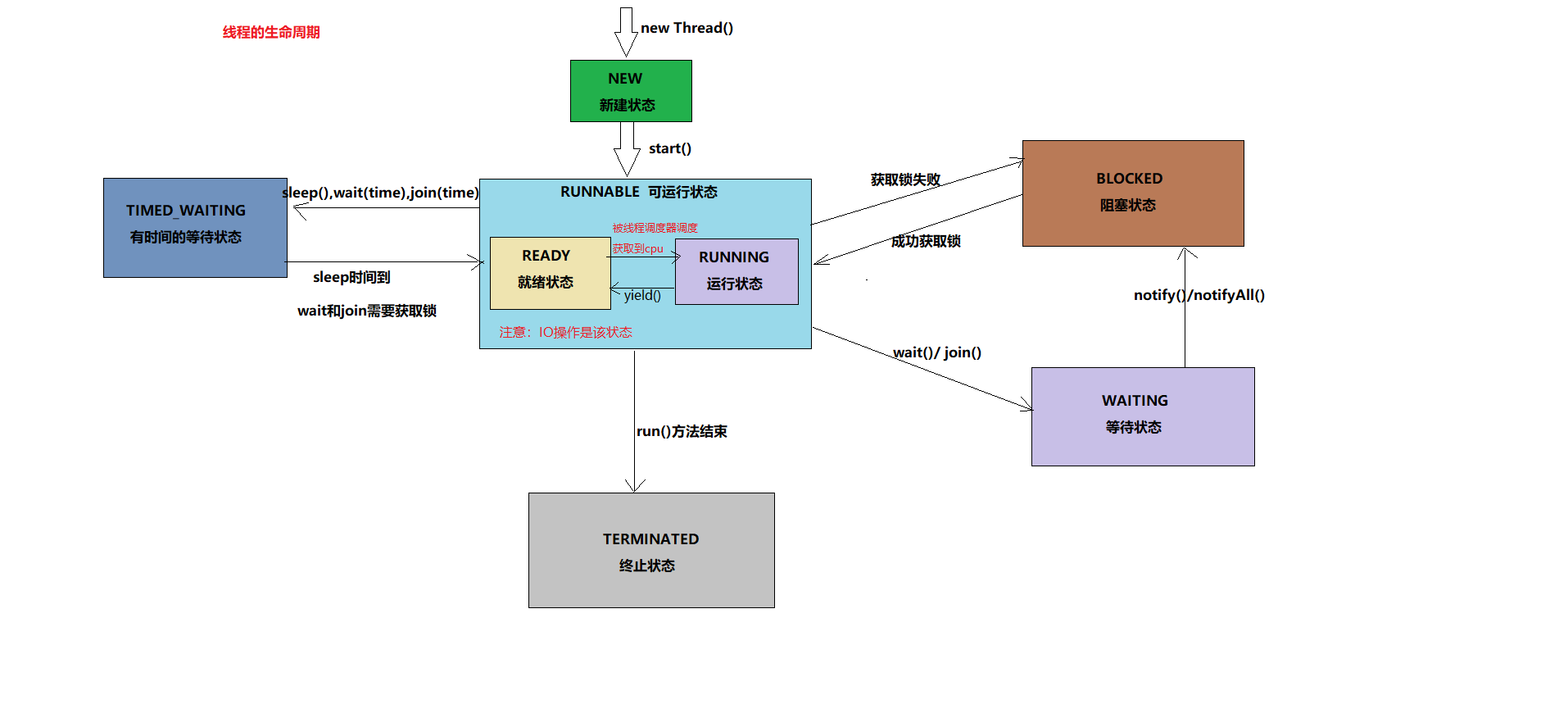
定时器-Timer类
import java.io.IOException;
import java.util.Timer;
import java.util.TimerTask;
/**
* 定时器-Timer类
* 一种工具,线程用其安排以后在后台线程中执行的任务。可安排任务执行一次,或者定期重复执行。
* 与每个 Timer 对象相对应的是单个后台线程,用于顺序地执行所有计时器任务。
*
*方法摘要
* void cancel()
* 终止此计时器,丢弃所有当前已安排的任务
*
*
* TimerTask 定时器的任务类
* 由 Timer 安排为一次执行或重复执行的任务。
*
* 方法摘要
* boolean cancel()
* 取消此计时器任务。
* void run()
* 此计时器任务要执行的操作。
*/
public class Demo01 {
public static void main(String[] args) {
// 创建定时器对象
Timer timer = new Timer();
// 让对象干活 -- 执行任务
// 3s后执行任务,任务只执行一次
// timer.schedule(new MyTimerTask(timer),3000);
// 3s后执行任务,后续任务每2s执行一次 -- 周期性任务
timer.schedule(new MyTimerTask01(),3000,2000);
}
private static class MyTimerTask extends TimerTask{
private Timer timer;
public MyTimerTask(Timer timer) {
this.timer = timer;
}
@Override
public void run() {
// 定时器执行的任务代码
Runtime runtime = Runtime.getRuntime();
try {
runtime.exec("mspaint");
} catch (IOException e) {
e.printStackTrace();
}
// 终止计时器
timer.cancel();
}
}
private static class MyTimerTask01 extends TimerTask{
@Override
public void run() {
// 定时器执行的任务代码
Runtime runtime = Runtime.getRuntime();
try {
runtime.exec("mspaint");
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
线程池
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* 线程池:
* 线程的创建和销毁都是消耗资源的,所以频繁的创建和销毁线程会影响性能。
* 线程池技术就可以将线程保存在“池”中,需要使用线程的时候就或池中获取,用完之后
* 放回到池中,而不是销毁线程。这样就可以做到线程的复用,提升性能。
*
*/
public class Demo02 {
public static void main(String[] args) {
// test01();
// test02();
// test03();
test04();
}
/**
* 时间调度线程池
* 指定时间执行任务
*/
private static void test04() {
ScheduledExecutorService service = Executors.newScheduledThreadPool(3);
service.schedule(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
},5000, TimeUnit.MILLISECONDS);
service.shutdown();
}
/**
* 缓冲线程池
* 提交任务后如果有空闲的线程就复用,没有将创建
*/
private static void test03() {
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 20; i++) {
executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
});
}
executorService.shutdown();
}
/**
* 固定线程池
*/
private static void test02() {
// 创建3个线程
ExecutorService executorService = Executors.newFixedThreadPool(3);
for (int i = 0; i < 5; i++) {
executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
});
}
executorService.shutdown();
}
/**
* 创建单一线程
*/
private static void test01() {
// 使用线程池工具类创建单一线程
ExecutorService service = Executors.newSingleThreadExecutor();
// 执行任务
// submit()提交任务给线程执行
service.submit(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
});
// 关闭线程池
service.shutdown();
}
}
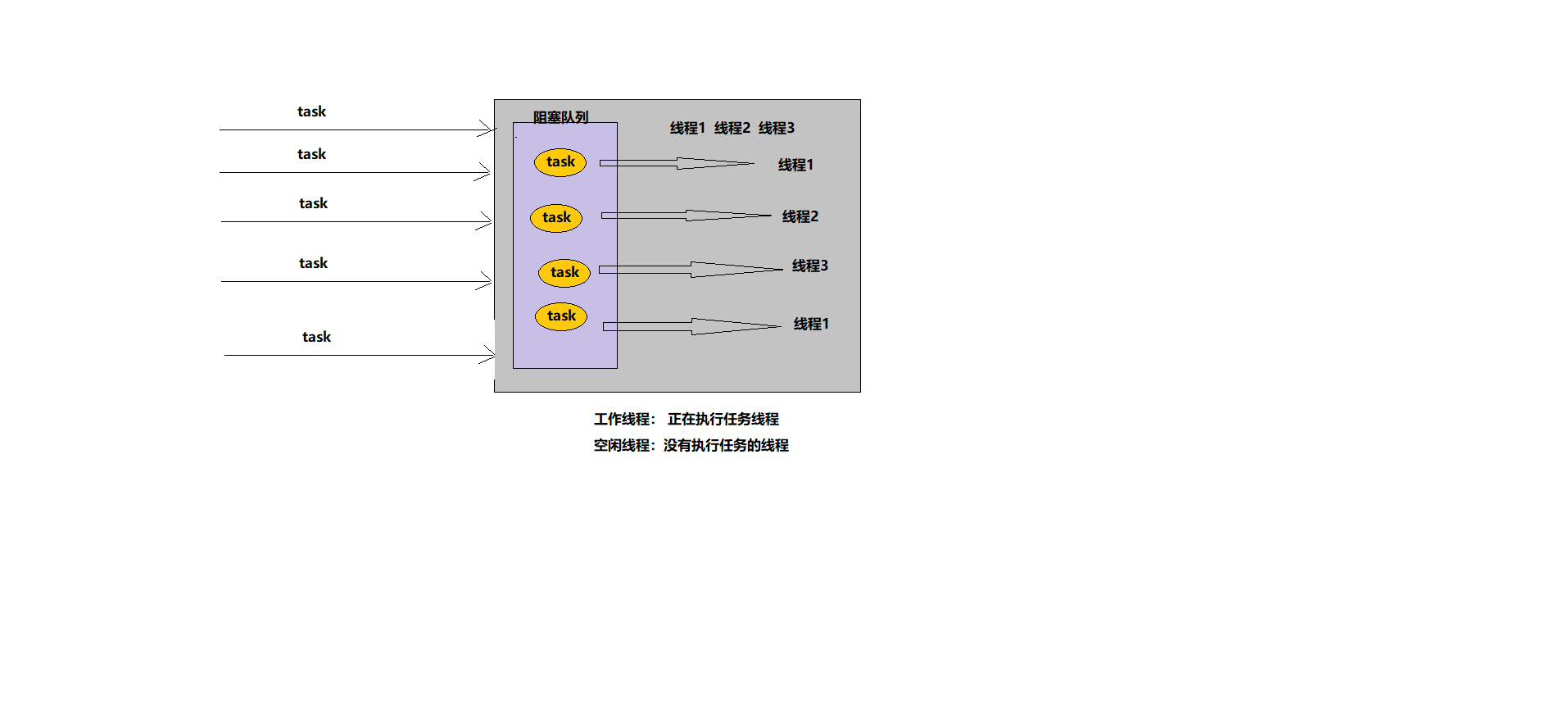
线程设置什么内容,获取到的就是什么内容
class Info {
String name;
String data;
public void set(String name, String data) {
this.name = name;
this.data = data;
System.out.println(Thread.currentThread().getName() + "设置了:" + name + "," + data);
}
}
/**
* 需求: 线程设置什么内容,获取到的就是什么内容
*/
public class Demo01 {
public static void main(String[] args) {
m01();
}
private static void m02() {
// 需要使用m01中的info对象
}
public static void m01() {
for (int i = 0; i < 3; i++) {
final int index = i;
new Thread(new Runnable() {
@Override
public void run() {
/**
* 现在的代码满足: 线程设置什么内容,获取到的就是什么内容
* 我们使用了 将Info定义成局部变量的方式完成的。
*
* 但是如果现在要求在其他方法中也可以使用这个info对象,那么使用局部变量的方式就不可以了
* 如果将info设置成全局变量,那么我们的需求: 线程设置什么内容,获取到的就是什么内容 就无法满足.
*
* 如果既然满足要求,又要将info设置成全局变量,那么可以使用ThreadLocal来解决
*/
Info info = new Info();
// 设置数据
info.set(Thread.currentThread().getName(), index + "");
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 获取数据
System.out.println(Thread.currentThread().getName() + "获取到的数据是:" + info.name + "," + info.data);
}
}).start();
}
}
}ThreadLocal类
/**
* ThreadLocal<T>类:
* 该类提供了线程局部 (thread-local) 变量。
* 每个线程都有自己的局部变量。
*
*方法摘要
* T get()
* 获取当前线程绑定的值
* protected T initialValue()
* 返回此线程局部变量的当前线程的“初始值”。给当前线程绑定初始值
* void remove()
* 将值和当前线程解绑
* void set(T value)
* 将值和当前线程绑定
*
*
* ThreadLocal和synchonized对比
* 1. synchonized是用来解决多线程共享数据的线程安全问题
* 2. ThreadLocal是用来对多线程数据进行隔离的。也就是每个线程一份数据。
*
*
*/
public class Demo02 {
// 创建ThreadLocal对象
private static ThreadLocal<Info> threadLocal = new ThreadLocal<>();
public static void main(String[] args) {
for (int i = 0; i < 3; i++) {
final int index = i;
new Thread(new Runnable() {
@Override
public void run() {
m01(index);
m02();
}
}).start();
}
}
private static void m02() {
Info info = threadLocal.get();
System.out.println(Thread.currentThread().getName()+"======"+info.name+","+info.data);
}
public static void m01(int index) {
// 通过ThreadLocal将当前线程和info对象绑定,绑定的后的info对象就是线程的局部变量
threadLocal.set(new Info());
// 通过threadLocal获取对象,设置数据
threadLocal.get().set(Thread.currentThread().getName(), index + "");
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 获取数据
System.out.println(Thread.currentThread().getName() + "获取到的数据是:" + threadLocal.get().name + "," + threadLocal.get().data);
}
}
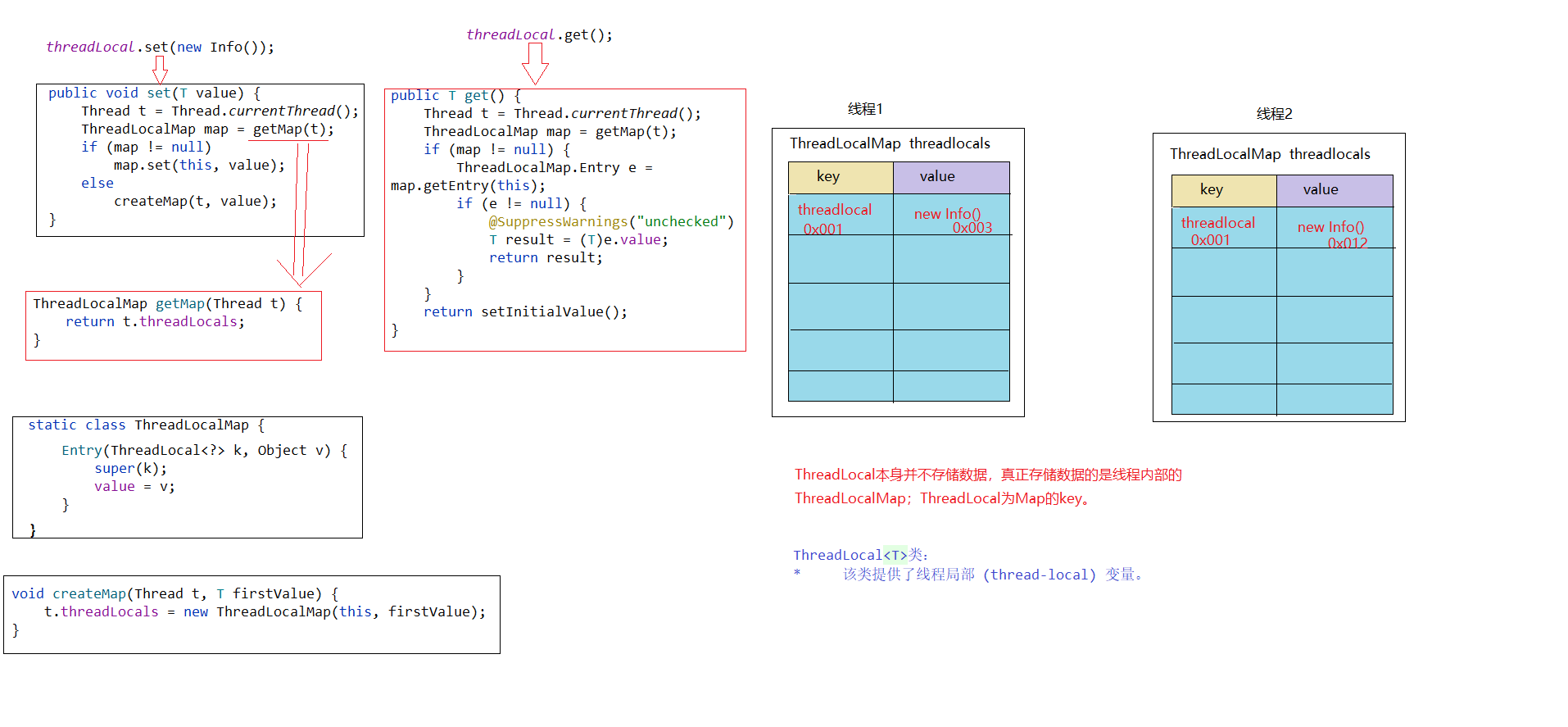
initialValue()【给当前线程绑定初始值】
class Cat{
}
public class Demo03 {
// 给当前线程绑定初始值
static ThreadLocal<Cat> local = new ThreadLocal<Cat>(){
@Override
protected Cat initialValue() {
return new Cat();
}
};
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
test01();
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
test02();
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
test01();
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
test02();
}
});
Thread t3 = new Thread(new Runnable() {
@Override
public void run() {
test01();
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
test02();
}
});
t1.start();
t2.start();
t3.start();
}
// t1
public static void test01(){
System.out.println(Thread.currentThread().getName()+"--->" + local.get());
}
// t1
public static void test02(){
// 使用cat
System.out.println(Thread.currentThread().getName()+"======>" + local.get());
}
}
CountDownLatch倒计时锁
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* CountDownLatch 倒计时锁
* 等待多线程完成的CountDownLatch,允许一个或多个线程等待其他线程完成操作。
*
* 注意: CountDownLatch的计数器不能重置
*/
public class Demo01 {
public static void main(String[] args) {
/**
* 创建了一个CountDownLatch对象,初始计数器是3
*/
CountDownLatch latch = new CountDownLatch(3);
ExecutorService service = Executors.newFixedThreadPool(3);
for (int i = 0; i < 3; i++) {
service.submit(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"开始执行.....");
latch.countDown();// 计数器-1
}
});
}
try {
/*
* 主线程阻塞,直到倒计时为0,线程继续向下执行
*/
System.out.println("主线程等待。。。。。");
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("主线程结束......");
service.shutdown();
}
}
模拟——主线程下达命令后,3个子线程才开始执行
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 模拟:
* 主线程下达命令后,3个子线程才开始执行
*/
public class Demo02 {
public static void main(String[] args) {
CountDownLatch latch = new CountDownLatch(1);
ExecutorService executorService = Executors.newFixedThreadPool(3);
for (int i = 0; i < 3; i++) {
executorService.submit(new Runnable() {
@Override
public void run() {
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"开始运行......");
}
});
}
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 主线程下达命令后,3个子线程才开始执行
System.out.println("主线程下达命令后");
latch.countDown();
executorService.shutdown();
}
}
CyclicBarrier 循环栅栏
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* CyclicBarrier 循环栅栏
* 一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point)。
* 比如: 你们家大年三十团员,吃饭的时候需要5个人全部到齐了才能开饭。
*
*/
public class Demo03 {
public static void main(String[] args) {
/*
* 参数和线程数据量保持一致
*/
// CyclicBarrier barrier = new CyclicBarrier(5);
/*
* 第二个参数就是达到屏障点 执行的任务
*/
CyclicBarrier barrier = new CyclicBarrier(5, new Runnable() {
@Override
public void run() {
System.out.println("你们大家长说: 人到齐了,大家开动!!!");
}
});
ExecutorService executorService = Executors.newFixedThreadPool(5);
for (int i = 0; i < 5; i++) {
executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"到家了。。。。。");
try {
// 阻塞 ,直到五个线程都执行后,代码继续向下
barrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"开始吃饭了。。。。。");
}
});
}
executorService.shutdown();
}
}
Semaphore【信号量】
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
/**
* Semaphore:信号量
* Semaphore(信号量)是用来限制同时访问资源的线程数量。 -- 限流
*
* 需求: 总人数有10人, 厕所坑位只有3个
*/
public class Demo04 {
public static void main(String[] args) {
ExecutorService service = Executors.newFixedThreadPool(10);
Semaphore semaphore = new Semaphore(3);
/**
* 10人上厕所,但是坑位只有3个,所以需要限流
*/
for (int i = 0; i < 10; i++) {
service.submit(new Runnable() {
@Override
public void run() {
try {
semaphore.acquire(); // 获得许可 -- 令牌
System.out.println(Thread.currentThread().getName() + "正在蹲坑。。。。。");
Thread.sleep(300);
System.out.println(Thread.currentThread().getName() + "离开厕所。。。。。。。。。。。");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
semaphore.release(); // 返回许可 -- 归还令牌
}
}
});
}
service.shutdown();
}
}
反射——Reflect
/**
* 反射(Reflect):
*
* 反射对初学者来说 也是难点。
* 难点: 不是API难,而是大家学了之后不知道怎么用,在哪里用?
*
* 无反射无框架。反射是框架的底层代码。如果在开发中我们不编写公共的工具代码,那么反射可能你就一直是用不到。
*
* 反射的主要作用: 写公共代码的
*
*
*/
public class Demo01 {
public static void main(String[] args) throws Exception {
/*
* 创建对象 --- 正向获取 --- 静态的获取方式
* 静态的获取方式: 就是这里的代码固定了, Student student = new Student();创建的永远都是Student对象
*/
Student student = new Student();
System.out.println(student);
/*
* 使用反射获取 -- 反向获取 -- 动态的获取方式
* Class.forName("com.powernode.p6.Student");
* aClass.newInstance();
* 可以获取任意类的Class,然后创建对象
*/
Class<?> aClass = Class.forName(args[0]);
Object obj = aClass.newInstance();
System.out.println(obj);
}
}
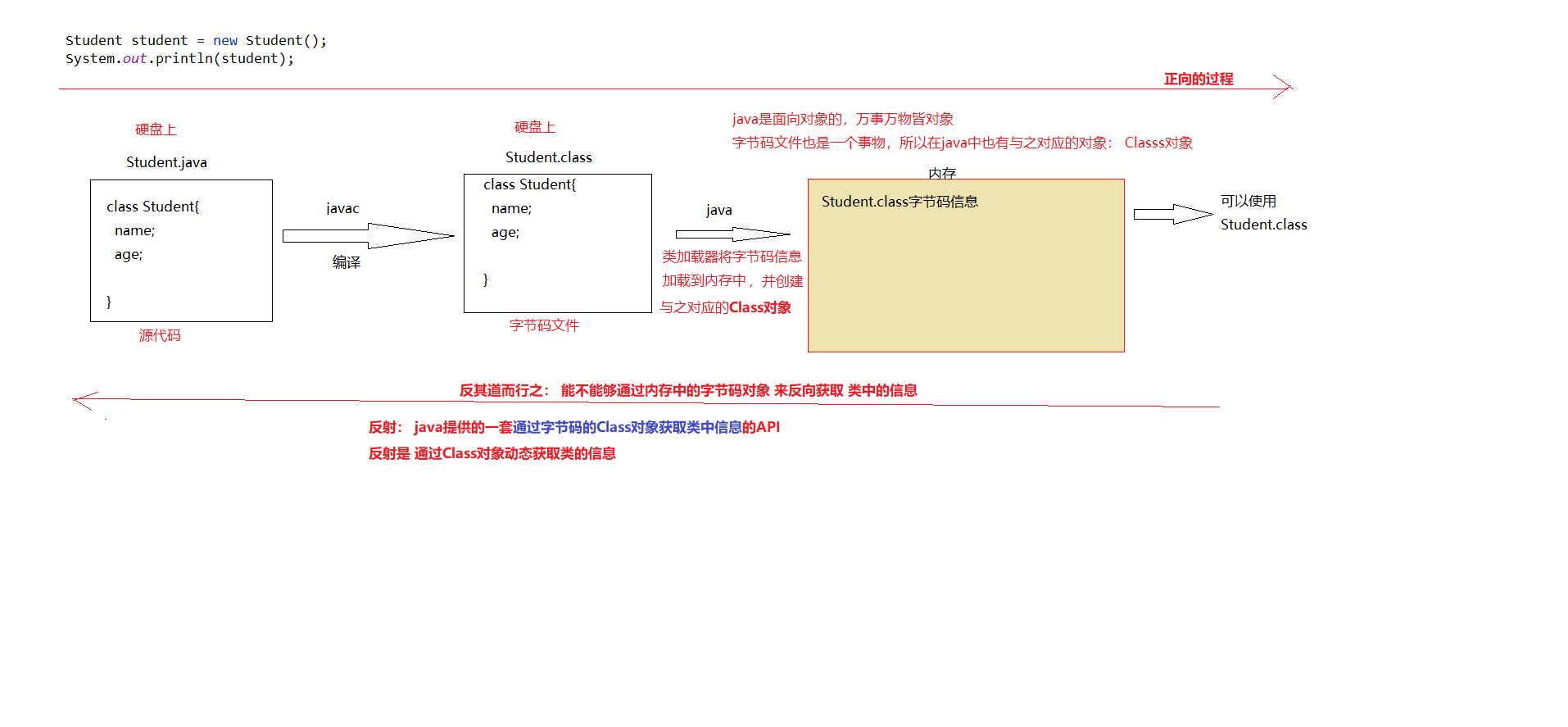
Class类
/**
* 1. Class类:
* Class 类的实例表示正在运行的 Java 应用程序中的类和接口。枚举是一种类,注解是一种接口。
* 每个数组属于被映射为 Class 对象的一个类,所有具有相同元素类型和维数的数组都共享该 Class 对象。
* 基本的 Java 类型(boolean、byte、char、short、int、long、float 和 double)和关键字 void 也表示为 Class 对象。
*
* Class 没有公共构造方法。Class 对象是在加载类时由 Java 虚拟机以及通过调用类加载器中的 defineClass 方法自动构造的。
*
*
* 获取Class对象
*
*/
public class Demo02 {
public static void main(String[] args) throws Exception {
/*
* 方式一:Class.forName("全限定类名") -- 推荐方式: 解耦
* 全限定类名: 包名.类名
*/
Class<?> aClass = Class.forName("com.powernode.p6.Demo02");
System.out.println(aClass);
System.out.println(aClass.getName());
System.out.println("--------------------------");
/*
* 方式二:数据类型.class --- 主要用在参数传递上
*/
System.out.println(Demo02.class);
System.out.println(int.class);
System.out.println(int[].class);
System.out.println(void.class);
System.out.println("--------------------------");
/*
* 方式三:对象.getClass()
*/
Object obj = new Object();
String str = new String();
System.out.println(obj.getClass());
System.out.println(str.getClass());
System.out.println("--------------------------");
/*
* 方式四:包装类.TYPE
*/
System.out.println(Integer.TYPE);
System.out.println(Boolean.TYPE);
System.out.println(Character.TYPE);
}
}
javaBean – 实体类
/**
* javaBean -- 实体类
*
* javaBean:
* java 是咖啡
* bean 是豆子
*
* javaBean就是Java程序的一个可重复使用的组件
* javaBean的有规范要求的:
* 1、成员变量私有化
* 2. 提供无参构造
* 3. 提供setter和getter
*/
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
DAY26
使用反射获取类信息
import java.lang.reflect.Modifier;
/**
* 演示: 使用反射获取类信息
*/
public class ClassDemo01 {
public static void main(String[] args) {
try {
// aClass 就是Student类的Class对象
Class<?> aClass = Class.forName("com.powernode.p1.Student");
System.out.println(aClass);
// System.out.println(aClass.getName());
// // 获取aClass这个Class对象的类信息
// Class<? extends Class> aClass1 = aClass.getClass();
// System.out.println(aClass1);
// 获取父类
Class<?> superclass = aClass.getSuperclass();
System.out.println(superclass);
// 获取接口, getInterfaces()只能获取本类直接实现的接口
Class<?>[] interfaces = aClass.getInterfaces();
for (Class<?> anInterface : interfaces) {
System.out.println(anInterface);
}
// 获取类的修饰符
int modifiers = aClass.getModifiers();
System.out.println(modifiers);
// 判断类是不是public修饰的
System.out.println(Modifier.isPublic(modifiers));
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
使用反射获取类信息,并创建对象
/**
* 演示: 使用反射获取类信息,并创建对象
*/
public class ClassDemo02 {
public static void main(String[] args) {
try {
Class<?> aClass = Class.forName("com.powernode.p1.Student");
// 使用aClass调用非私有的无参构造创建对象
// 所以newInstance();在jdk9开始被过时了
Object obj = aClass.newInstance();
System.out.println(obj);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InstantiationException e) {
e.printStackTrace();
}
}
}
反射:根据字节码对象动态地获取类信息
/**
* 反射:根据字节码对象动态的获取类信息
*
* Class对象:字节码对象
*
* 演示: 使用反射获取类的包信息
*
* 反射机制就是将类的各个组成部分(属性,方法,构造器)封装为其它对象。
* 反射将类中的包信息封装成了Package对象
*/
public class PackageDemo01 {
public static void main(String[] args) {
try {
// 获取字节码对象 Class对象
Class<?> aClass = Class.forName("com.powernode.p1.Student");
// 为所欲为 -- 获取类的包信息
// 反射将类中的包信息封装成了Package对象
Package aPackage = aClass.getPackage();
System.out.println(aPackage);
System.out.println(aPackage.getName());
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
Student类
import java.io.Serializable; public class Student extends Person implements Serializable { private String name; public int age; public Student() { System.out.println("无参构造被调用"); } public Student(String name) { System.out.println("带参构造被调用----name"); } private Student(String name, int age) { this.name = name; this.age = age; System.out.println("name====age----"); } public void eat() { System.out.println("吃货"); } private String sleep(String name) { System.out.println(name + "睡大觉"); return "睡好了"; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + "} "; } }Person类
public class Person implements Cloneable { public String address; public void walk(String name) { System.out.println("和" + name + "一起散步"); } }
使用反射获取类中的字段(成员变量)
import com.powernode.p1.Student;
import java.lang.reflect.Field;
/**
* 演示: 使用反射获取类中的字段(成员变量)
*
* 反射机制就是将类的各个组成部分(属性,方法,构造器)封装为其它对象。
* 反射将类中的字段封装成Field对象
*/
public class FieldDemo01 {
public static void main(String[] args) {
Class<Student> aClass = Student.class;
try {
/*
* 获取字段
* getField(字段名称): 获取本类或父类中声明的指定的public字段
*/
Field ageField = aClass.getField("age");
System.out.println(ageField);
System.out.println(ageField.getName());// 获取字段名称
System.out.println(ageField.getModifiers()); // 获取修饰符
System.out.println(ageField.getType()); // 获取返回值类型
System.out.println("-------------getFields()-------------");
/*
* getFields(): 获取本类或父类中声明的所有public字段
*/
Field[] fields = aClass.getFields();
for (Field field : fields) {
System.out.println(field);
}
System.out.println("------------getDeclaredField--------------");
/*
* Declared: 已声明过的。
* 1. 只有本类中自己定义的才叫做本类中声明的。
* 2. 只要是本类中定义的都叫做声明,跟访问权限无关。
* 本类中定义的私有字段也是本类声明的。
*
* getDeclaredField(): 获取本类中声明过的指定字段
*/
Field nameField = aClass.getDeclaredField("name");
System.out.println(nameField);
System.out.println(nameField.getModifiers()); // 获取字段的修饰符
System.out.println("------------getDeclaredFields--------------");
/*
* getDeclaredFields(): 获取本类中声明过的所有字段
*/
Field[] declaredFields = aClass.getDeclaredFields();
for (Field declaredField : declaredFields) {
System.out.println(declaredField);
}
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
}
}
使用反射给字段赋值和取值
import java.lang.reflect.Field;
/**
* 演示: 使用反射给字段赋值和取值
*/
public class FieldDemo02 {
public static void main(String[] args) {
try {
Class<?> aClass = Class.forName("com.powernode.p1.Student");
// public int age
Field ageField = aClass.getField("age");
// 赋值
/*
* set(Object obj, Object value): 给字段赋值
* 第一个参数obj:表示给哪一个对象的字段赋值
* 第二个参数value:给字段赋的具体值
*/
Object obj = aClass.newInstance();
ageField.set(obj,18);
System.out.println(obj);
// 取值
/*
* Object get(Object obj): 获取字段的值
* 参数obj:表示给获取哪一个对象的字段值
*/
Object value = ageField.get(obj);
System.out.println(value);
System.out.println("--------------给非公共字段赋值和取值-----------------");
Field nameField = aClass.getDeclaredField("name");
System.out.println(nameField);
// 赋值
/*
* 使用反射给非公共字段赋值或取值都会抛出非法访问异常:java.lang.IllegalAccessException
* 如何解决: 需要设置暴力访问
* setAccessible(true);设置暴力访问,其实就是取消了访问权限的检测
*/
nameField.setAccessible(true);
nameField.set(obj,"张三");
System.out.println(obj);
// 取值
Object nameValue = nameField.get(obj);
System.out.println(nameValue);
} catch (Exception e) {
e.printStackTrace();
}
}
}
使用反射获取类中的构造信息
import java.lang.reflect.Constructor;
/**
* 演示: 使用反射获取类中的构造信息
*
* 反射机制就是将类的各个组成部分(属性,方法,构造器)封装为其它对象。
* 反射会将类中的构造信息封装成Constructor对象
*
*/
public class ConstructorDemo01 {
public static void main(String[] args) {
try {
/*
* 全限定类名: FQCN--完整类别名称(Fully Qualified Class Name)
*/
Class<?> aClass = Class.forName("com.powernode.p1.Student");
/*
* getConstructor(Class<?>... parameterTypes): 获取本类的public修饰的构造
* 参数:就是构造函数中形参类型的Class对象
*
*/
// 获取public修饰的无参构造
Constructor<?> constructor = aClass.getConstructor();
System.out.println(constructor);
Constructor<?> constructor1 = aClass.getConstructor(String.class);
System.out.println(constructor1);
/*
* getConstructors(): 获取本类中所有的public修饰的构造
*/
System.out.println("-----------------------");
/*
* getDeclaredConstructor(Class<?>... parameterTypes): 根据参数类型获取本类中的构造函数
*/
Constructor<?> declaredConstructor = aClass.getDeclaredConstructor(int.class);
System.out.println(declaredConstructor);
/*
* getDeclaredConstructors(): 获取本类中所有的构造函数
*/
Constructor<?>[] declaredConstructors = aClass.getDeclaredConstructors();
for (Constructor<?> declaredConstructor1 : declaredConstructors) {
System.out.println(declaredConstructor1);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
使用反射通过构造创建对象
import java.lang.reflect.Constructor;
/**
* 演示: 使用反射通过构造创建对象
*
*/
public class ConstructorDemo02 {
public static void main(String[] args) {
try {
Class<?> aClass = Class.forName("com.powernode.p1.Student");
// public修饰的构造函数创建对象 -- 自己耍
// 演示非公共的构造函数创建对象
Constructor<?> constructor = aClass.getDeclaredConstructor(String.class,int.class);
/*
* T newInstance(Object ... initargs): 使用构造创建对象
* 参数:调用构造时传入的实参
* 返回值:创建的对象
*/
constructor.setAccessible(true);
Object obj = constructor.newInstance("张三",20);
System.out.println(obj);
} catch (Exception e) {
e.printStackTrace();
}
}
}
使用反射获取类中的方法
import java.lang.reflect.Method;
/**
* 演示: 使用反射获取类中的方法
*
* 反射机制就是将类的各个组成部分(属性,方法,构造器)封装为其它对象。
* 反射可以将类中的方法封装成Method对象
*/
public class MethodDemo01 {
public static void main(String[] args) {
try {
Class<?> aClass = Class.forName("com.powernode.p1.Student");
/*
* getMethod(String name, Class<?>... parameterTypes): 获取本类或父类中的指定的public成员方法
* 第一个参数: 方法名
* 第二个参数: 方法形参类型的Class对象
*
*/
Method walkMethod = aClass.getMethod("walk", String.class);
System.out.println(walkMethod);
System.out.println("-----------------getMethods------------------");
/*
* getMethods(): 获取本类或父类中的所有的public成员方法
*
*/
Method[] methods = aClass.getMethods();
for (Method method : methods) {
System.out.println(method);
}
System.out.println("-----------------getDeclaredMethod------------------");
/*
* getDeclaredMethod(String name, Class<?>... parameterTypes): 获取本类中声明过的指定的成员方法
* 第一个参数: 方法名
* 第二个参数: 方法形参类型的Class对象
*/
Method eatMethod = aClass.getDeclaredMethod("eat");
System.out.println(eatMethod);
System.out.println("-----------------getDeclaredMethods------------------");
/*
* getDeclaredMethods(): 获取本类中声明过的所有成员方法
*/
Method[] declaredMethods = aClass.getDeclaredMethods();
for (Method declaredMethod : declaredMethods) {
System.out.println(declaredMethod);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
使用反射调用类中的方法
import java.lang.reflect.Method;
/**
* 演示: 使用反射调用类中的方法
*/
public class MethodDemo02 {
public static void main(String[] args) {
try {
Class<?> aClass = Class.forName("com.powernode.p1.Student");
Method sleepMethod = aClass.getDeclaredMethod("sleep", String.class);
// 调用方法
/*
* Object invoke(Object obj, Object... args): 调用方法
* 第一个参数:调用哪一个对象的方法
* 第二个参数:调用方法时参入的实参
* 返回值: 方法的返回值,如果方法是void,返回null
*
*/
sleepMethod.setAccessible(true);
Object obj = aClass.newInstance();
Object returnValue = sleepMethod.invoke(obj, "赵四");
System.out.println(returnValue);
} catch (Exception e) {
e.printStackTrace();
}
}
}
获取静态内部类与非静态内部类
import java.lang.reflect.Constructor;
import java.lang.reflect.Method;
import java.lang.reflect.Modifier;
public class Demo01 {
public static void main(String[] args) {
test01();
// test02();
}
// 演示静态内部类
private static void test02() {
// 获取外部类的Class
try {
Class<?> aClass = Class.forName("com.powernode.p5.Outter");
// 获取内部类的Class
Class<?>[] classes = aClass.getClasses();
for (Class<?> aClass1 : classes) {
int modifiers = aClass1.getModifiers();
if(Modifier.isStatic(modifiers)){
Method method = aClass1.getDeclaredMethod("run");
method.invoke(aClass1.newInstance());
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
// 演示非静态内部类
private static void test01() {
try {
// 获取外部类的Class
Class<?> aClass = Class.forName("com.powernode.p5.Outter");
// 获取内部类的Class
Class<?>[] classes = aClass.getClasses();
for (Class<?> aClass1 : classes) {
int modifiers = aClass1.getModifiers();
if(!Modifier.isStatic(modifiers)){
// aClass1.getDeclaredConstructor(Outter.class);
Constructor<?> declaredConstructor = aClass1.getDeclaredConstructor(aClass);
declaredConstructor.setAccessible(true);
Object obj = declaredConstructor.newInstance(aClass.newInstance());
Method method = aClass1.getDeclaredMethod("run");
method.invoke(obj);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
Outter类
public class Outter { public static class Inner01{ public void run(){ System.out.println("跑起来......"); } } // Outter$Inner02(Outter this$0) public class Inner02{ public void run(){ System.out.println("跑起来......"); } } }
自己写一个工具类
需求:写一个工具类,不能改变类的任何代码的前提下,可以帮我们创建 任意类 的对象,并执行其中任意无参方法。
import com.powernode.p1.Student; /** * 需求:写一个工具类,不能改变类的任何代码的前提下,可以帮我们创建 任意类的对象,并执行其中任意无参方法 */ public class Demo01 { public static void main(String[] args) { /* * 解耦: 降低耦合性 * * 现在这个代码的存储 编译期耦合 * * 降低: 将编译器耦合 降低 到运行时耦合 */ Student student = ObjectUtils.getInstance(Student.class); System.out.println(student); Object obj = ObjectUtils.getInstance(Object.class); System.out.println(obj); /* * 以下的代码降低了耦合度,编译期没有耦合了 * * 但是又有新的问题:"com.powernode.p1.Student" 写死了。也就是只能创建Student对象 * 这就是开发中的硬编码问题。 * 如何解决硬编码问题: * 使用配置文件 properties * * 配置 优于 编码 * 约定 优于 配置 */ Object obj01 = ObjectUtils.getInstance("com.powernode.p1.Student"); System.out.println(obj01); // 解决硬编码后 Object obj02 = ObjectUtils.getInstance(); System.out.println(obj02); // 执行方法 Object returnValue = ObjectUtils.invokeMethod(); System.out.println(returnValue); } }ObjectUtils工具类
import java.io.FileReader; import java.io.IOException; import java.lang.reflect.Constructor; import java.lang.reflect.InvocationTargetException; import java.lang.reflect.Method; import java.util.Properties; /** * 工具类: * 1. 创建任意类的对象 * 2. 执行其中任意无参方法 */ public class ObjectUtils { private ObjectUtils(){ } /** * 该方法的作用是创建任意类的对象 * 任意类,说明类是不固定的,所以目前我们能够想到的是通过参数接收类 * * 参数:接收任意类,所以参数类型是Class * * Object obj = 对象 */ public static <T>T getInstance(Class<T> clz){ T t = null; try { // 反射 Constructor<T> declaredConstructor = clz.getDeclaredConstructor(); declaredConstructor.setAccessible(true); t = declaredConstructor.newInstance(); } catch (Exception e) { e.printStackTrace(); } return t; } public static Object getInstance(String fqcn){ Object obj = null; try { // 反射 Class<?> aClass = Class.forName(fqcn); Constructor declaredConstructor = aClass.getDeclaredConstructor(); declaredConstructor.setAccessible(true); obj = declaredConstructor.newInstance(); } catch (Exception e) { e.printStackTrace(); } return obj; } /** * 读取配置文件中的类名创建对象 */ public static Object getInstance(){ Object obj = null; try { // 读取配置文件中的类名 Properties prop = new Properties(); prop.load(new FileReader("day26/bean.properties")); String className = prop.getProperty("className"); // 反射 Class<?> aClass = Class.forName(className); Constructor declaredConstructor = aClass.getDeclaredConstructor(); declaredConstructor.setAccessible(true); obj = declaredConstructor.newInstance(); } catch (Exception e) { e.printStackTrace(); } return obj; } /** * 通过配置文件执行指定的无参方法 */ public static Object invokeMethod(){ try { Properties prop = new Properties(); prop.load(new FileReader("day26/bean.properties")); String className = prop.getProperty("className"); String methodName = prop.getProperty("methodName"); Class<?> aClass = Class.forName(className); Method declaredMethod = aClass.getDeclaredMethod(methodName); declaredMethod.setAccessible(true); return declaredMethod.invoke(aClass.newInstance()); } catch (Exception e) { e.printStackTrace(); } return null; } }bean.properties
# \u914D\u7F6E\u9700\u8981\u521B\u5EFA\u5BF9\u8C61\u7684\u7C7B className=com.powernode.p1.Student methodName=eat
将任意对象的数据保持成properties文件
import java.io.FileWriter;
import java.lang.reflect.Field;
import java.util.Properties;
/**
* 需求: 将任意对象的数据保存成properties文件
*
* Student stu = new Student("zhansgan",22);
*
* properties文件:
* name=zhangsan
* age=22
*/
public class Demo01 {
public static void main(String[] args) {
Student student = new Student("张三", 22, "男");
objectToProperties(student);
}
public static void objectToProperties(Object obj){
/*
* properties文件中需要对象的字段和字段值组成
* 所以我们需要得到对象的字段和值
* -- 使用反射
*/
Properties properties = new Properties();
Class<?> aClass = obj.getClass();
Field[] fields = aClass.getDeclaredFields();
try {
for (Field field : fields) {
// 获取字段的名称
String fieldName = field.getName();
// 获取字段的值
field.setAccessible(true);
Object value = field.get(obj);
properties.setProperty(fieldName,String.valueOf(value));
}
// 将properties持久化
properties.store(new FileWriter("day26/" + aClass.getSimpleName()+".properties"),"自动生成的文件");
} catch (Exception e) {
e.printStackTrace();
}
}
}
Student类
public class Student { private String name; private int age; private String sex; public Student() { } public Student(String name, int age, String sex) { this.name = name; this.age = age; this.sex = sex; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getSex() { return sex; } public void setSex(String sex) { this.sex = sex; } }
类加载器:加载字节码文件信息,创建出Class对象
public class Student {
private String name;
private int age;
private String sex;
public Student() {
}
public Student(String name, int age, String sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
}
使用泛型调用add
import java.lang.reflect.Method;
import java.util.ArrayList;
import java.util.List;
public class Demo02 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
// 使用泛型调用add
try {
Class<? extends List> aClass = list.getClass();
Method addMethod = aClass.getDeclaredMethod("add", Object.class);
addMethod.setAccessible(true);
addMethod.invoke(list,100);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(list);
}
}
注解(Annatation)
/**
* 1. 注解(Annotation):
*
* 注释:解释说明代码的 -- 给程序员看的
* 注解:解释说明代码的 -- 给程序看的
*
* 注解也是一个接口。
*
* 2. 注解的语法格式
*
* 元注解
* public @interface 注解名{
* 属性;
* }
*
* 3. 注解如何使用呢?
* 在使用注解的地方直接贴上就好
*
* 所以注解可以理解成类似标签
*
* 注解也叫作元数据。
* 元数据: 描述数据的数据。
*
*
* 3. 注解的属性
* 注解的本质是接口,注解是jdk1.5出现的,所以注解使用的是1.5时候的接口。
* 1.5的接口只有常量值和抽象方法。也就是注解中的属性要么是常量值;要么是抽象方法来表示。
* 属性的值是可以变化的,所以不能使用常量值表示,所以只能使用抽象方法来表示。
*
* 结论: 注解中的属性是抽象方法.
*
* 方法名就是属性名
* 方法的返回值类型就是 属性的数据类型
*
* 注解中属性的数据类型只能是:
* 1. 基本数据类型
* 2. String
* 3. 枚举
* 4. 注解
* 5. Class
* 6. 以上类型的数组
*
* 4. 属性的使用细节:
* 4.1 属性可以有默认值;如果属性有默认值,那么使用注解的时候,该属性可以不用显式赋值
* 4.2 如果属性的名称叫做value,那么如果使用注解的时候,只单独使用value属性,属性名可以省略不写;但是如果使用多个属性时候,value
* 也不能省略
* 4.3 注解中数组使用{}表示;使用注解的时候,如果{}中只有一个值,{}可以省略
* 4.4 使用注解时,多个属性之间使用逗号分割
*/
/*
* @MyAano(name = "zhangsan") 本质就是 接口的实现类并重写方法
*
* class Proxy$1 implements MyAano{
* public String name(){
* return "zhangsan";
* }
*
* public int age(){
* return 18;
* }
* }
*
*/
//@MyAano(hobbies = "抽烟")
@MyAano(hobbies = {"抽烟","喝酒"})
public class Demo01 {
public static void main(String[] args) {
}
}
MyAano.java
/** * 通过反编译后得到: * public interface MyAano extends Annotation{ * } * * 所以,注解的本质就是一个接口 */ public @interface MyAano { /* * 属性:注解中的属性是抽象方法. * * 方法名就是属性名 * 方法的返回值类型就是 属性的数据类型 * */ String name() default ""; int age() default 20; String value() default ""; String[] hobbies() default {}; }
元注解
import java.lang.annotation.*;
/**
* 元注解:就是用来标记注解的注解
*
* jdk内置的元注解:
* 1. @Target 表示注解可以在哪些地方使用
* ElementType.PARAMETER 方法中的形参
* ElementType.TYPE_PARAMETER 泛型的形参
*
* 2. @Retention 表示注解可以保留到什么阶段
* SOURCE: 表示注解只会保留在源码阶段,编译器会丢弃该注解
* CLASS:表示注解可以保留到字节码文件中,但是运行时没有;这是默认的保留策略。
* RUNTIME:表示注解可以保留到字节码文件和运行时,所以可以使用反射读取该注解
*
* 开发中我们自己定义的注解都要保留到RUNTIME,以便使用反射获取。
*
* 3. @Documented 表示注解可以生成到javadoc文档中
*
* 4. @Inherited
* Inherited 是继承的意思,但是它并不是说注解本身可以继承,
* 而是说如果一个超类被 @Inherited 注解过的注解进行注解的话,
* 那么如果它的子类没有被任何注解应用的话,那么这个子类就继承了超类的注解。
*
* 5. @Repeatable
* Repeatable 可重复的意思。@Repeatable 是 Java 1.8 才加进来的,所以算是一个新的特性。
*/
@Target({ElementType.TYPE,ElementType.METHOD,ElementType.CONSTRUCTOR,ElementType.PARAMETER,ElementType.TYPE_PARAMETER,ElementType.TYPE_USE,ElementType.LOCAL_VARIABLE,ElementType.PACKAGE})
//@Target({ElementType.TYPE,ElementType.METHOD,ElementType.PARAMETER})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Check {
}
eg:
@Check public class Demo02<@Check T> { @Check public Demo02() { } @Check public static void main(@Check String[] args) { Demo02<@Check Integer> demo02 = new Demo02<>(); demo02.m01(); } public void m01(){ @Check int num = 10; System.out.println(num); } }
repeatable举例
@Person(role = "coder")
@Person(role = "PM")
@Person(role = "artist")
public class SuperMan {
}
PersonList.java
import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; /** * 该注解用来作为Person注解的容器注解 * 1. 容器注解的属性名必须是value * 2. 容器注解必须和里面的元素注解的Target、Retention保持一致 * */ @Target(ElementType.TYPE) @Retention(RetentionPolicy.RUNTIME) public @interface PersonList { Person[] value(); }Person.java
import java.lang.annotation.*; @Target(ElementType.TYPE) @Retention(RetentionPolicy.RUNTIME) @Repeatable(PersonList.class) public @interface Person { String role(); }
unrepeatable举例
@Person(role = {"coder","PM","artist"})
public class SupperMan {
}
- Person.java
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface Person {
String[] role();
}
java预置的注解
import java.util.Date;
/**
* Java 预置的注解
*
* 1. @Deprecated 表示过时的
* 2. @SuppressWarnings 抑制警告
* 3. @Override 检测方法重写的
* 4. @FunctionalInterface 表示函数式接口。lambda表达式再讲
*
* 函数式接口: 只有一个抽象方法的接口。
*
*
* 注解的作用:
* 1. 编译器检测代码
* 2. 生成文档
* 3. 简化代码 --- 我们编写注解的目的
* 一般用来简化 配置文件
*
*
* 定义完注解后,必须使用反射为其提供功能,否则注解没有任何作用
*
* 注解类似于我们生活中的“章”;今天我去刻一个一个 清华大学的章 盖在我的毕业证上
* 此时这个章是没有功效的。
*
* 因为这个章没有教育部门赋予其功能,也就说你在学信网查不到。
*
*/
@SuppressWarnings("all")
class A{
@Deprecated
public static void show(){
System.out.println("a-------------");
}
}
@SuppressWarnings("all")
public class Demo01 {
public static void main(String[] args) {
new Date().getMinutes();
A.show();
}
}

