MySQL数据库
数据库:存储数据的仓库
之前我们可以使用数组、集合、IO存储数据。其中数组和集合的数据在内存中,IO可以将数据持久化存储。
我们在实际开发中很多业务是需要将数据持久化的,此时使用IO将数据存储成一个普通的文件行不行?
可以,但是不高效。比如我们将用户的数据存储成一个txt文件:
1000 张三 20 男 北京 海淀区
1002 李四 21 男 上海 浦东区
1003 韩梅梅 22 女 成都 武侯区
.....此时如果我们需要查询年龄大于21岁的用户有哪些。我们需要将文本中的每一行信息读取出来,然后按照空格分割,得到age字符串,再将字符串转成int,然后做比较。这样操作会发现数据越多处理效率越低。
如果我们需要将1003的地址修改成重庆 渝北区,发现需要将数据全部读取,修改后的数据重新覆盖整个旧文件,依然效率低下。
以上的操作之所以效率低下,是因为我们存储数据的数据结构没有专门的进行设计,就是一个普通的文本文件,所有数据在一起,全部是String。
为了解决在实际开发中操作数据的高效问题,就产生了数据库这种产品。数据库也是将数据持久化存储成多个文件,这些文件都是经过专门的设计的,底层有专门的数据结构来存储数据,所以我们直接打开数据库的数据文件是看不懂的,只有数据库软件可以读取。
数据库:高效存储和操作数据的仓库
MySQL相关的概念

数据库的分类
一、关系型数据库
关系型数据库就是由二维表及其之间的关系组成的一个数据组织。
常见的关系型数据库
- Oracle- 甲骨文
- DB2 - IBM
- MySQL - 甲骨文
- SQLServer - 微软
- SQLite - 移动端
二、非关系型数据库 - NoSQL
NoSQL = Not Only SQL
不是二维表结构,表之间也没有关系,无模式
常见的非关系型数据库
- Redis – kv格式的数据库
- MongoDB – 文档型数据库
- HBase – 列族式数据库
MySQL下载和安装
下载地址:https://dev.mysql.com/downloads/windows/installer/5.7.html
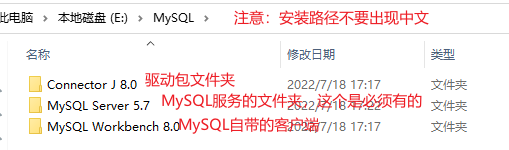
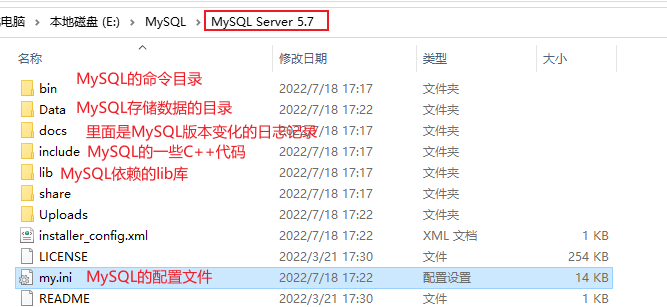
MySQL安装文件夹介绍
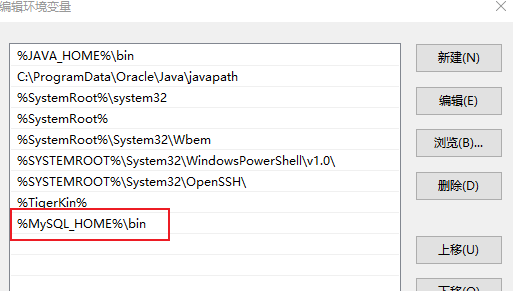
配置MySQL环境变量

验证环境变量是否成功:

MySQL客户端
DOS窗口 (需要使用命令)
# -h 表示MySQL安装的主机名 # -P 表示MySQL的端口号 # -u 表示MySQL的用户名 # -p 表示MySQL用户的密码 C:\Users\NINGMEI>mysql -hlocalhost -P3306 -uroot -p123456 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. mysql> exit Bye如果连接数据库的时候使用的是
-hlocalhost -P3306,那么-h和-P可以省略C:\Users\NINGMEI>mysql -uroot -p123456 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 6以上的写法不安全,密码明文显示了。
# 推荐使用 C:\Users\NINGMEI>mysql -uroot -p Enter password: ****** Welcome to the MySQL monitor. Commands end with ; or \g.自带的workbench
第三方的客户端 (Navicat)
SQL语句
MySQL数据库中使用的语言是SQL语句,所以我们要想操作MySQL数据库就需要学习SQL语句。
SQL:结构化查询语言(Structured Query Language)
标准SQL:在关系型数据库中都可以使用
方言SQL: 只能本数据库中使用
MySQL中SQL语句关键字推荐使用大写
SQL分类
- DDL语句 - 数据定义语言(data definition language)
- 作用:操作数据库相关对象(数据库、表、索引、视图等)
- 代表性的关键字:create(创建)、alter(修改)、drop(删除)
- DML语句 - 数据操作语言(Data Manipulation Language)
- 作用:对表中的数据进行增加、删除、修改
- 代表性的关键字:insert(增加)、delete(删除)、update(修改)
- DQL语句 - 数据查询语言(data query language)
- 作用:查询表中的数据
- 代表性的关键字:select(查询)
- TCL语句 - 事务控制语句(Transaction Control language)
- 作用:事务的操作
MySQL的数据类型
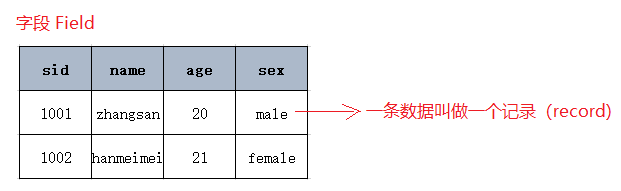
MySQL的数据类型就是字段的数据类型。
数字类型
整型(精确值)
Type Storage (Bytes) Minimum Value Signed(有符号) Minimum Value Unsigned(无符号) Maximum Value Signed Maximum Value Unsigned TINYINT1 -1280127255SMALLINT2 -3276803276765535MEDIUMINT3 -83886080838860716777215INT4 -2147483648021474836474294967295BIGINT8 -2^6302^63-12^64-1浮点型(近似值)
- float 单精度,占4个字节
- double 双精度,占8个字节
- MySQL支持非标准的SQL: FLOAT(
M,D),DOUBLE(M,D)- M表示总的数字位数
- D表示小数位数,如果小数位超出了D的范围,会四舍五入。但是四舍五入后整数必须满足M的范围,否则出错
定点型(精确值)
- DECIMAL(M,D)
- M表示总的数字位数
- D表示小数位数
- DECIMAL(M,0) 等价于DECIMAL(M)。就是个整数
- 注意:涉及到计算钱的时候,就必须使用定点型
- DECIMAL(M,D)
字符串类型
- 定长字符串:char(n),n表示字符的数量
- 例如,
CHAR(30)最多可容纳 30 个字符 - n的取值范围0-255个字符
- 定长指的是,插入的数据长度小于n,尾部会使用空格将长度填充到n
- 弊端:浪费空间;优点:效率高 (以空间换时间)
- 例如,
- 可变字符串: varchar(n),n表示字符的数量
- 例如,
VARCHAR(30)最多可容纳 30 个字符 - n的取值范围0-65535个字节**(受到行大小(65535字节)的限制)**
- 可变的意思是,varchar中的数据占据的真实数据的长度的空间,不足n也不会使用空格填充
VARCHAR值存储为 1 字节或 2 字节长度前缀加上数据。长度前缀表示值中的字节数。如果值需要不超过 255 个字节,则一列使用一个长度字节,如果值可能需要超过 255 个字节,则使用两个长度字节。- 优点:节约空间;弊端:效率低(以时间换空间)
- varchar字符数= (65535 - 每个字段占据的内存大小 - 2 字节长度前缀 - 1字节空值) / 字符集中单个字符的最大长度
- 例如,
- 文本类型 - Text
- Text类型的数据只有9-12个字节和其他的字段共享行大小(65535字节)
- Text的数据部分是单独存储的,所以Text类型的数据大小不受到行大小(65535字节)的限制
日期时间类型
- date: 日期类型
- 只有年月日
- 取值范围:
'1000-01-01'to'9999-12-31'.
- time: 时间类型
- 只有时分秒
- 取值范围:’-838:59:59’
to‘838:59:59’ - time不仅表示时间,还表示时间的间隔
- year: 年
- 只有年份
- 四位的年份取值范围:’1901’
to‘2155’
- datetime:日期时间类型
- 有年月日时分秒
- 取值范围:
'1000-01-01 00:00:00'to'9999-12-31 23:59:59'. - 值不受时区的影响
- timestamp: 时间戳
- 有年月日时分秒
- 取值范围:1970-01-01 00:00:01’
UTC to‘2038-01-19 03:14:07’ - 值受时区的影响
- 我们处于东八区,要更改为西巴区就 +8:00 小时。
-- 创建表
create table if not exists db01.test(
name varchar(20),
info text,
time1 datetime,
time2 timestamp
);
# 更改时区为西八区
set time_zone="-08:00";
select * from db01.test;DDL语句
创建数据库
# {} 表示必须要的内容
# | 表示或
# [] 表示可选
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_option] ...
create_option: [DEFAULT] {
CHARACTER SET [=] charset_name
| COLLATE [=] collation_name
}-- --和#表示注释信息
# --和文字之间必须有空格
# 创建数据库
# 如果数据库不存在就创建,存在就不做操作
# 数据库默认的字符集是 latin1,不能存储中文
create database if not exists db01;
# 创建数据库的时候指定字符集为utf8
create database if not exists db02 character set utf8;
# 创建数据库的时候指定字符集为utf8,指定排序规则为utf8_bin
create database if not exists db03 character set utf8 collate utf8_bin;修改数据库
ALTER {DATABASE | SCHEMA} [db_name]
alter_option ...
alter_option: {
[DEFAULT] CHARACTER SET [=] charset_name
| [DEFAULT] COLLATE [=] collation_name
}-- 切换(使用)数据库
use db01;
-- 修改数据库的字符集
# 将db01的字符集修改成utf8
# 没有指定utf8的排序规则,默认就是utf8_general_ci
alter database db01 character set utf8;删除数据库
DROP {DATABASE | SCHEMA} [IF EXISTS] db_name-- 删除数据库
-- 如果数据库存在就删除,不存在就不做处理
drop database if exists db01;
drop database if exists db02;创建数据表
CREATE TABLE [IF NOT EXISTS] tbl_name
(create_definition,...)
[table_options]
CREATE TABLE [IF NOT EXISTS] tbl_name
[(create_definition,...)]
[table_options]
[AS] query_expression
CREATE TABLE [IF NOT EXISTS] tbl_name
{ LIKE old_tbl_name | (LIKE old_tbl_name) }
create_definition: {
col_name column_definition
| {INDEX | KEY} [index_name] [index_type] (key_part,...)
[index_option] ...
| [CONSTRAINT [symbol]] PRIMARY KEY
[index_type] (key_part,...)
[index_option] ...
| [CONSTRAINT [symbol]] UNIQUE [INDEX | KEY]
[index_name] [index_type] (key_part,...)
[index_option] ...
| [CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (col_name,...)
reference_definition
}
column_definition: {
data_type [NOT NULL | NULL] [DEFAULT default_value]
[AUTO_INCREMENT] [UNIQUE [KEY]] [[PRIMARY] KEY]
[COMMENT 'string']
}
reference_definition:
REFERENCES tbl_name (key_part,...)
[ON DELETE reference_option]
[ON UPDATE reference_option]
reference_option:
RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT
table_options:
table_option [[,] table_option] ...
table_option: {
AUTO_INCREMENT [=] value
| [DEFAULT] CHARACTER SET [=] charset_name
| [DEFAULT] COLLATE [=] collation_name
| COMMENT [=] 'string'
| ENGINE [=] engine_name
}
query_expression:
SELECT ... (Some valid select or union statement)# 创建学生表
create table if not exists db01.student(
-- 数据库中除了数字外,其余类型的值都是用单引号或双引号引起来
uid int comment "学号",
`name` char(4) comment "姓名",
-- unsigned 表示无符号 --> 年龄是正数
age tinyint unsigned comment "年龄",
-- 最后一个字段没有逗号
sex char(2) comment "性别",
-- 建议在开发中给自己表添加'创建时间'和'更新时间'
create_time datatime comment '创建时间',
update_time datatime comment '更新时间'
)comment="学生表";
-- 查看建库语句
show create database db01;
-- 查看建表语句
show create table db01.student;修改数据表
ALTER TABLE tbl_name
[alter_option [, alter_option] ...]
alter_option: {
table_options
| ADD [COLUMN] col_name column_definition
[FIRST | AFTER col_name]
| ADD [COLUMN] (col_name column_definition,...)
| ADD {INDEX | KEY} [index_name]
[index_type] (key_part,...) [index_option] ...
| ADD [CONSTRAINT [symbol]] PRIMARY KEY
[index_type] (key_part,...)
| ADD [CONSTRAINT [symbol]] UNIQUE [INDEX | KEY]
[index_name] [index_type] (key_part,...)
[index_option] ...
| ADD [CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (col_name,...)
reference_definition
| ALTER [COLUMN] col_name {
SET DEFAULT {literal | (expr)}
| DROP DEFAULT
}
| CHANGE [COLUMN] old_col_name new_col_name column_definition
[FIRST | AFTER col_name]
| DROP [COLUMN] col_name
| DROP {INDEX | KEY} index_name
| DROP PRIMARY KEY
| DROP FOREIGN KEY fk_symbol
| MODIFY [COLUMN] col_name column_definition
[FIRST | AFTER col_name]
| RENAME {INDEX | KEY} old_index_name TO new_index_name
| RENAME [TO | AS] new_tbl_name
}
table_options:
table_option [[,] table_option] ...
table_option: {
AUTO_INCREMENT [=] value
| [DEFAULT] CHARACTER SET [=] charset_name
| [DEFAULT] COLLATE [=] collation_name
| COMMENT [=] 'string'
| ENGINE [=] engine_name
}-- 在student表中添加address字段
alter table db01.student add address varchar(20) not null;
-- 在student表中添加score字段在sex字段之后
alter table db01.student add score int after sex;
-- 将student表中的uid字段设置成主键
alter table db01.student add primary key(uid);
-- 将student表中的sex字段改成gender
-- change 主要用于修改字段的名称
alter table db01.student change sex gender char(2);
-- 将student表中的uid主键设置成自增
alter table db01.student change uid uid int auto_increment;
-- 将student表中的gender修改成varchar(3)
-- modify更改字段的其他信息,除了名字
alter table db01.student modify gender varchar(3);
-- 删除student表中的address
alter table db01.student drop address;
-- 删除student表中的name字段的unique索引
alter table db01.student drop index name_key;
-- 删除student表中的主键
-- 删除主键之前需要先取消自增
-- 先取消自增
alter table db01.student modify uid int;
-- 删除主键
alter table db01.student drop primary key;
-- 将student表名修改成t_student
alter table db01.student rename to t_student;RENAME TABLE 语句
RENAME TABLE
tbl_name TO new_tbl_name
[, tbl_name2 TO new_tbl_name2] -- 将t_student表名修改成student
rename table t_student to student;删除数据表
DROP TABLE [IF EXISTS]
tbl_name [, tbl_name] ...
[RESTRICT | CASCADE]-- 删除表
drop table if exists student,student01,student02,student03;TRUNCATE TABLE 语句
TRUNCATE [TABLE] tbl_name-- truncate清空数据
-- 1.先将数据表删除
-- 2.创建一张空表
truncate table student04;字段约束
字段约束的作用就是对字段的值进行限制,保证数据的安全性和完整性。
主键约束-primary key
- 一张表只能有一个主键
- 主键的值唯一且非空的
-- 创建学生表01
create table if not exists db01.student01(
-- uid设置成主键
-- primary key 表示主键, primary key在建表语句中只能出现一次
uid int primary key,
name char(10),
age int
);以上的方式只能将一个字段设置成主键。开发中有时候我们需要将多个字段组合成一个主键,这种主键叫做复合主键。
复合主键需要使用以下的方式设置:
-- 创建学生表02
create table if not exists db01.student02(
uid int,
name char(10),
age int,
-- 复合主键,主键只有一个,只是这个主键是由两个字段组成的
primary key(uid,name)
);- 如果主键字段的数据类型是数字类型,可以使用自动增长(auto_increment)
-- 创建学生表03
create table if not exists db01.student03(
-- 设置主键并自增,自增初始化是1
uid int primary key auto_increment,
name char(10),
age int
);
-- 创建学生表04
create table if not exists db01.student04(
-- 设置主键并自增
uid int primary key auto_increment,
name char(10),
age int
-- 更改自增的初始值为1000
)auto_increment=1000;注意:自增字段的值只会自增。当删除自增字段已自增的记录后,下一个自增字段值不会改变,依然是“数值+1”。
在开发中推荐使用一个跟业务无关的字段作为主键。
唯一性约束 - unique
- 字段的值不能有重复的
- 允许为null,且null值不受唯一性约束
- 一张表可以有多个唯一性约束
-- 创建学生表05
create table if not exists db01.student05(
-- 设置主键并自增
uid int primary key auto_increment,
-- name必须唯一
name char(10) unique,
age int
);非空约束 - Not Null
- 值不能为null
-- 创建学生表06
create table if not exists db01.student06(
-- 设置主键并自增
uid int primary key auto_increment,
-- name必须唯一且不能为null
name char(10) unique not null,
age int
);
-- 查看表的信息
mysql> desc student06;
+-------+----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+----------------+
| uid | int(11) | NO | PRI | NULL | auto_increment |
| name | char(10) | NO | UNI | NULL | |
| age | int(11) | YES | | NULL | |
+-------+----------+------+-----+---------+----------------+unique not null 和primary key的区别:
- primary key 一张表只能有一个
- unique not null 一张表可以有多个
默认值约束 - default
- 可以给字段设置默认值
-- 创建学生表08
create table if not exists db01.student08(
uid int,
-- name必须唯一且不能为null
name char(10) unique not null default "",
age int,
-- 设置字段的默认值
sex char(6) default 'male'
);外键约束 - 后面讲
显示宽度
create table if not exists db01.student09(
-- 3表示的是显示宽度,需要配合零填充才有效果
uid int(3) zerofill,
name char(10) unique not null default "",
age int,
sex char(6) default 'male'
);DML语句
DML语句操作的数据表中的数据
插入语句-insert
INSERT [INTO] tbl_name
[(col_name [, col_name] ...)]
{VALUES | VALUE} (value_list) [, (value_list)] ...
INSERT [INTO] tbl_name
[(col_name [, col_name] ...)]
SELECT ...
value_list:
value [, value] ...
value:
{expr | DEFAULT}-- 创建学生表
create table if not exists student (
_id bigint primary key auto_increment,
sid int unsigned not null unique,
name varchar(12) not null,
gender char(6) default 'male',
province text,
create_time datetime,
update_time datetime
);
-- 插入一条数据
insert into student (_id,sid,name,gender,province,create_time,update_time)
values (1,1001,'zhangsan','male','四川省','2022-03-30 17:22:10','2022-03-30 17:22:10');
-- 插入多条数据
insert into student (_id,sid,name,gender,province,create_time,update_time)
values (2,1002,'lisi','male','四川省','2022-03-30 17:25:10','2022-03-30 17:25:10'),
(3,1003,'hanmeimei','male','重庆市','2022-03-30 17:25:10','2022-03-30 17:25:10');
-- 插入数据的时候,如果是插入全部字段的数据,字段可以不写
insert into student
values (4,1004,'zhaosi','male','四川省','2022-03-30 17:25:10','2022-03-30 17:25:10'),
(5,1005,'liuneng','male','重庆市','2022-03-30 17:25:10','2022-03-30 17:25:10');
-- 插入部分字段的数据,字段不可以省略
-- 非空字段必须插入值,除非有默认值
insert into student (sid,name) values (1006,'test');
-- 有默认值的字段,插入数据的时候可以使用default表示默认值
insert into student (sid,name,gender) values (1007,'test01',default);
-- 插入数据的时候,自增的主键可以使用0或null
insert into student (_id,sid,name) values (0,1008,'test02');
insert into student (_id,sid,name) values (null,1009,'test03');更新语句-update
UPDATE tableName
SET assignment_list
[WHERE where_condition]
[LIMIT row_count]
assignment_list:
assignment [, assignment] ...
assignment:
col_name = value
value:
{expr | DEFAULT}## 将student表中的性别修改成female
## 修改所有行的数据
update student set gender = 'female';
## 修改前三行的数据
update student set gender = 'male' limit 3;
## 将student中sid为1006的gender修改成male
## where子句进行条件过滤
update student set gender = 'male' where sid = 1006;
## 有默认值的字段赋值的时候可以使用default
update student set gender = default where sid = 1008;删除语句-delete
单表语法:
DELETE FROM tbl_name
[WHERE where_condition]
[LIMIT row_count]多表语句:– 了解
DELETE tbl_name[.*] [, tbl_name[.*]] ...
FROM table_references
[WHERE where_condition]
DELETE FROM tbl_name[.*] [, tbl_name[.*]] ...
USING table_references
[WHERE where_condition]-- 删除student表的所有数据,属于DML
-- 逐行删除
delete from student;
-- 删除表再新建一张空表,属于DDL
truncate table student;
-- 使用where过滤指定的数据
delete from student where sid = 1009;
-- 删除student表的所有数据
delete student.*
from student;
-- 删除多张表 -- 了解
-- 92语法: using后面多张表使用逗号
delete from db01.student,db01.student01 using student,student01;表关系
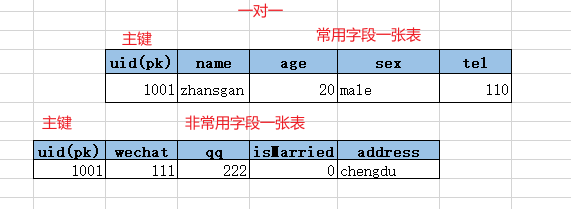
一对一: 一张表中的一行数据只会对应另外一张表的一行数据
一对多/多对一:一张表中一行数据对应另外一张表中的多行数据
比如班级和学生、员工和部门
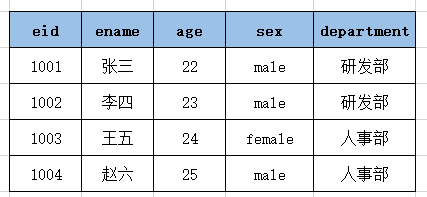
以上设计的表有问题:
- 部门数据冗余,浪费空间
- 如果现在部门名称发生变更,那么以上表中的数据就要将该部门的所有员工数据进行更新,效率也不高
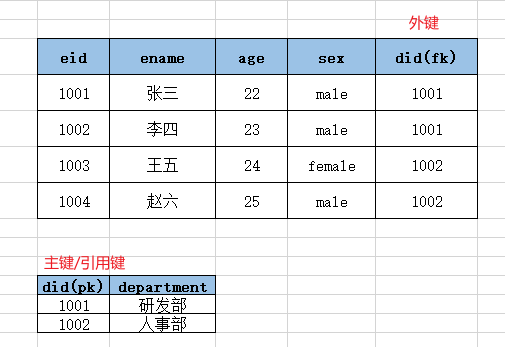
所以我们需要将以上的表进行拆分,以上的表是一对多/多对一的关系,所以我们拆成两张表:
拆分规则:
- 将一的方拆成一张表(部门表)
- 将多的一方也拆成一张表(员工表)
- 多的一方添加外键,引用少的一方的主键字段
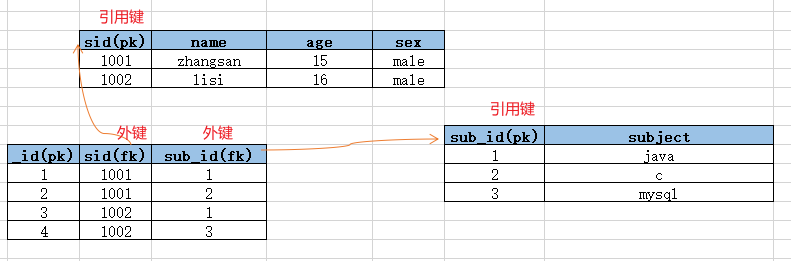
多对多:表1中一行数据对应表2中的多行数据,表2中一行数据对应表1中的多行数据
学生和老师或者学生和科目

以上设计的表,数据冗余了。所以需要拆表。以上表的关系是多对多的关系,所以拆分规则如下:
- 将两边多的一方都拆成一张独立表(就有两张表了)
- 创建一张中间关系表,关系表中使用以上两张表的主键作为外键字段
外键约束 - foreign key
外键:就是外部的键。也就是该字段的内容来自其他表。
外键的作用
保证数据的一致性和完整性、安全性。有了外键约束后字段的数据就不能乱写了。
一对多的外键约束
-- 创建部门表
create table dept(
did int primary key,
name char(10)
);
-- 创建员工表
create table emp(
eid int primary key,
name char(10),
age tinyint,
sex char(6),
did int,
-- 约束 约束名 外键 外键字段 引用 表 引用字段
constraint fk_emp_dept_did foreign key (did) references dept(did)
);
父表:被外键引用的表叫做父表。(上面的部门表就是父表)
子表:有外键的表。(上面的员工表就是子表)
多对多关系的外键创建
-- 创建学生表
create table t_stu(
sid int primary key,
name char(10),
age int,
sex char(10)
);
-- 创建学科表
create table t_subject(
sub_id int primary key,
sname char(10)
);
-- 创建学生和学科的关系表
create table t_stu_sub_rel(
_id int primary key,
sid int,
sub_id int,
foreign key (sid) references t_stu(sid),
foreign key (sub_id) references t_subject(sub_id)
);外键的注意事项
- 外键引用表中的引用字段必须具备唯一性
- 外键字段和引用字段的数据类型要一致,数值类型长度和符号要一致。字符串类型长度可以不一样
- 建议:外键字段和引用字段的数据类型一致,长度也一致
- 删除表,需要先删除子表,再删除父表
- 父子表必须使用相同的存储引擎,不能定义为临时表。
- 虚拟表(dual)
DQL语句⭐⭐⭐
DML语句操作会修改原始数据;返回的是多少行受影响。
DQL语句不会修改原始数据;返回的是查询到的结果集,是一张虚拟表。
SELECT
[ALL | DISTINCT ]
select_expr [, select_expr] ...
[FROM table_references]
[WHERE where_condition]
[GROUP BY {col_name}
[HAVING where_condition]
[ORDER BY {col_name}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[FOR UPDATE]单表查询
-- 查询student表的所有数据
-- select 返回的是虚拟表,数据在内存中
-- select 后面跟的字段叫做投影(project)字段
-- 投影字段:也就是虚拟表中需要显示的字段
-- * 表示所有的字段,也就是投影所有的字段
select * from student;
-- 下面的语句表示只投影nane和gender
-- 虽然只投影了name和gender,但是其他的所有字段也在内存中
select name,gender from student;
-- 查找性别是male的学生的名字和性别
select name,gender from student where gender ='male';
-- select语句不会修改原始数据
select sid+1000,name,gender from student;
-- as 给字段取别名,as可以省略
select sid as id ,name,gender from student;
-- distinct前面不能再写投影字段
-- 按照job字段的值去重
select distinct job from emp;
-- 按照job+ename的值去重
select distinct job,ename from emp;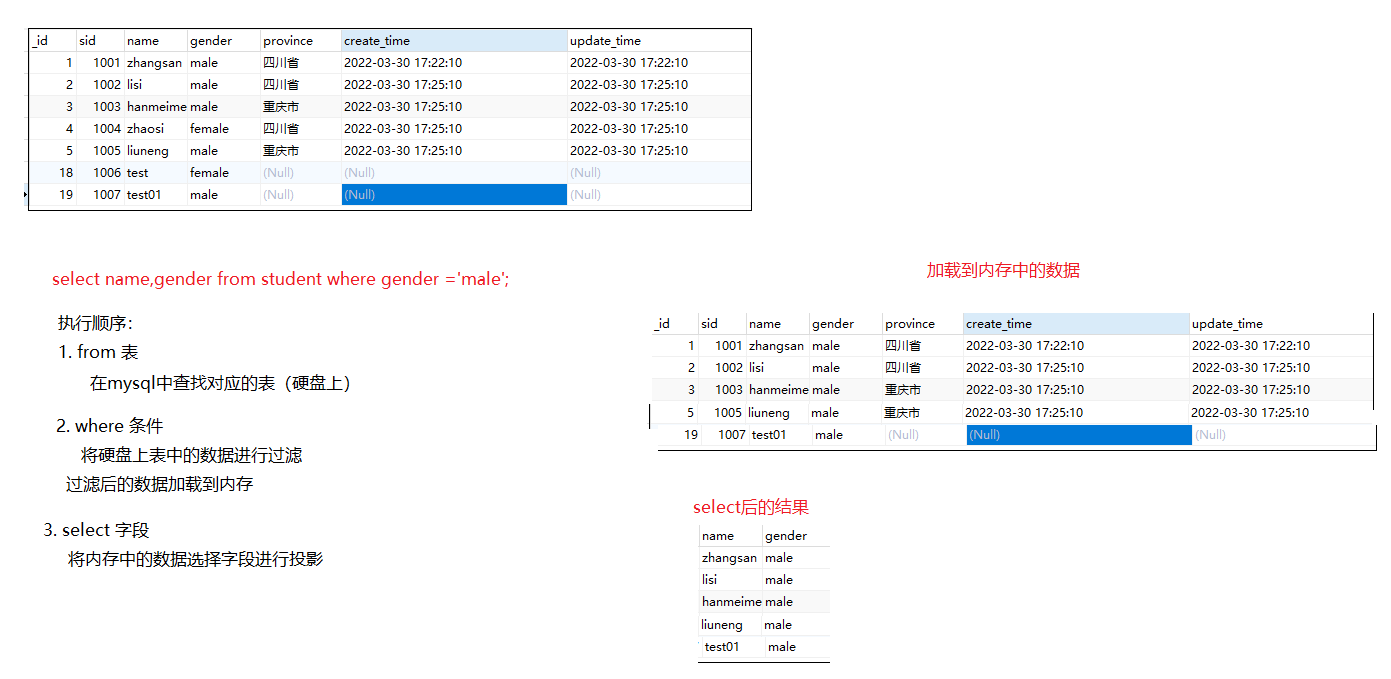
单行函数和操作符
比较函数和操作符
| Name | 描述 |
|---|---|
> |
大于运算符 |
>= |
大于或等于运算符 |
< |
小于运算符 |
<>,!= |
不等于运算符 |
<= |
小于或等于运算符 |
<=> |
NULL 安全等于运算符 |
= |
等号运算符 |
BETWEEN ... AND ... |
一个值是否在一个值范围内 |
IN() |
一个值是否在一组值内 |
IS NOT NULL |
NOT NULL 值测试 |
IS NULL |
空值测试 |
ISNULL() |
测试参数是否为 NULL |
LIKE |
简单的模式匹配 |
NOT BETWEEN ... AND ... |
值是否不在值范围内 |
NOT IN() |
一个值是否不在一组值内 |
NOT LIKE |
简单模式匹配的否定 |
STRCMP() |
比较两个字符串 |
在MySQL中可以使用<>和!=表示不等于。但是!=是编程语言中使用的,MySQL兼容了。真正MySQL的不等于是<>。
-- 查询不是四川省的学生信息
select * from student where province != "四川省";
select * from student where province <> "四川省";<=>null安全等于操作符
-- 查询省份是null的学生信息
-- <=>是MySQL的SQL方言
select * from student where province <=> null;
-- 查询省份是null的学生信息
select * from student where province is null;
-- 查询省份不是null的学生信息
select * from student where province is not null;-- 查询年龄大于等于22小于等于25的学生信息
-- between 22 and 25 : 大于等于22小于等于25
select * from student where age between 22 and 25;
-- 查询年龄是21,23,25的学生信息
-- age in(21,23,25) 表示age等于()中的任何一个值
select * from student where age = 21 or age = 23 or age = 25;
select * from student where age in(21,23,25);
-- where后面的表达式结果是boolean
-- 查询age是null的信息
-- is null是操作符
select * from db02.student where age is null;
-- isnull()是函数
select * from db02.student where isnull(age);
select isnull(10); -- mysql中0可以表示false
select isnull(null); -- mysql中1可以表示true,非0都是true
-- 查询姓张的学生
-- like 模糊查询
-- %表示0到多个字符
-- _表示1个字符
select * from student where name like '张%';
-- 查询名字是张x的学生
select * from student where name like '张_';
-- 查询姓名中包含张的学生信息
-- 注意:%或者_在最前面,索引就会失效
select * from student where name like '%张%';
-- 比较两个字符串
-- 0 表示相等
-- -1 表示小于
-- 1 表示大于
select strcmp("java","java"); -- 0
select strcmp("hello","java"); -- -1
select strcmp("zero","hello"); -- 1逻辑操作符
| Name | 描述 |
|---|---|
AND,&& |
逻辑与 |
NOT,! |
否定价值 |
[OR,` |
|
XOR |
逻辑异或 |
-- 查询年龄大于等于22小于等于25的学生信息
select * from student where age >= 22 and age <= 25;
select * from student where age >= 22 && age <= 25;
-- 查询年龄等于22或者等于25的学生信息
select * from student where age = 22 or age = 25;
select * from student where age = 22 || age = 25;
-- 查询姓名不姓张的学生信息
select * from student where name not like '张%';
-- 查询四川或重庆的女生
-- and和or同时存在,and的优先级高
select * from student where (province = '四川省' or province = '重庆市') and gender = 'female';XOR逻辑异或:如果任意一个操作数为NULL,则返回NULL。非空的操作数,相同为假,不同为真
mysql> SELECT 1 XOR 1;
-> 0
mysql> SELECT 1 XOR 0;
-> 1
mysql> SELECT 1 XOR NULL;
-> NULL
mysql> SELECT 1 XOR 1 XOR 1;
-> 1
-- 逻辑运算符连接的是boolean值
-- 非0 都表示真
SELECT 2 XOR 1 XOR 1; -- 1赋值运算符
| Name | 描述 |
|---|---|
:= |
赋值 |
= |
赋值(作为 SET 语句的一部分,或作为UPDATE语句中SET子句的 一部分) |
=号可以用作比较运算符,还可以作为赋值运算符
-- 赋值运算符
set time_zone = "-08:00";
update student set name = "不知道";
-- 与=不同,:= 运算符永远不会被解释为比较运算符
set time_zone := "+08:00";算术操作符
| Name | 描述 |
|---|---|
%,MOD |
模运算符 |
* |
乘法运算符 |
+ |
加法运算符 |
- |
减号运算符 |
- |
更改参数的符号 |
/ |
除法运算符 |
DIV |
整数除法 |
-- mysql中+用于数字计算,不能用于字符串拼接
-- 字符串做运算,会将字符串转成数字相加
-- 字符串不是数值类型,就不能转具体的数字,就会转成0
-- true表示1,false表示0
-- null和任何数做运算都是null
select "1"+"2"; -- 3
select "1" + 2; -- 3
select "a" + 2; -- 2
select "a" + "b"; -- 0
-- 如果是数字开头的字符串转数字,只能将非数字字符串前面的数字字符串转成数值型
select "2a" + "2b"; -- 4
select "2a2" + "2b2"; -- 4
select "a2" + 2; -- 2
select true + 2; -- 3
select false + 2; -- 2
select "a" + true; -- 1
select null + 2; -- null
select null + "a"; -- null
-- mysql中除数是0,结果为null
select 1 / 0; -- null
select -6 / 3; -- -2.0000
select -5 / 2; -- -2.5000
select -5 / -2; -- 2.5000
-- div 表示整除,也就是取结果的整数部分
-- MySQL中的div才相当于java中的/除法
select -6 div 3; -- -2
select -5 div 2; -- -2
select -5 div -2; -- 2
-- %结果的符号取决于被除数的符号
select 1 % 0; -- null
select 5 % 2; -- 1
select -5 % 2; -- -1
select -5 % -2; -- -1
select 5 % -2; -- 1数学函数
- abs(): 绝对值函数
- ceil():向上取整
- floor():向下取整
- round():四舍五入
- power(): 指数函数
- pi():圆周率函数
select abs(-110); -- 110
select ceil(-3.11); -- -3
select floor(-3.11); -- -4
-- 绝对值的四舍五入加负号
select round(-3.11); -- -3
select round(-3.45); -- -3
select round(-3.5); -- -4
select power(2,3); -- 8
select pi(); -- 3.141593流程控制函数
case语句
-- 类似于java中的switch CASE value WHEN compare_value THEN result [WHEN compare_value THEN result ...] [ELSE result] END -- 类似于java中的 if...else if CASE WHEN condition THEN result [WHEN condition THEN result ...] [ELSE result] END-- 查询学生的信息,如果是male返回帅哥,如果是female就返回美女 select name,gender, case gender when "male" then "帅哥" when "female" then "美女" else "人渣" end as info from student; -- 查询学生的信息,如果是male返回帅哥,如果是female就返回美女 select name,gender, case when gender = "male" then "帅哥" when gender = "female" then "美女" else "人渣" end as info from student;if语句
-- 类似于三目运算符 -- 如果expr1是TRUE (expr1 <> 0和expr1 IS NOT NULL),则IF() 返回expr2。否则,它返回expr3. IF(expr1,expr2,expr3)mysql> SELECT IF(1>2,2,3); -> 3 mysql> SELECT IF(1<2,'yes','no'); -> 'yes' mysql> SELECT IF(STRCMP('test','test1'),'no','yes'); -> 'no'ifnull语句
-- 如果expr1不是 NULL, 则IFNULL()返回 expr1;否则返回 expr2。 IFNULL(expr1,expr2)mysql> SELECT IFNULL(1,0); -> 1 mysql> SELECT IFNULL(NULL,10); -> 10 mysql> SELECT IFNULL(1/0,10); -> 10 mysql> SELECT IFNULL(1/0,'yes'); -> 'yes' -- 将学生的年龄+10 select name,age,ifnull(age,0)+10 from db02.student;nullif语句 – 了解
-- Returns NULL if expr1 = expr2 is true, otherwise returns expr1. -- 如果expr1 = expr2,返回null,否则返回expr1 NULLIF(expr1,expr2)mysql> SELECT NULLIF(1,1); -> NULL mysql> SELECT NULLIF(1,2); -> 1
字符串函数
-- 返回字符串的长度(以字节为单位)
select length("java"); -- 4
select length("我"); -- 3
-- char_length(): 返回字符数量
select char_length("java"); -- 4
select char_length("我"); -- 1
-- concat() 返回连接的字符串
select concat(name,province) from student;
-- concat_ws() 返回与分隔符连接
select concat_ws(",",name,province) from student;
-- find_in_set(): 第二个参数中第一个参数的索引(位置)
-- MySQL的索引从1开始
select find_in_set("b","a,b,c,d"); -- 2
-- format(): 返回格式化为指定小数位数的数字
-- format会四舍五入
select format(3.1415926,3); -- 3.142
-- instr() 返回子字符串第一次出现的索引
-- 查找to在"welcome to chengdu"中第一次出现的索引
select instr("welcome to chengdu","to"); -- 9
-- locate() 返回子字符串第一次出现的位置
select locate("to","welcome to chengdu"); -- 9
-- 从位置10开始查找子串的索引
select locate("to","welcome to chengdu",10); -- 0
-- lcase()和lower()相同,返回小写
select lcase("JAVA"); -- java
-- ucase()和upper()一样,返回大写
select ucase("java"); -- JAVA
-- substr(str,pos,len): 返回指定的子字符串
select substr("welcome",1,3); -- wel
select substring("welcome",1,3);-- wel
-- trim():删除前后空格
select trim(" hello ");
select " hello ";日期时间函数
https://dev.mysql.com/doc/refman/5.7/en/date-and-time-functions.html
-- CURRENT_DATE(),CURRENT_DATE,CURDATE():返回当前日期
select current_date();
select current_date;
select curdate();
-- CURRENT_TIME(),CURRENT_TIME,CURTIME():返回当前时间
select current_time();
select concat_ws(" ",current_date(),current_time()) as time;
-- CURRENT_TIMESTAMP(),CURRENT_TIMESTAMP,NOW():返回当前日期时间
select current_timestamp();
select now();
-- ADDDATE(): 将时间值(间隔)添加到日期值
-- 2天后
select adddate(now(),2);
-- 2天前
select adddate(now(),interval -2 day);
-- 2天后
select adddate(now(),interval 2 day);
-- 2年后
select adddate(now(),interval 2 year);
-- 2小时后
select adddate(now(),interval 2 hour);
-- 2分钟后
select adddate(now(),interval 2 minute);
-- ADDTIME(): 添加时间
-- ADDTIME()将expr2添加到expr1并返回结果。
-- 其中,Expr1为时间或datetime表达式,expr2为时间表达式。
select addtime(now(),'2:10');
-- DATE(): 提取日期或日期时间表达式的日期部分
select date(now());
select date(create_time) from student;
-- DATE_ADD() 将时间值(间隔)添加到日期值
-- DATE_SUB():从日期中减去时间值(间隔)
select date_add(now(),interval 2 day);
-- DATE_FORMAT(date,format): 日期格式化
select date_format(now(),"%Y年%m月%d日 %H:%i:%s")
-- DATEDIFF(): 两个日期之差
select datediff(now(),'1990-10-10');
-- DAY(),DAYOFMONTH() 的同义词,返回月中的天
select day(now());
-- DAYNAME() 返回工作日的名称,返回星期的名字
select dayname(now());
-- DAYOFWEEK() 返回参数的工作日索引
-- 周日是第一天
select dayofweek(now());
-- EXTRACT(unit from date):提取日期的一部分
select extract(year from now());
-- QUARTER() 从日期参数返回季度
select quarter(now());转换函数 - 了解
CAST(expr AStype)- *允许的
type*类型- BINARY[(
N)] - CHAR[(
N)] - DATE
- DATETIME[(
M)] - DECIMAL[(
M[,D])] - TIME[(
M)] - SIGNED [INTEGER]
- UNSIGNED [INTEGER]
- BINARY[(
- *允许的
-- cast 转换函数
select locate('0',cast(110 as char));位运算 - 了解
| Name | 描述 |
|---|---|
& |
按位与 |
>> |
右移 |
<< |
左移 |
^ |
按位异或 |
| [` | `](https://dev.mysql.com/doc/refman/5.7/en/bit-functions.html#operator_bitwise-or) |
~ |
位反转 |
加密函数
-- md5加密
select md5(111);
-- password() 计算并返回密码字符串
select password(123456);-- *6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9其他函数
-- INET_ATON():返回 IP 地址的数值
SELECT INET_ATON('10.0.5.9'); -- 167773449
-- INET_NTOA(): 从数值返回 IP 地址
SELECT INET_NTOA(167773449);-- 10.0.5.9信息函数
-- DATABASE() 返回默认(当前)数据库名称
select database();
-- VERSION() 返回一个表示 MySQL 服务器版本的字符串
select version();
-- 使用MySQL命令查看版本
C:\Users\NINGMEI>mysql --version
mysql Ver 14.14 Distrib 5.7.38, for Win64 (x86_64
C:\Users\NINGMEI>mysql -V
mysql Ver 14.14 Distrib 5.7.38, for Win64 (x86_64)
-- USER() 客户端提供的用户名和主机名
select user(); -- root@localhost单行函数的特点
以上所讲的函数都是单行函数,也就是以上的函数会作用在表中每一行数据,一行数据返回一个结果。
单行函数可以在select或where后面
select name,char_length(name) from student;
select name from student where char_length(name) = 3;order by子句
order by … 按照 … 排序
ascend:(默认) 升序
descend: 降序
-- student按照年龄升序
select * from student order by age;
select * from student order by age asc;
-- student按照年龄降序
select * from student order by age desc;
-- student按照年龄升序,sid降序
-- sid降序的前提是年龄相同
select * from student order by age asc , sid desc;limit 子句
-- offset 表示偏移量,跳过多少条数据,省略不写就是0
-- row_count 行数
LIMIT {[offset,] row_count}-- 按照学生的age降序,取出前3条
select * from student order by age desc limit 3;
-- 按照学生的age降序,从第2条开始获取3条数据
select * from student order by age desc limit 1,3;
-- 分页查询
-- 一共8条数据
-- 每页显示3条,分页显示
-- limit (页码 - 1) * 每页需要显示的条数 ,每页需要显示的条数
select * from student order by age desc limit 0,3; -- 第一页
select * from student order by age desc limit 3,3; -- 第二页
select * from student order by age desc limit 6,3; -- 第三页建表的时候自动更新时间
注意: 以后在设计MySQL业务表的时候,无论业务需求中是否要求时间字段,都建议大家设置一个创建时间和更新时间的字段。
-- 创建学生表
create table if not exists student (
_id bigint primary key auto_increment,
sid int unsigned not null unique,
name varchar(12) not null,
age int,
gender char(6) default 'male',
province text,
create_time datetime default now(),
-- on update 表示数据更新的时候,时间也会自动更新 【成倍增长】主键和唯一性不能插入
update_time datetime default now() on update now()
);补充:
-- 复制表结构
create table student01 like student;
-- 复制表结构和数据
create table student02 as select * from student;
-- 将查询得到的数据插入表中
insert into student01 select * from student;
-- insert into ... select 可以做蠕虫复制
insert into test select * from test;group by子句
group by … 按照…分组
-- 按照职位分组
-- 使用分组后,select 后面的投影字段需要使用分组字段,不是分组字段作为投影没有意义
select * from emp group by job;
-- 使用分组字段作为投影字段
select job from emp group by job;
-- 学生按照省份和性别分组
select province,gender from db01.student group by province,gender;
-- 使用分组去重 - 小技巧
-- 分组的目的:是为了数据的统计分析聚合函数(多行函数/分组函数) - aggregate-functions
- count(字段)/count(常量值)/count(*): 返回返回的行数
-- 统计员工的总人数
-- count(*) 不会忽略null值
select count(*) as num from emp;
-- count(常量值) 不会忽略null值
select count(0) as num from emp;
-- count(字段) 会忽略指定字段的null值
select count(mgr) as num from emp;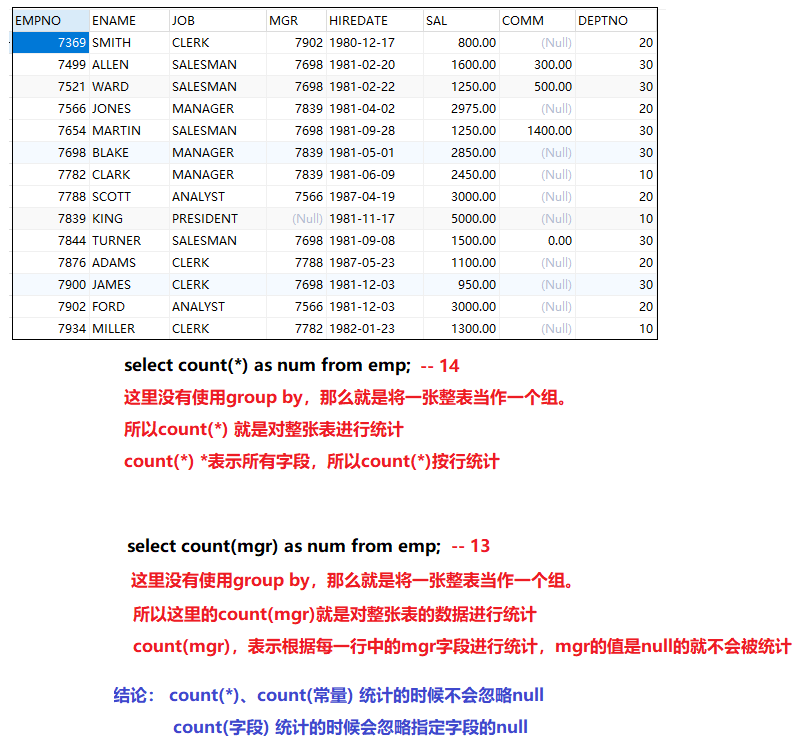
sum(字段):返回总和
max(): 返回最大值
min(): 返回最小值
avg():返回参数的平均值
group_concat():返回一个连接的字符串
GROUP_CONCAT([DISTINCT] expr [,expr ...] [ORDER BY {unsigned_integer | col_name | expr} [ASC | DESC] [,col_name ...]] [SEPARATOR str_val])-- 统计每种职位的工资总额 select job,sum(sal) from emp group by job; -- 统计每种职位的平均工资 select job,format(avg(sal),2) from emp group by job; -- 统计每种职位的平均工资 select job,sum(sal)/count(sal) from emp group by job; -- 统计每种职位的最高工资 select job,max(sal) from emp group by job; -- 统计每种职位的最低工资 select job,min(sal) from emp group by job; -- 统计每种职位的所有工资 select job,group_concat(sal order by sal desc separator ',') from emp group by job;聚合函数的特点
- 聚合多行数据得到一个结果
- 聚合函数不能使用在where后面,只能用在select和having后面
having 子句
-- 查询人数超过2人的职位有哪些 select job,count(*) as sum from emp group by job having sum > 2; -- 过滤原始数据再进入内存 select * from emp where sal > 1000; -- 进入内存再过滤 select * from emp having sal > 1000;where 和 having的区别
- where过滤的是原始数据;having过滤的是内存数据
- where能做的having都能做;反之不成立。但是能用where的优先使用where,可以减少加载到内存的数据
- where后面不能使用别名和聚合函数;having可以
连接查询(多表查询)- SQL92
内连接
笛卡尔积:表1有m条数据,表2有n条数据,笛卡尔积就是用表1的每一条数据匹配表2中的所有数据,结果就是m*n条数据
自连接:就是一张表当成两张表使用
-- 查询员工及其领导 select e1.ename,e2.ename from emp as e1,emp as e2 -- 连接条件 where e1.mgr = e2.empno;等值连接:连接条件使用=
-- 查询员工和部门名称 select e.ename,d.dname from emp e , dept d where e.deptno = d.deptno;不等值连接:连接条件没有使用=
-- 查询员工的工资等级 select e.ename,e.sal,s.grade from emp e, salgrade s where e.sal between s.losal and s.hisal; -- 查询员工和部门名称、工资等级 -- 连接条件的数量 = 连接的表数量 - 1 select e.ename,e.sal,d.dname,s.grade from emp e,dept d, salgrade s where e.deptno = d.deptno and e.sal between s.losal and s.hisal; -- 查询工资大于1000的员工和部门名称、工资等级 select e.ename,e.sal,d.dname,s.grade from emp e,dept d, salgrade s -- 过滤条件 where e.sal > 1000 -- 连接条件 and e.deptno = d.deptno and e.sal between s.losal and s.hisal;
内连接的特点
- 只会返回匹配成功的数据,没有匹配上的数据不显示
SQL92语法将连接条件放在where中,但是where还有过滤原始数据的功能,所以代码耦合了。所以出现了sql99语法,在SQL99中将连接条件独立出来了。
连接查询(多表查询)- SQL99
内连接 - inner join
-- 查询员工及其领导 -- 自连接
select e1.ename as emp,e2.ename as leader
from emp e1 join emp e2
on e1.mgr = e2.empno;
-- 查询员工和部门名称 -- 等值连接
-- inner可以省略
select e.ename,d.dname
from emp e inner join dept d
on e.deptno = d.deptno;
-- 查询工资大于1000的员工和部门名称、工资等级
select e.ename,e.sal,d.dname,s.grade
from emp e join dept d
-- 连接条件
on e.deptno = d.deptno
join salgrade s
-- 连接条件
on e.sal between s.losal and s.hisal
-- 过滤条件
-- where后可以使用表的别名,不能使用字段别名
where e.sal > 1000 ;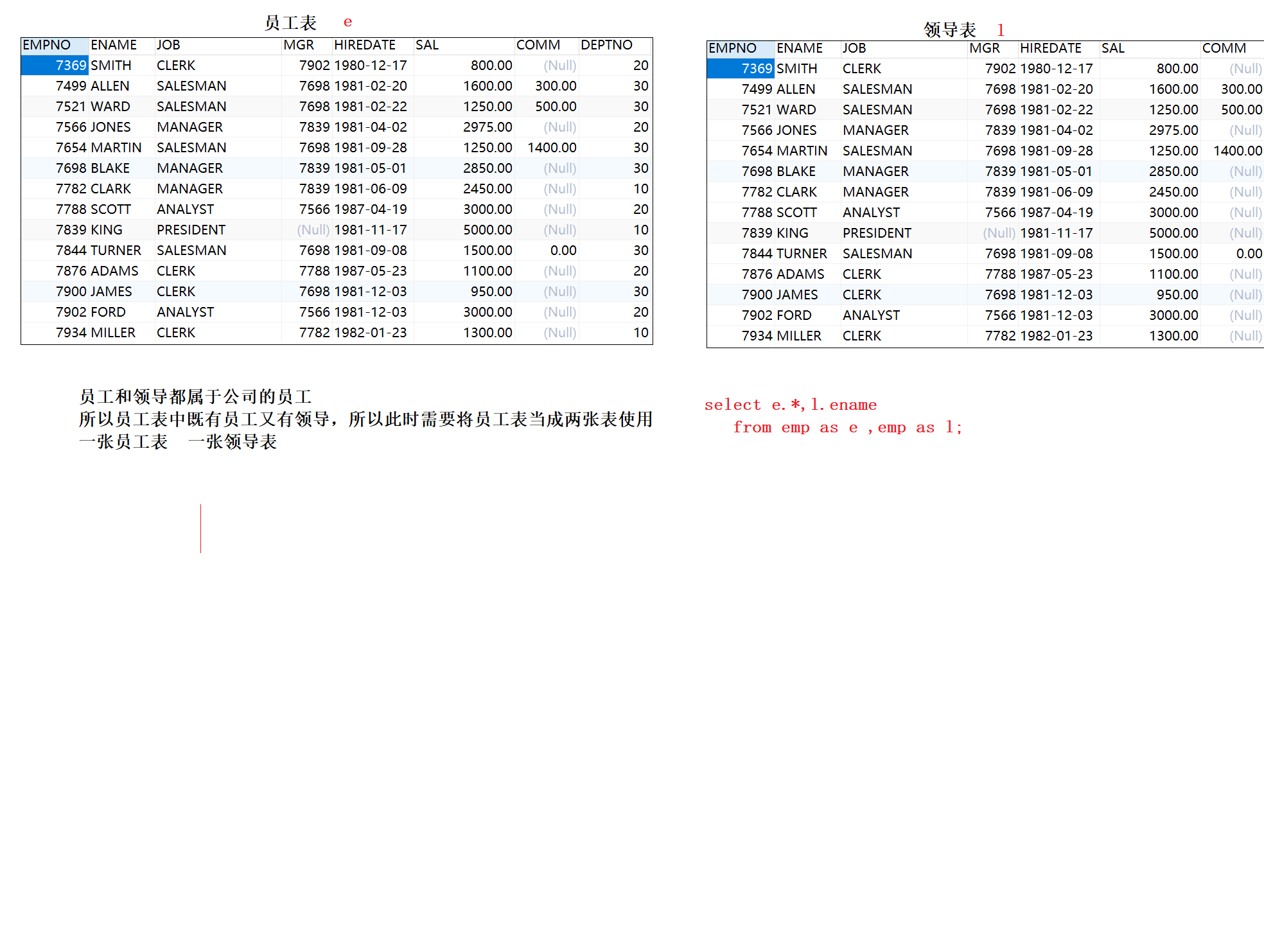
内连接:只会返回匹配成功的数据,没有匹配上的数据不显示
外连接 - outer join
外连接区分主表和从表
特点:主表的数据无论匹配是否成功都会显示,从表的数据匹配成功就显示数据,否则就是null
left join 左边的表就是主表,右边的表就是从表
right join 右边的表就是主表,左边的表就是从表
所以基于以上的规则:left join 和 right join 通过交换主从表的关系可以达到一样的效果
左外连接 - left join
右外连接 – right join
-- 查询所有员工及其领导,没有领导的员工也要显示
select e1.ename,e2.ename
-- e1是主表,e2是从表
from emp e1 left join emp e2
on e1.mgr = e2.empno;
select e1.ename,e2.ename
-- e1是主表,e2是从表
from emp e2 right join emp e1
on e1.mgr = e2.empno;
-- 查询工资大于1000的员工和部门名称、工资等级
select e.ename,e.sal,d.dname,s.grade
from emp e left join dept d
-- 连接条件
on e.deptno = d.deptno
left join salgrade s
-- 连接条件
on e.sal between s.losal and s.hisal
-- 过滤条件
where e.sal > 1000 ;交叉连接、自然连接、using子句
-- 交叉连接:查询出来的结果是两张表中数据的乘积
-- 交叉连接也是内连接
select e.*,d.*
from emp e
cross join dept d
on e.deptno = d.deptno;
-- 自然连接
-- Natural join基于两个表中的全部同名列建立连接
-- 弊端:连接条件不灵活
select e.*,d.*
from emp e natural join dept d;
-- using子句
-- 如果连接条件的字段名一样,可以使用using子句
select e.ename,d.dname
from emp e inner join dept d
using(deptno);
select e.ename,d.dname
from emp e inner join dept d
on e.deptno = d.deptno;子查询
子查询:就是其他语句中包含的select语句
注意:
1.子查询必须写在()内
2.子查询在from后面当作表使用,必须有别名
单行子查询
-- 查得所有比“CLARK”工资高的员工的信息
-- 1. 查询“CLARK”工资
select sal from emp where ename = 'CLARK';
-- 2. 查询所有员工的工资和1中的结果比较
select ename,sal from emp where sal > (select sal from emp where ename = 'CLARK');
-- 查询工资最高的雇员名字和工资。
-- 1. 查询最高工资
select max(sal) from emp;
-- 2. 查询所有员工的工资等于1的结果
select * from emp where sal = (select max(sal) from emp);
-- 查询职务和SCOTT相同,比SCOTT雇佣时间早的雇员信息
-- 1. 查询出SCOTT的职务
select job from emp where ename = "SCOTT";
-- 2. 查询出SCOTT的雇佣时间
select hiredate from emp where ename = "SCOTT";
-- 3. 查询所有员工职务等于1的结果,雇佣时间小于2的结果
select * from emp where job = (select job from emp where ename = "SCOTT")
and hiredate < (select hiredate from emp where ename = "SCOTT");多行子查询
多行子查询返回多行记录
对多行子查询只能使用多行记录比较运算符
ALL 和子查询返回的所有值比较
ANY 和子查询返回的任意一个值比较; SOME是ANY的别名
IN 等于列表中的任何一个
-- 查询工资低于任意一个'CLERK'的工资的雇员信息。
-- 1. 查询出所有'CLERK'的工资
select sal from emp where job = 'CLERK';
-- 2. 查询所有员工的工资低于1中任意一个值
select * from emp where sal <any (select sal from emp where job = 'CLERK');
-- 查询工资低于任意一个'CLERK'的工资的雇员信息。
select * from emp where sal < (select max(sal) from emp where job = 'CLERK');
-- 查询工资比所有的 'SALESMAN'都高的雇员的编号、名字和工资。
-- 1. 查询出所有'SALESMAN'的工资
select sal from emp where job = 'SALESMAN';
-- 2. 查询所有员工的工资高于1中所有值
select * from emp where sal >all(select sal from emp where job = 'SALESMAN');
-- 查询部门20中职务同部门10的雇员一样的雇员信息。
-- 1.查询部门10中职务有哪些
select job from emp where deptno = 10;
-- 2.查询部门20中职务在1的结果中的
select * from emp where deptno = 20 and job in (select job from emp where deptno = 10);
-- 查询在雇员中有哪些人是领导
-- 1. 查询出领导的员工编号
select mgr from emp;
-- 2. 查询员工的编号在1的结果中的
select * from emp where empno in (select mgr from emp);
-- 找出部门编号为20的所有员工中收入最高的职员
-- 1. 查询部门编号为20的所有员工最高工资
select max(sal) from emp where deptno = 20;
-- 2. 查询部门编号为20的所有员工工资等于1的结果的
select * from emp where deptno = 20 and sal = (select max(sal) from emp where deptno = 20);
-- 找出部门编号为20的所有员工中收入最高的职员
select * from emp
where sal >= all(
select sal from emp where deptno = 20)
and deptno = 20
-- 查询每个部门平均薪水的等级
-- 1. 查询每个部门平均薪水
select avg(sal) from emp group by deptno;
-- 2. 将1的结果和工资等级进行连接查询
select e.avg,s.grade
-- 子查询在from后面当作表使用,必须有别名
from (select avg(sal) as avg from emp group by deptno) e
join salgrade s
on e.avg between s.losal and s.hisal;相关子查询
-- exists(select语句): 相关子查询
-- 外部的查询是否返回数据取决于 select子查询语句
-- select子查询语句有结果,外部查询就会执行返回结果;否则外部查询没有返回结果
-- 最终的结果只有外部查询的,内部查询的结果是不会显示的。
-- 内部查询在这里仅仅是一个开关
select * from emp where exists (select * from emp where sal > 10000);联合查询
将多个select语句联合(合并)为一个select语句,涉及的关键字union 和union all。
union all 不管是否重复,全部合并
union 如果有重复的,过滤掉重复的
-- 将两个select的结果组成一张虚拟表
select * from emp where sal > 1000
union all
select * from emp where job = 'SALESMAN';
-- 将两个select的结果组成一张虚拟表,相同的数据去重
select * from emp where sal > 1000
union
select * from emp where job = 'SALESMAN';视图 - View
视图是从若干基本表和(或)其他视图构造出来的表。也就是说视图也是表,是一张虚拟表。
操作视图的数据其实还是操作的是基本表的数据
创建视图
CREATE
[OR REPLACE]
VIEW view_name [(column_list)]
AS select_statement-- 创建视图
create view emp_view as select empno,ename,job,mgr,hiredate,deptno from emp;
-- 如果不存在就创建;存在就替换
create or replace view emp_view as select empno,ename,job,mgr,deptno from emp;
-- 操作视图其实操作的是原始数据
update emp_view set job = "SALESMAN" where ename ="smith";
delete from emp where ename ="smith";
-- 聚合函数生成的视图不能增加、删除、修改数据
create or replace view emp_view01 as select max(sal) as max_sal from emp;
update emp_view01 set max_sal = 10000;
delete from emp_view01;
insert into emp_view01 values(10000);
-- 删除视图
drop view emp_view01;
-- 查询当前所有的数据库
show databases;
-- 查询当前库下的所有表
show tables;
-- 查询所有表及其类型
show full tables;
-- 查询指定数据库的所有表
show tables from db01;视图的总结
视图对应一个查询语句;视图是(从若干基本表和(或)其他视图构造出来的)表
视图进行查询,添加,修改,删除,其实就是对背后的表进行相应操作
视图是虚拟表,在创建一个视图时,只是存放的视图的定义,也即是动态检索数据的查询语句,而并不存放视图对应的数据
视图的好处
- 安全 可以只显示部分行部分列的数据;可以对添加的数据进行检查;可以设置为只读视图
- 操作简单
- 只显示多个数据库表的部分列,部分行的视图
- 聚合函数生成的视图不能增加、删除、修改数据
存储引擎
SHOW ENGINES;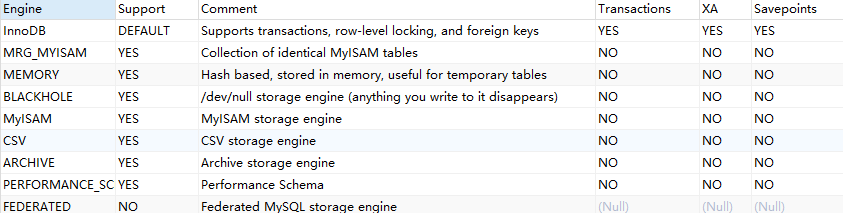
Innodb支持事务和外键;MyISAM不支持事务和外键
MySQL事务 - transaction
事务:完成一个事情需要的一系列步骤(操作),这些操作要么同时成功,要么同时失败
在MySQL中DML一条语句就是一个事务,且事务自动提交的。
在实际开发中有时候我们需要将多条语句变成一个整体,他们要么都成功,要么都是失败。此时就需要将多条语句做成一个事务。
事务的基本操作
1 开启事务
start transaction;2 提交事务
commit;3 回滚事务
rollback;注意:一旦使用start transaction;开启事务那么自动提交将失效
如果所有操作都正常执行使用commit;提交事务
当发生异常情况回滚事务,数据(此时为tb_account表)通常回滚到开启事务之前的状态
无论提交还是回滚事务,事务都会结束。
转账案例
-- 张三给李四转100元
-- 开启事务
start transaction;
update account set money = money - 100 where name = 'zhangsan';
update account set money = money + 100 where name = 'lisi';
commit; -- 提交事务,事务结束
rollback; -- 回滚事务,事务结束事务是用来控制DML语句的。DQL不会修改原始数据,所以DQL不需要事务。
事务的ACID四大特性
原子性(Atomicity): 事务中的语句不可再分,是一个整体。要么同时成功,要么同时失败
一致性(Consistency): 事务执行前和事务执行后数据是一致的。比如转帐前总计金额是1300;转账后总计金额是1300
隔离性(Isolation): 事务之间是彼此隔离的,一个事务的操作不会影响另一个事务。但是隔离性受隔离级别的影响。
持久性(Durability):事务一旦提交就会将数据写入文件持久化存储。
事务的隔离级别 - 理解
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 读已提交(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
- 读未提交(read-uncommitted)
- 事务1修改了数据但是还没有提交,此时事务2就读取到了事务1还没有提交的数据。
- 会产生脏读。解决办法:提升隔离级别
- 读已提交(read-committed)
- 开启事务1和事务2,事务1和事务2读取到了表中原来的数据,此时事务1修改了表中的数据,并提交事务。事务2在同一次事务中读到了不同的数据。
- 解决了脏读,但是出现了不可重复读
- 不可重复读: 就是在同一次事务中读取到的数据不相同
- 如何解决不可重复读:提升隔离级别
- 可重复读(repeatable-read)
- 开启事务1和事务2,无论事务1是否提交事务,事务2读取到的数据都是一样.
- 解决了不可重复读, 但是出现了幻读
- 解决幻读。解决办法:提升隔离级别
- 串行化(serializable)
- 事务加锁了,事务只能串行执行了.
- 安全性最高,效率最低
MySQL默认的隔离级别是可重复读(repeatable-read)
查询隔离级别
select @@tx_isolation;设置隔离级别
set session transaction isolation level READ UNCOMMITTED; set session transaction isolation level READ COMMITTED; set session transaction isolation level REPEATABLE READ; set session transaction isolation level serializable;
数据库设计原则 - 三范式
概念(NF= NormalForm)
遵循一定的规则。在关系型数据库中这种规则就称为范式
三范式的作用
- 结构合理
- 冗余较小
缺点
性能降低
多表查询比单表查询速度慢
第一范式
必须要有主键,字段不可再分

以上的表就不满足第一范式,虽然有主键,但是address可以再分。修改如下:

第二范式
在第一范式的基础上,需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。
(非主键字段必须全部依赖主键字段,而不能部分依赖)
学号和课程编号作为联合主键
课程名称只依赖于课程编号,而和学号没有关系
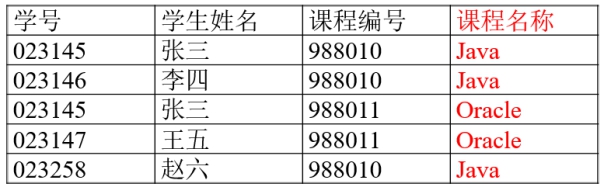
分析以上的设计发现数据冗余。学生只依赖主键中的学号;课程名称只依赖主键中的课程编号。违背第二范式。修改如下:
学生表
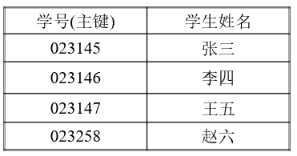
2,课程表
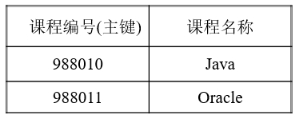
3,选课表
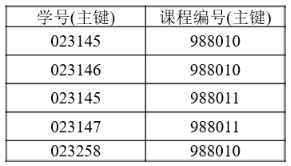
第三范式
在第二范式的基础上,确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
(非主键字段必须直接依赖主键字段,不能间接依赖)
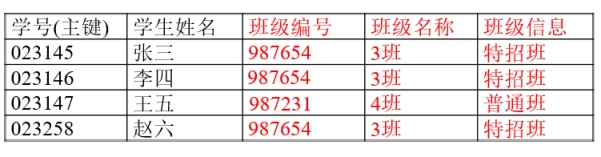
以上数据冗余。班级名称和班级信息直接依赖班级编号,班级编号直接依赖主键学号,所以班级名称和班级信息间接依赖了主键学号。所以违背了第三范式。
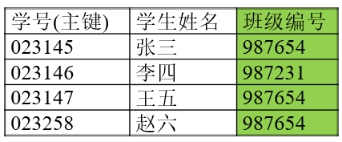
修改如下:
学生表
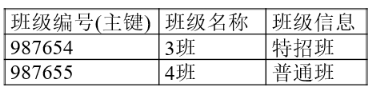
班级表
MySQL用户管理和权限
在MySQL中用户的唯一标识是:
'用户名'@'主机名'用户名:就是创建的用户的名字
主机名:指定该用户在哪个主机上可以登陆。localhost表示该用户只能在本机登录。如果想让该用户可以从任意远程主机登陆,可以使用通配符%
创建用户
CREATE USER [IF NOT EXISTS]
user [auth_option] [, user [auth_option]] ...
[password_option | lock_option] ...
auth_option: {
IDENTIFIED BY 'auth_string'
| IDENTIFIED WITH auth_plugin
| IDENTIFIED WITH auth_plugin BY 'auth_string'
| IDENTIFIED WITH auth_plugin AS 'auth_string'
| IDENTIFIED BY PASSWORD 'auth_string'
}
password_option: {
PASSWORD EXPIRE
| PASSWORD EXPIRE DEFAULT
| PASSWORD EXPIRE NEVER
| PASSWORD EXPIRE INTERVAL N DAY
}-- 创建zhangsan用户
-- 'zhangsan'@'localhost' 表示张三只能在本地连接数据库
create user 'zhangsan'@'localhost' identified by '123456';
-- 'zhangsan'@'%' 表示张三只能在任意的主机上远程连接数据库
-- 无主机登录
create user 'zhangsan'@'%' identified by '123456';
-- 刷新权限
flush privileges;修改用户
ALTER USER [IF EXISTS]
user [auth_option] [, user [auth_option]] ...
ALTER USER [IF EXISTS]
USER() IDENTIFIED BY 'auth_string'
auth_option: {
IDENTIFIED BY 'auth_string'
| IDENTIFIED WITH auth_plugin
| IDENTIFIED WITH auth_plugin BY 'auth_string'
| IDENTIFIED WITH auth_plugin AS 'auth_string'
}-- 修改用户的密码
alter user 'zhangsan'@'%' identified by '234567';
-- 刷新权限
flush privileges;删除用户
DROP USER [IF EXISTS] user [, user] ...-- 删除用户
drop user 'zhangsan'@'%';
-- 刷新权限
flush privileges;授权
GRANT
priv_type [(column_list)]
[, priv_type [(column_list)]] ...
ON priv_level
TO user [auth_option] [, user [auth_option]] ...
priv_level: {
*.*
| db_name.*
| db_name.tbl_name
}
auth_option: {
IDENTIFIED BY 'auth_string'
| IDENTIFIED WITH auth_plugin
| IDENTIFIED WITH auth_plugin BY 'auth_string'
| IDENTIFIED WITH auth_plugin AS 'auth_string'
| IDENTIFIED BY PASSWORD 'auth_string'
}-- 授权
-- 给用户'zhangsan'@'%'授予所有库下所有被的所有操作权限
grant all on *.* to 'zhangsan'@'%' identified by '234567';
-- 刷新权限
flush privileges;取消授权
REVOKE
priv_type [(column_list)]
[, priv_type [(column_list)]] ...
ON [object_type] priv_level
FROM user [, user] ...-- 取消授权
revoke all on *.* from 'zhangsan'@'%' ;
-- 刷新权限
flush privileges;MySQL索引
索引(index): MySQL存储引擎为了提高查询效率而设计的一种数据结构。
索引相当于 字典中的索引目录。
索引的分类
主键索引:primary key
唯一索引: unique
普通索引(单列索引,单值索引): 就是给一个字段添加索引
CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX index_name ON tbl_name (key_part,...) [index_option] [algorithm_option | lock_option] ... key_part: col_name [(length)] [ASC | DESC]-- 创建表的时候,创建索引 create table test01( id int primary key, name char(10), age tinyint unsigned, gender char(6), -- 创建普通索引 key(name) ); -- 表已经存在,创建索引 -- 给test表的name字段创建索引 create index index_name on test (name);复合索引:多个字段联合作为索引字段
create table test02( id int primary key, name char(10), age tinyint unsigned, address char(10), gender char(6), -- 创建复合索引 key(name,age,address) ); insert into test02 values(1,'zhangsan',20,'beijing','male'); insert into test02 values(5,'lisi',21,'tianjin','male'); insert into test02 values(2,'wangwu',22,'beijing','male'); insert into test02 values(4,'zhaosi',20,'shanghai','male'); insert into test02 values(3,'lily',23,'chengdu','female'); -- 复合索引原则: -- 最左前缀匹配 -- MySQL为了更好的使用索引,所以在使用索引字段的时候会调整顺序 explain select * from test02 where name = 'lisi'; -- ok explain select * from test02 where name = 'lisi' and age = 22; -- ok explain select * from test02 where name = 'lisi' and age = 22 and address = 'chengdu'; -- ok explain select * from test02 where name = 'lisi' and address = 'chengdu'; -- ok explain select * from test02 where name = 'lisi' and address = 'chengdu' and age = 22; -- ok explain select * from test02 where address = 'chengdu' and name = 'lisi' and age = 22 ; -- ok explain select * from test02 where age = 22 and address = 'chengdu' and name = 'lisi'; -- 因为没有使用最左的索引字段,所以索引失效 explain select * from test02 where age = 22 and address = 'chengdu'; -- not ok -- % 开头索引会失效 explain select * from test02 where name like '%lisi' and address = 'chengdu'; -- not ok -- _ 开头索引会失效 explain select * from test02 where name like '_lisi' and address = 'chengdu'; -- not ok全文索引(MySQL的全文索引基本不用)- 了解
删除索引
DROP INDEX index_name ON tbl_name索引的优缺点
优点
- 提升了查询效率
- 减少了磁盘的IO
缺点
- 增加了磁盘空间
- 降低了DML语句的效率。因为增加、删除、修改数据都会影响索引文件的变动。Innodb中的索引使用B+Tree的数据结构,索引数据发生变化后,B+Tree为了保证平衡,会进行树的自旋转,所以会影响性能。
创建索引的注意点
- 经常更新的数据不宜使用索引。
- 值范围太小的字段不宜使用索引。比如:性别字段
- Blob和Text字段不使用索引
- 数据量低于1000 行数据不建议使用索引
- 经常出现在where中的字段推荐使用索引
- 经常出现在group by中的字段推荐使用索引
- 经常出现在order by中的字段推荐使用索引

